Ollama 简介
Ollama 官网地址:https://ollama.com
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
特点与优势
部署便捷:无需手动安装 PyTorch、CUDA 等复杂依赖,通过命令行直接加载模型,如ollama run llama2,可自动完成环境配置与模型下载。模型以容器化方式管理,支持 “拉取 - 运行” 模式,降低了技术门槛,新手也能快速进行实验。
模型支持广泛:支持 Llama 2/3、Mistral、Gemma、Phi-3、Code Llama 等多种主流开源模型,覆盖通用对话、代码生成、领域微调等多个场景。还支持同一模型的多版本切换,如llama3:8b与llama3:70b,避免环境冲突。
显存优化:提供 4 - bit、8 - bit 等量化版本,显著降低显存占用,例如 70B 模型从 140GB 降至约 20GB,使消费级显卡如 RTX 3090 也能运行大模型。
接口丰富:提供 HTTP 接口(默认端口 11434),可轻松对接外部应用或脚本,实现自动化交互。官方还提供 Python、JavaScript 等语言的客户端库,方便集成到现有项目中,也可结合 LangChain、LlamaIndex 等框架构建复杂应用。
数据隐私保护:数据完全在本地处理,符合 GDPR 等隐私法规,适合对数据隐私有较高要求的用户。单机运行避免了 API 调用成本,还支持离线调试。
多系统支持:原生支持 macOS 和 Linux,2024 年起推出 Windows 实验版(需 WSL 或 Docker)。
核心功能
兼容 OpenAI API:Ollama 提供与 OpenAI API 格式兼容的 REST API 端点,包括聊天补全接口(/v1/chat/completions)、嵌入接口(/v1/embeddings)、模型列表查询(/v1/models)等。开发者无需修改现有基于 OpenAI 的代码,只需调整 API Base URL 和 API Key(占位符即可),即可将请求转发到本地 Ollama 服务,且兼容大部分 OpenAI API 参数。
可与 LangChain 集成:Ollama 可与 LangChain 集成,以增强其功能。例如,通过 LangChain 的文档加载器和向量化检索(RAG)功能,可以集成外部数据源;利用记忆模块可以维护对话历史和长期记忆;借助 Agent、工具链和条件分支可以实现多步骤任务的分解与自动化执行;通过 Tool 接口和自定义函数能够调用外部 API、代码解释器、搜索引擎等工具;使用 Pydantic 输出解析器可以将输出格式化为 JSON、表格等结构化数据。
AI广告位
Ollama 安装
访问 https://ollama.com/download 地址,根据自己系统需要,下载安装包,如下图:
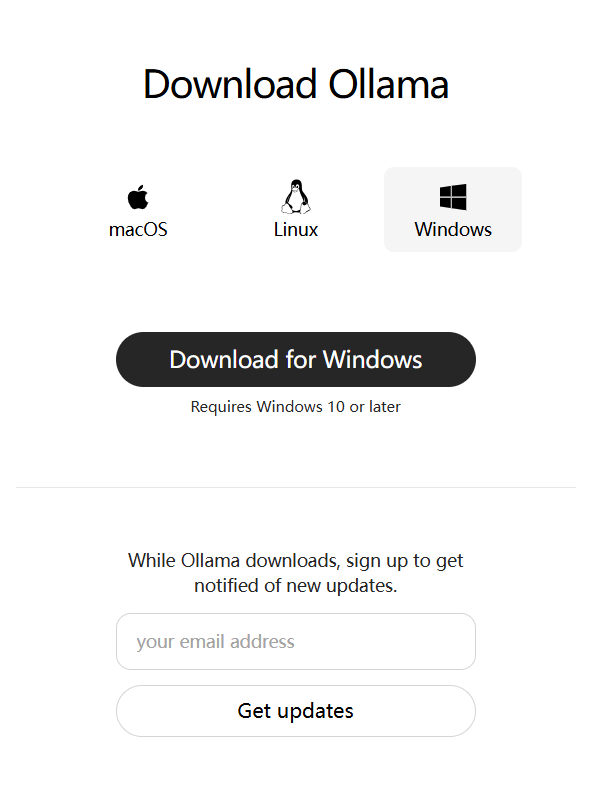
注意,笔者下载 Windows 版本的 Ollama 安装包(如果下载不下来,请科学魔化上网)。双击 OllamaSetup.exe 安装包,开始安装,如下图:
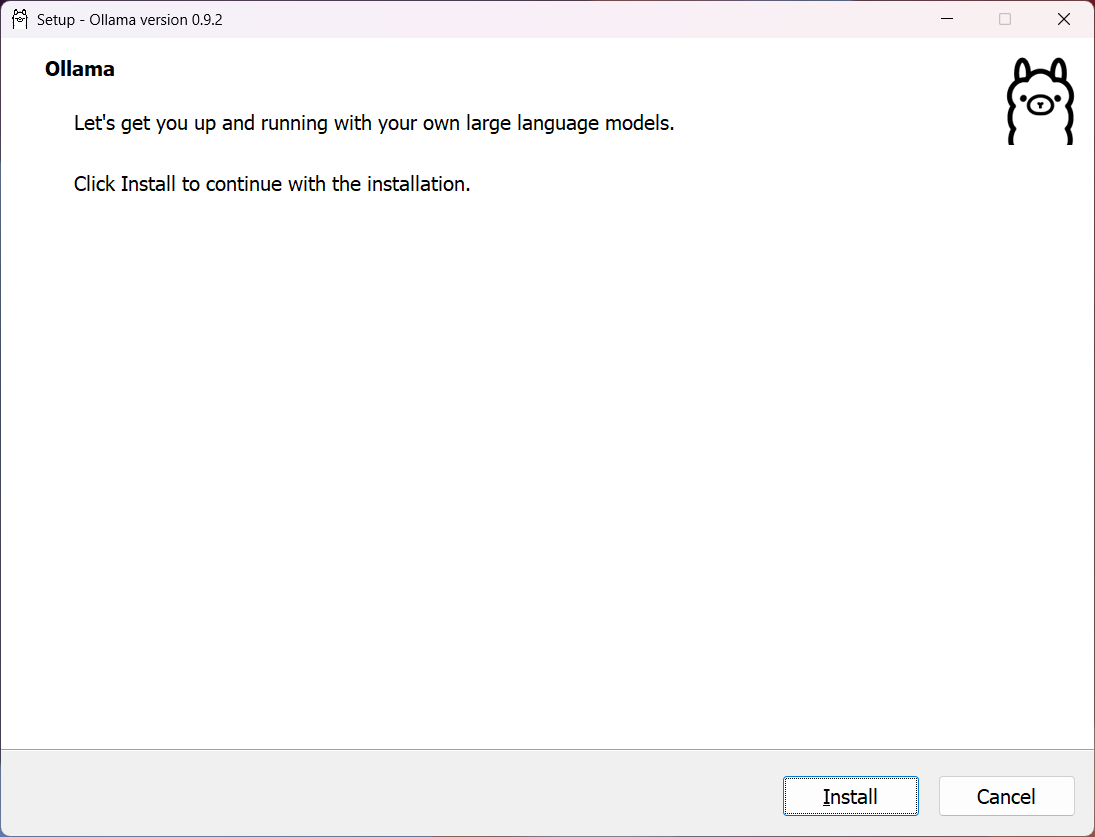
点击“Install”按钮开始安装。
验证&使用
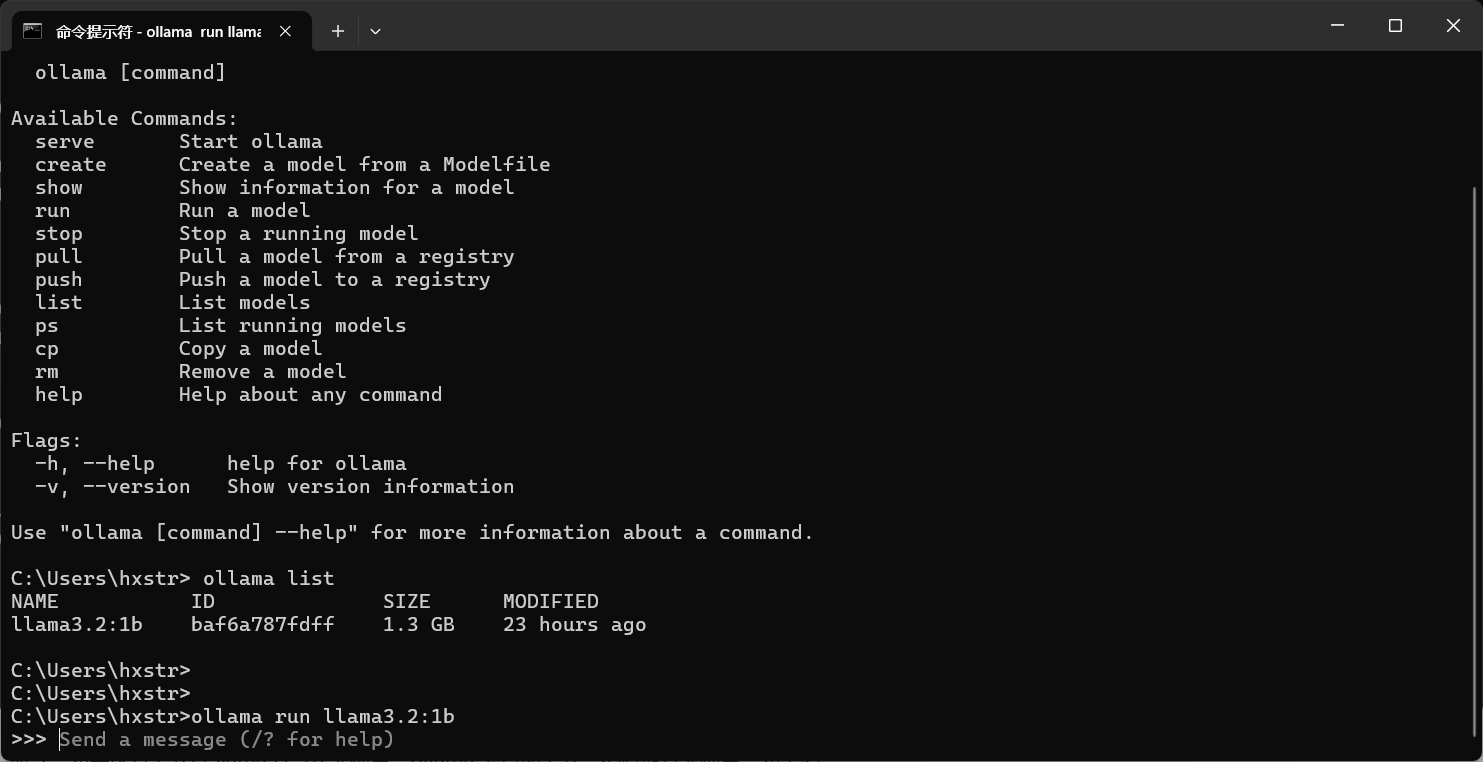
安装完成后,打开 CMD 命令提示符,在 CMD 中输入 ollama 命令查看帮助信息,如下图:
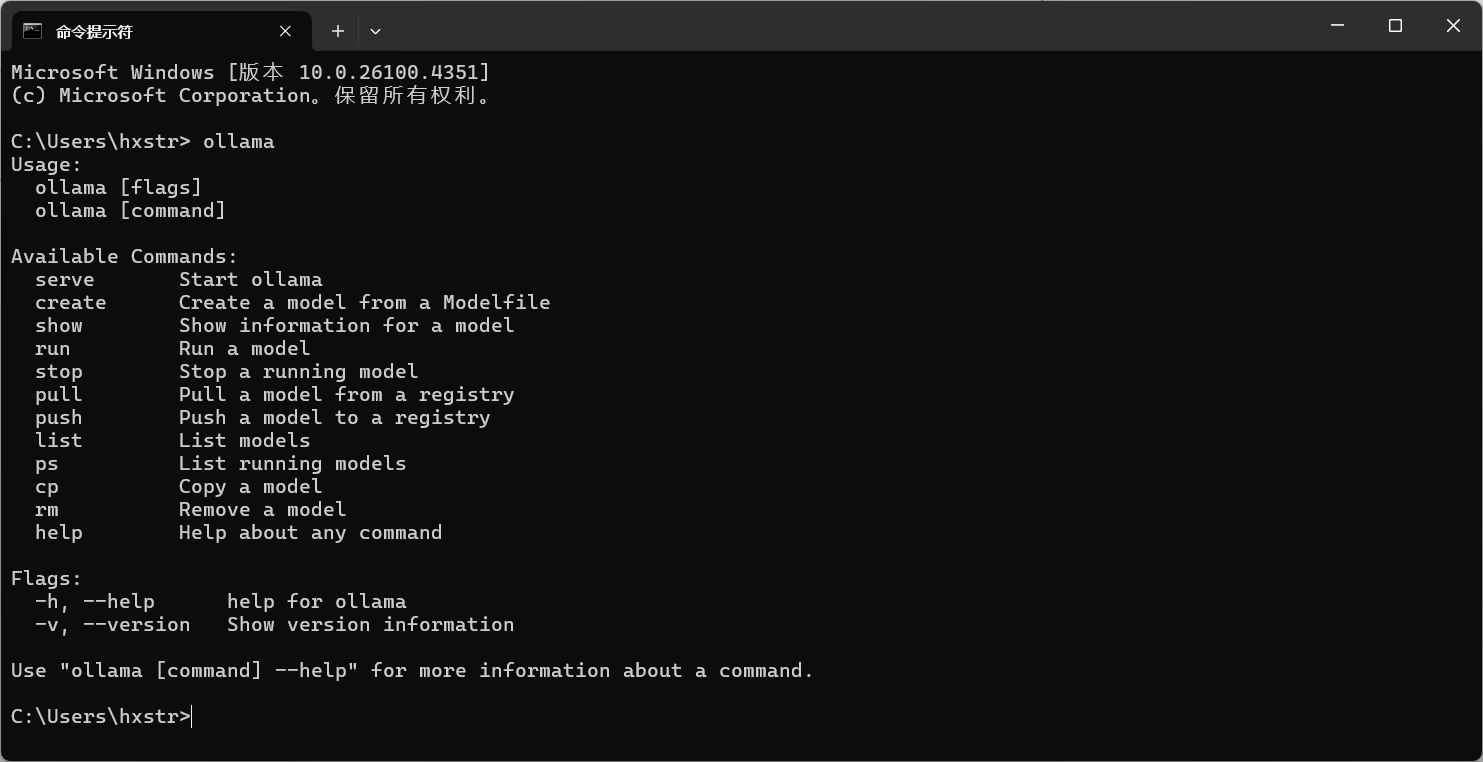
继续执行“ollama run llama3.2:1b”命令(访问查看更多的大模型 https://ollama.com/search),如果没有下载过 llama3.2:1b 大模型,ollama 会自动下载,然后运行大模型,如下图:
下面是下载 deepseek-r1 大模型的截图:
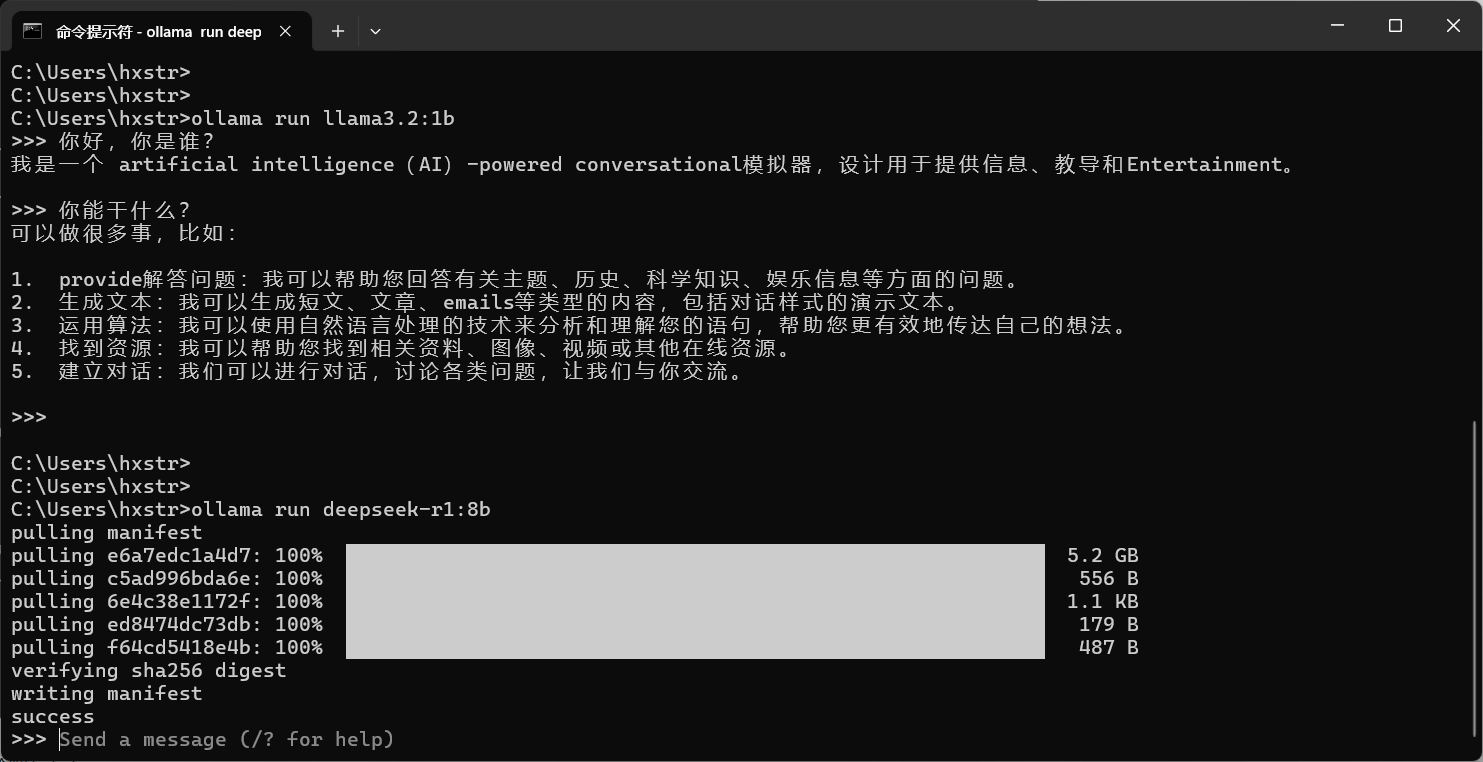
注意,笔者这里 llama3.2:1b 大模型已经下载好了,运行成功,此时我们发送消息:
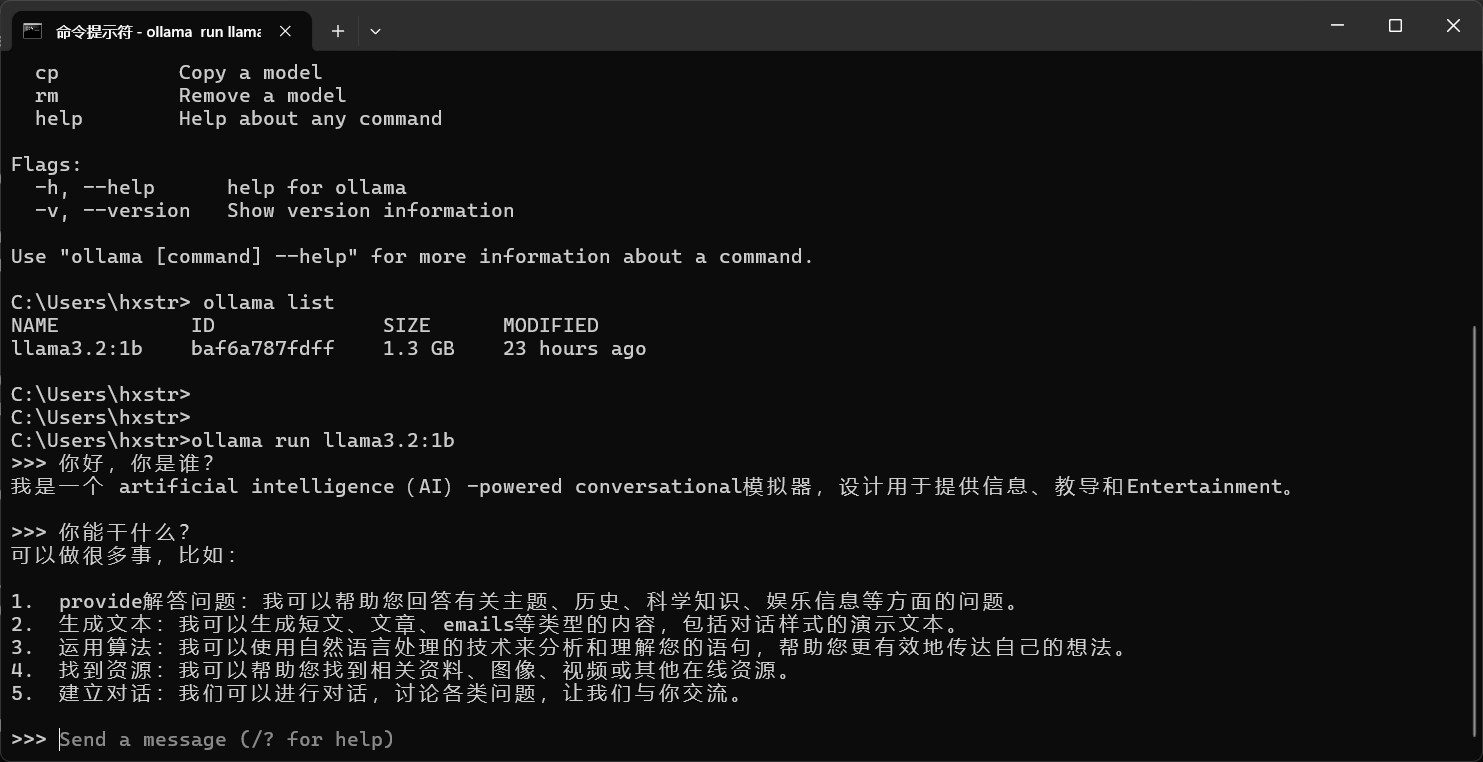
到这里,在本地使用 Ollama 运行模型就成功了,快去体验吧!!!
我们一定要给自己提出这样的任务:第一,学习,第二是学习,第三还是学习。 —— 列宁






 川公网安备51010802032098
川公网安备51010802032098