最近在看Guava中的Cache的源码,它的实现基于ConcurrentHashMap,前段时间组里招人,据说很多看起来很牛掰的简历,一个HashMap就能刷掉很多,所以顺便把HashMap和ConcurrentHashMap的源码复习一遍。
最近在看Guava中的Cache的源码,它的实现基于ConcurrentHashMap,前段时间组里招人,据说很多看起来很牛掰的简历,一个HashMap就能刷掉很多,所以顺便把HashMap和ConcurrentHashMap的源码复习一遍。先从HashMap开始(另:Hashtable是HashMap的线程安全版本,它的实现和HashMap实现基本一致,除了它不能包含null值的key和value,并且它在计算hash值和数组索引值的方式要稍微简单一些。对于线程安全的实现,Hashtable简单的将所有操作都标记成synchronized,即对当前实例的锁,这样容易引起一些性能问题,所以目前一般使用性能更好的ConcurrentHashMap)。
Map是对键值对存储的抽象,因而其最主要的方法有:
1、添加新的键值对(key,value);
2、通过键(key)查找关联的值(value);
3、通过键(key)移除关联的值(value);
4、判断键(key)或值(value)的存在性。
其他的方法有:判断键值对的空属性以及目前的键值对数,获取所有键、所有值或者所有键值对的集合,批量添加,清除所有键值对等。在Map中,一个键值对用Entry接口来表示。因而在Java中,对Map接口的定义如下:
public interface Map<K,V> {
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
boolean equals(Object o);
int hashCode();
}
HashMap是哈希表对Map非线程安全版本的实现,它允许key为null,也允许value为null。所谓哈希表就是通过一个哈希函数计算出一个key的哈希值,然后使用该哈希值定位对应的value所在的位置;如果出现哈希值冲突(多个key产生相同的哈希值),则采用一定的冲突处理方法定位到正真value位置,然后返回查找到的value值。一般哈希表内部使用一个数组实现,使用哈希函数计算出key对应数组中的位置,然后使用处理冲突法找到真正的value,并返回。因而实现哈希表最主要的问题在于选择哈希函数和冲突处理方法,好的哈希函数能使数据分布更加零散,从而减少冲突的可能性,而好的冲突处理方法能使冲突处理更快,尽量让数据分布更加零散,从而不会影响将来的冲突处理方法。
java广告位
在严蔚敏、吴伟明版本的《数据结构(C语言版)》中提供的哈希函数有:
1、直接定址法(线性函数法);
2、数字分析法;
3、平方取中法;
4、折叠法;
5、除留余数法;
6、随机数法。
在JDK的HashMap中采用了移位异或法后除留余数(和2的n次方'&'操作)。HashMap内部的数据结构是一个Entry<K, V>的数组,在使用key查找value时,先使用key实例计算hash值,然后对计算出的hash值做各种移位和异或操作,然后取其数组的最大索引值的余数('&'操作,一般其容量值都是2的倍数,因而可以认为是除留余数)。在JDK 1.7中对String类型采用了内部hash算法(当数组容量超过一定的阀值,使用“jdk.map.althashing.threshold”设置该阀值,默认为Integer.MAX_VALUE,即关闭该功能),并且使用了一个hashSeed作为初始值,不了解这些算法的具体缘由,就这样浅尝辄止了。
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
同样在上述的数据结构书中关于冲突处理提供了几个方法:
1、开放定址法;
2、再哈希法;
3、链地址法;
4、建立一个公共溢出区法。
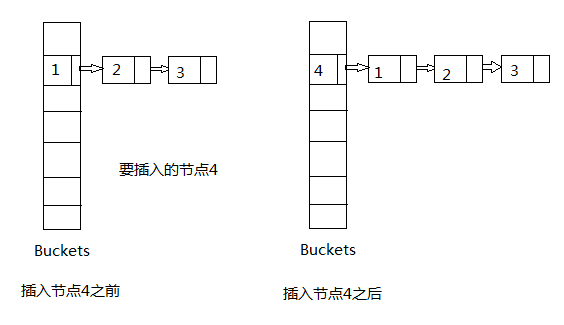
在JDK的HashMap中采用了链地址法,即每个数组bucket中存放的是一个Entry链,每次新添加一个键值对,就是向链头添加一个Entry实例,新添加的Entry的下一个元素是原有的链头(如果该数组bucket不存在Entry链,则原有链头值为null,不影响逻辑)。每个Entry包含key、value、hash值和指向下一个Entry的next指针。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
添加
从以上描述中,我们可以知道添加新的键值对可以分成两部分:
1. 使用key计算出内部数组的索引值(index)。
2. 如果该索引的数组bucket中已经存在Entry链,并且该链中已经存在新添加的key的值,则将原有的值设置成新添加的值,并返回旧值。
3. 否则,创建新的Entry实例,将该实例插入到原有链的头部。
4. 在新添加Entry实例时,如果当前size超过阀值(capacity * loadFactor),数组容量将会自动扩大两倍,在数组扩容时,所有原存在的Entry会重新计算索引值,并且Entry链的顺序也会发生颠倒(如果还在同一个链中的话);而该新添加的Entry的索引值也会重新计算。
5. 对key为null时,默认数组的索引值为0,其他逻辑不变。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
插入原理图:
查找
查找和添加类似,首先根据key计算出数组的索引值(如果key为null,则索引值为0),然后顺序查找该索引值对应的Entry链,如果在Entry链中找到相等的key,则表示找到相应的Entry记录,否则,表示没找到,返回null。对get()操作返回Entry中的Value值,对于containsKey()操作,则判断是否存在记录,两个方法都调用getEntry()方法:
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
而对于value查找(如containsValue()操作)则需要整个表遍历(数组遍历和数组中的Entry链遍历),因而这种查找的效率比较低,代码实现也比较简单。
移除
移除操作(remove())也是先通过key值计算数组中的索引号(当key为null时索引号为0),从而找到Entry链,查找Entry链中的Entry,并将该Entry删除。
遍历
HashMap中实现了一个HashIterator,它首先遍历数组,查找到一个非null的Entry实例,记录该Entry所在数组索引,然后在下一个next()操作中,继续查找下一个非null的Entry,并将之前查找到的非null Entry返回。为实现遍历时不能修改HashMap的内容(可以更新已存在的记录的值,但是不可以添加、删除原有记录),HashMap记录一个modCount字段,在每次添加或删除操作起效时,将modCount自增,而在创建HashIterator时记录当前的modCount值(expectedModCount),如果在遍历过程中(next()、remove())操作时,HashMap中的modCount和已存储的expectedModCount不一样,表示HashMap已经被修改,抛出ConcurrentModificationException。即所谓的fail fast原则。
在HashMap中返回的key、value、Entry集合都是基于该Iterator实现,实现比较简单,不细讲。
注:clear()操作引起的内存问题-由于clear()操作只是将数组中的所有项置为null,数组本身大小并不改变,因而当某个HashMap已存储过较大的数据时,调用clear()有些时候不是一个好的做法。






 川公网安备51010802032098
川公网安备51010802032098