聚合操作处理数据记录并返回计算结果。聚合操作处理来自多个文档的一组数据,可以对这组数据执行各种操作以返回单个结果。MongoDB提供了三种执行聚合的方法:
聚合管道
MongoDB的聚合框架以数据处理管道的概念为基础。文档进入多级管道,将文档转换为聚合结果。例如:
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])
第一阶段:$match 按 status 字段过滤文档,并将 status 等于 “A” 的文档传递到下一阶段。
第二阶段:$group 阶段将文档按 cust_id 字段分组,以计算每个唯一 cust_id 的数量之和。
最基本的管道阶段提供了类似于查询和文档转换的过滤器,这些过滤器可以修改输出文档的形式。例如:上面实例过滤 status 等于 “A” 的文档,将过滤的文档传递给下一个阶段,相当于修改了文档。
其他管道操作提供了按特定字段对文档进行分组和排序的工具,以及聚合数组 (包括文档数组) 内容的工具。此外,管道阶段可以使用运算符来执行诸如计算平均值或连接字符串等任务。
管道使用 MongoDB 中的本机操作提供高效的数据聚合,是MongoDB中数据聚合的首选方法。
聚合管道可以对已分割的集合进行操作。
聚合管道可以在某些阶段使用索引来提高其性能。此外,聚合管道有一个内部优化阶段。
mongodb广告位
实例:
# 准备数据
> db.orders.insert({cust_id:"A123", amount: 500, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"A123", amount: 250, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"B212", amount: 200, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"A123", amount: 300, status:"d"});
WriteResult({ "nInserted" : 1 })
> db.orders.find({});
{ "_id" : ObjectId("5e79986526d8428fa1fc2cfe"), "cust_id" : "A123", "amount" : 500, "status" : "A" }
{ "_id" : ObjectId("5e79986526d8428fa1fc2cff"), "cust_id" : "A123", "amount" : 250, "status" : "A" }
{ "_id" : ObjectId("5e79986526d8428fa1fc2d00"), "cust_id" : "B212", "amount" : 200, "status" : "A" }
{ "_id" : ObjectId("5e79986726d8428fa1fc2d01"), "cust_id" : "A123", "amount" : 300, "status" : "d" }
# 分组操作
> db.orders.aggregate([{ $match:{status:"A"} }, { $group:{_id:"$cust_id", total:{ $sum:"$amount"} } }]);
{ "_id" : "B212", "total" : 200 }
{ "_id" : "A123", "total" : 750 }
Map-Reduce
Map-Reduce 是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。MongoDB 提供的 Map-Reduce 非常灵活,对于大规模数据分析也相当实用。如果你学过 Hadoop,则对 Map-Reduce 应该非常熟悉了。
MongoDB还提供 map-reduce 操作来执行聚合。一般说来,map-reduce 有两个阶段:
Map-Reduce 可以有一个最后的阶段对结果进行最终修改。与其他聚合操作一样,map-reduce 可以指定查询条件来选择输入文档以及排序和限制结果。
Map-Reduce 使用自定义 JavaScript 函数执行 map 和 reduce 操作,以及可选的 finalize 操作。与聚合管道相比,自定义 JavaScript 提供了极大的灵活性。总体而言,map-reduce 比聚合管道效率更低、更复杂。
Map-Reduce 可以在一个切分的集合上操作。Map-reduce 也可以输出到切分集合。
注意:从 MongoDB2.4 开始,某些 mongo shell 函数和属性在 map-reduce 操作中是不可访问的。MongoDB2.4 还支持同时运行多个 JavaScript 操作。在MongoDB2.4之前,JavaScript代码是在一个线程中执行的,这就引发了 map-reduce 的并发问题。
Map-Reduce的语法:
>db.collection.mapReduce(
function() {emit(key,value);}, // map 函数
function(key,values) {return reduceFunction}, // reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 Map-Reduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value),遍历 collection 中所有的记录,将 key 与 value 传递给 Reduce 函数进行处理。Map 函数必须调用 emit(key, value) 返回键值对。参数说明:
map:映射函数 (生成键值对序列,作为 reduce 函数参数)
reduce:统计函数,reduce 函数的任务就是将 key-values 变成 key-value,也就是把 values 数组变成一个单一的值 value
out:统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)
query 一个筛选条件,只有满足条件的文档才会调用 map 函数(query、limit、sort 可以随意组合)
sort:sort 和 limit 结合的 sort 排序参数(也是在发往 map 函数前给文档排序),可以优化分组机制
limit:发往 map 函数的文档数量的上限(要是没有limit,单独使用 sort 的用处不大)
Map-Reduce 演算,步骤如下:
# 准备数据
[
{k:'A', v:'20'},
{k:'A', v:'15'},
{k:'A', v:'20'},
{k:'B', v:'10'},
]
# 调用4次map,将汇聚的如下数据发送给 reduce
reduce('A', [20, 15, 20])
reduce('B', [10])
# reduce 执行后的最终结果
{_id:'A', value:55}
{_id:'B', value:10}
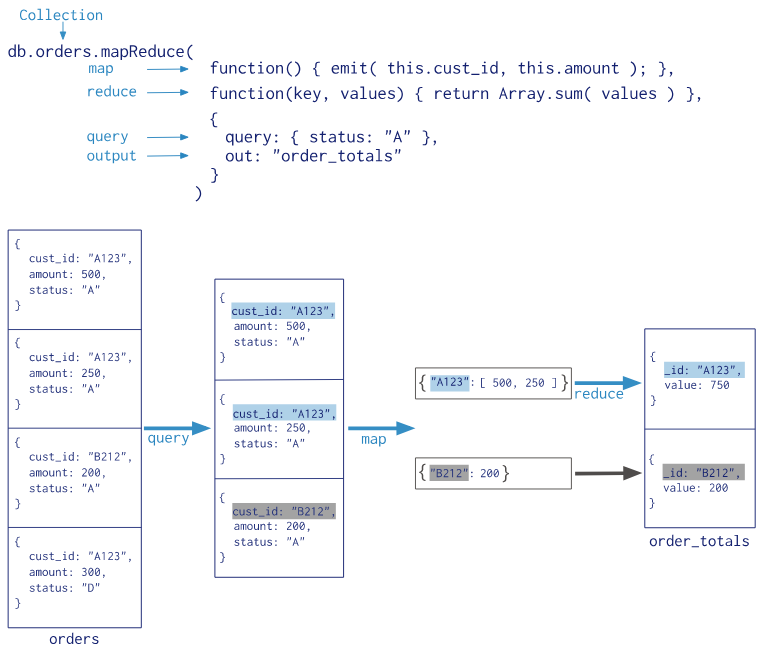
实例:使用 map-reduce 来实现分组统计。
# 准备数据
> db.orders.insert({cust_id:"A123", amount: 500, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"A123", amount: 250, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"B212", amount: 200, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"A123", amount: 300, status:"d"});
WriteResult({ "nInserted" : 1 })
> db.orders.find({});
{ "_id" : ObjectId("5e79986526d8428fa1fc2cfe"), "cust_id" : "A123", "amount" : 500, "status" : "A" }
{ "_id" : ObjectId("5e79986526d8428fa1fc2cff"), "cust_id" : "A123", "amount" : 250, "status" : "A" }
{ "_id" : ObjectId("5e79986526d8428fa1fc2d00"), "cust_id" : "B212", "amount" : 200, "status" : "A" }
{ "_id" : ObjectId("5e79986726d8428fa1fc2d01"), "cust_id" : "A123", "amount" : 300, "status" : "d" }
# 分组统计
> db.orders.mapReduce(
... function(){ emit(this.cust_id, this.amount); },
... function(key, values) { return Array.sum(values); },
... {
... query: { status: "A" },
... out: "order_totals"
... }
... );
{
"result" : "order_totals",
"timeMillis" : 537,
"counts" : {
"input" : 3,
"emit" : 3,
"reduce" : 1,
"output" : 2
},
"ok" : 1
}
参数说明:
result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。
timeMillis:执行花费的时间,毫秒为单位
input:满足条件被发送到map函数的文档个数
emit:在map函数中emit被调用的次数,也就是所有集合中的数据总量
ouput:结果集合中的文档个数(count对调试非常有帮助)
ok:是否成功,成功为1
err:如果失败,这里可以有失败原因,不过从经验上来看,原因比较模糊,作用不大
mongodb广告位
使用 find() 查看 map-reduce 的结果。如下:
> db.orders.mapReduce(
... function(){ emit(this.cust_id, this.amount); },
... function(key, values) { return Array.sum(values); },
... {
... query: { status: "A" },
... out: "order_totals"
... }
... ).find();
{ "_id" : "A123", "value" : 750 }
{ "_id" : "B212", "value" : 200 }
单目聚合操作
MongoDB还提供了 db.collection.estimatedDocumentCount(), db.collection.count() 和 db.collection.distinct()。
所有这些操作都从单个集合聚合文档。虽然这些操作提供了对常见聚合过程的简单访问,但它们缺乏聚合管道和 map-reduce 的灵活性和功能。
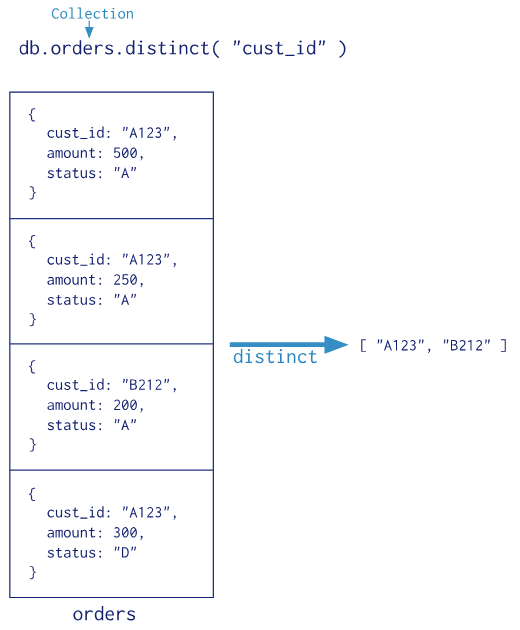
实例:演示 distinct 聚合的用法。如下:
# 准备数据
> db.orders.insert({cust_id:"A123", amount: 500, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"A123", amount: 250, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"B212", amount: 200, status:"A"});
WriteResult({ "nInserted" : 1 })
> db.orders.insert({cust_id:"A123", amount: 300, status:"d"});
WriteResult({ "nInserted" : 1 })
> db.orders.find({});
{ "_id" : ObjectId("5e79986526d8428fa1fc2cfe"), "cust_id" : "A123", "amount" : 500, "status" : "A" }
{ "_id" : ObjectId("5e79986526d8428fa1fc2cff"), "cust_id" : "A123", "amount" : 250, "status" : "A" }
{ "_id" : ObjectId("5e79986526d8428fa1fc2d00"), "cust_id" : "B212", "amount" : 200, "status" : "A" }
{ "_id" : ObjectId("5e79986726d8428fa1fc2d01"), "cust_id" : "A123", "amount" : 300, "status" : "d" }
> db.orders.distinct("cust_id");
[ "A123", "B212" ]






 川公网安备51010802032098
川公网安备51010802032098