本章节将简单的介绍 MySQL 中性能优化的基础知识,包括:MySQL 最大数据量、最大并发数、推荐查询时间、实践原则。
当 MySQL 数据库数量达到一定量,如:单表有几百万数据量时,我们就需要对 MySQL 做性能优化(推荐在应用程序整个生命周期中持续优化 MySQL 性能,而不是某一个固定阶段)。本文将先介绍优化 MySQL 数据库的一些指标。
最大数据量
最大数据量指 MySQL 单表中允许存放的最大数据量;虽然 MySQL 没有限制单表最大记录数,但还是取决于操作系统对文件大小的限制。
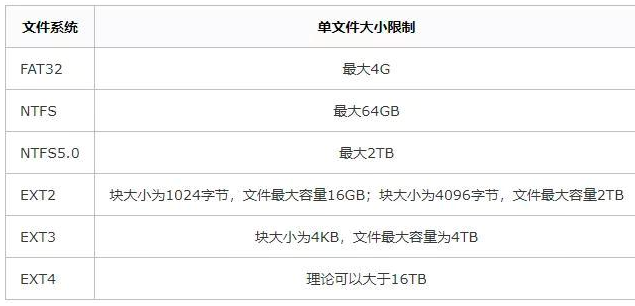
在《阿里巴巴 Java 开发手册》中提出,如果单表数据行数超过 500 万行(注意:500 万这个值仅供参考,并非铁律)或者单表数据容量超过 2GB,才推荐进行分库分表(其实分库分表是一个周期长、风险高、复杂的活儿)。
性能由综合因素决定,抛开业务复杂度,影响程度依次是硬件配置、MySQL 配置、数据表设计、索引优化。
分库分表是个周期长而风险高的大活儿,应该尽可能在当前结构上优化,比如升级硬件、迁移历史数据等等,实在没辙了再分。对分库分表感兴趣的同学可以阅读分库分表的基本思想。
mysql广告位
最大并发数
并发数是指同一时刻数据库能处理多少个请求,由 max_connections 和 max_user_connections 决定。其中:
MySQL 会为每个连接提供缓冲区,意味着消耗更多的内存。如果连接数设置太高硬件吃不消,太低又不能充分利用硬件。一般要求 max_connections 和 max_user_connections 比值超过 10%,计算方法如下:
-- 下面设置 max_used_connections=3,max_connections = 100
max_used_connections / max_connections * 100% = 3/100 *100% ≈ 3%
查看 MySQL 最大连接数与响应最大连接数:
-- 查看最大连接数
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set
-- 查看最大用户连接数
mysql> show variables like '%max_user_connections%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| max_user_connections | 0 |
+----------------------+-------+
1 row in set
可以通过修改 my.cnf(Linux) 配置文件,或者修改 my.ini(Windows) 配置文件来修改最大连接数和最大用户连接数,如下:
[mysqld]
max_connections = 151
max_used_connections = 0
查询耗时 0.5 秒
建议将单次查询耗时控制在 0.5 秒以内,0.5 秒是个经验值,源于用户体验的 3 秒原则。
【3秒钟原则】
现代人的生活节奏都很快,网页间的切换速度也越来越快。所谓“3秒钟原则”,就是要在极短的时间内展示重要信息,给用户留下深刻的第一印象。当然,这里的3秒只是一个象征意义上的快速浏览表述,在实际浏览网页的时候,并非真的严格遵守3秒。
据《眼球轨迹的研究》得出,在一般的新闻网站,用户关注的是最中间靠上的内容,可以用一个字母F表示,这种基于F图案的浏览行为有3个特征:首先,用户会在内容区的上部进行横向浏览。其次,用户视线下移一段距离后在小范围再次横向浏览。最后,用户在内容区的左侧做快速纵向浏览。
遵循这个F形字母,网站设计者应该把最重要的信息放在这个区域,才能给访问者在3秒钟的极短时间内留下更加鲜明的第一印象。因此,在设计互联网产品的页面时,用户等待时间越少,用户体验越好。合理的运用这种阅读行为,对于产品设计会有很好的启发意义。
如果用户的操作 3 秒内没有任何响应,可能会厌烦,甚至关闭网页、退出程序。响应时间是由如下时间片段组成:
响应时间 = 客户端 UI 渲染耗时 + 网络请求耗时 + 应用程序处理耗时 + 查询数据库耗时
根据3秒规则,0.5 秒就是留给数据库 1/6 的处理时间。下图为 Chrome 的 DevTools 工具中对某一个网络请求时间的分析:
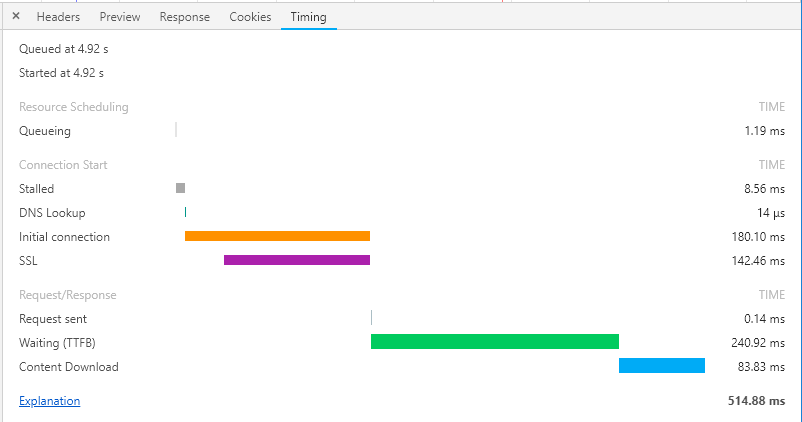
上图中的,TTFB 等于 应用程序处理耗时 + 查询数据库耗时。
实践原则
相比 NoSQL 数据库,MySQL 存在扩容难、容量小并发低、SQL约束太多问题。现今大多数应用都会使用分布式架构来构建,分布式应用程序扩容比数据库扩容要容易得多,所以实施原则是让数据库少干活,应用程序多干活:
充分利用但不滥用索引,须知索引也消耗磁盘和 CPU。
不推荐使用数据库函数格式化数据,交给应用程序处理。
不推荐使用外键约束,用应用程序保证数据准确性。
写多读少的场景,不推荐使用唯一索引,用应用程序保证唯一性。
适当冗余字段,尝试创建中间表,用应用程序计算中间结果,用空间换时间。
不允许执行极度耗时的事务,配合应用程序拆分成更小的事务。
预估重要数据表(比如订单表)的负载和数据增长态势,提前优化。
参考:https://www.toutiao.com/i6829475322774159880/?timestamp=1590117538&app=news_article&group_id=6829475322774159880&req_id=202005221118580100210341010C01470C






 川公网安备51010802032098
川公网安备51010802032098