ZooKeeper的数据模型和文件系统的层次结构非常相似,它使用节点(Node)来存储数据,这些节点被组织成树形结构,其中包括根节点(/)。每个节点可以存储少量的数据,通常是文本形式的。
注意:ZooKeeper 命名空间中的每个节点都由一个路径标识,如:/app1/p_1。
ZooKeeper 数据模型示例如下图:
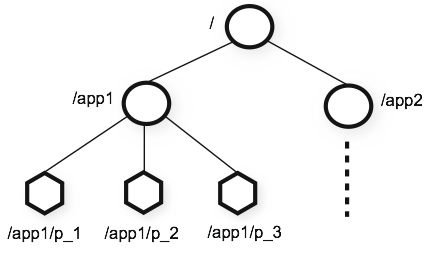
以下是 ZooKeeper 数据模型的关键特点和组成部分:
节点(Node):ZooKeeper 中的数据单元称为节点。每个节点都有一个路径,类似于文件系统中的路径。节点的路径唯一标识了节点在 ZooKeeper 树中的位置。例如:/app1/p_2 节点。
树形结构:所有的节点都被组织成一个树形层次结构,类似于目录和文件在文件系统中的组织方式。根节点(/)是顶层节点,其他节点从根节点开始,形成树形结构。
数据:每个节点可以存储一小段数据,通常是文本。这些数据可以用来存储配置信息、状态信息或其他应用程序需要的数据。
版本:每个节点都有一个版本号,它用来标识节点数据的变化。当节点的数据被更新时,版本号会递增。
ACL(访问控制列表):每个节点可以关联一个 ACL,用于控制节点的访问权限。ACL 定义了哪些客户端可以执行读取和写入操作以及节点的子节点操作。
临时节点:ZooKeeper 支持临时节点,这些节点在创建它们的客户端会话结束时自动删除。这对于表示在线/离线状态或会话管理非常有用。
顺序节点:客户端可以创建顺序节点,这些节点的名称由 ZooKeeper 分配,并包含一个序号。这有助于客户端对节点的有序访问。
观察者(Watcher):客户端可以在节点上设置观察者,以便在节点的数据发生变化时接收通知。这使得客户端可以实时监视节点的状态变化。
ZooKeeper 广告位
节点和临时节点
与标准文件系统不同,ZooKeeper 命名空间中的每个节点都可以拥有与之相关的数据和子节点,这就像文件系统允许文件同时也是目录一样。
注意,ZooKeeper 被设计用于存储协调数据:状态信息、配置、位置信息等,因此存储在每个节点上的数据通常很小,在 0byte ~ 1000byte 范围内。而且,我们使用 “znode” 表示 ZooKeeper 数据节点。
Znode 维护一个统计结构,其中包括数据更改的版本号、ACL 更改和时间戳,以便进行缓存验证和协调更新。每次 znode 的数据发生变化,版本号就会增加。每当客户端检索数据时,它也会收到数据的版本号。
命名空间中每个 znode 存储的数据都是以原子方式读写的。读取会获得与某个 znode 相关联的所有数据字节,而写入则会替换所有数据。每个节点都有一个访问控制列表(ACL),限制谁可以做什么(即谁能读取、写入和操作子节点)。
ZooKeeper 还有临时节点的概念。只要创建 znode 的会话处于活动状态,这些 znode 就会一直存在。当会创建 znode 的话结束时,znode 就会被自动删除。
有条件的更新和监视
ZooKeeper 支持监视(watch)的概念。客户端可以对某个 znode 设置监视。当 znode 发生变化时,监视就会被触发和移除(注意:监视被触发一次后,需要再次监视,不然就不能再次触发,因为已经被移除了)。当监视被触发时,客户端会收到一个数据包,说明该 znode 已发生变化。如果客户端与 ZooKeeper 服务器之间的连接中断,客户端将收到本地通知。
3.6.0 中的新功能:客户端还可在一个 znode 上设置永久递归监视,这些监视在触发时不会被移除,并可触发已注册 znode 以及任何子 znode 上的更改。
Zookeeper 的承诺
ZooKeeper 非常快,也非常简单。但是,由于它的目标是作为构造更复杂的服务(如分布式锁、同步等)的基础,因此它提供了一些承诺:
顺序一致性:客户端的更新将按照发送顺序应用。
原子性:更新要么成功要么失败,没有部分结果。
单一系统映像:客户端无论连接到哪个服务器,都将看到相同的服务视图,也就是说,即使客户端通过相同会话切换到不同的服务器,也不会看到旧的系统视图。
可靠性:更新一旦应用,就会一直持续下去,直到客户端覆盖更新。
及时性:保证系统的客户端视图在一定的时间范围内是最新的。

 川公网安备51010802032098
川公网安备51010802032098