DBMaker 类是 MapDB 中创建和配置数据库实例(DB)的核心构建器类,它采用建造者模式(Builder Pattern) 设计,提供了一系列链式调用的配置方法,让你可以灵活地创建不同类型(内存 / 文件)、不同特性(持久化 / 并发 / 压缩)的 MapDB 数据库实例。
DBMaker 类负责数据库的配置、创建和打开。
MapDB 有多种模式和配置选项,其中大多数都可以通过此类进行设置。
核心静态方法
DBMaker 提供了多个静态方法来指定数据库的存储类型,这是创建数据库的第一步:
文件数据库
创建文件持久化数据库,数据存储到指定文件,程序重启后数据保留。
方法定义如下:
示例:
public static void main(String[] args) {
try (DB memoryDB = DBMaker.fileDB("file.db").make()) {
ConcurrentMap<String, String> map = memoryDB
.hashMap("map", Serializer.STRING, Serializer.STRING)
.createOrOpen();
map.put("content", "use file path");
String value = map.get("content");
System.out.println("value=" + value);
}
}
或者
public static void main(String[] args) {
File dbFile = new File("file.db");
try (DB memoryDB = DBMaker.fileDB(dbFile).make()) {
ConcurrentMap<String, String> map = memoryDB
.hashMap("map", Serializer.STRING, Serializer.STRING)
.createOrOpen();
map.put("content", "use file object");
String value = map.get("content");
System.out.println("value=" + value);
}
}
内存数据库
创建新的内存数据库,JVM退出后,所有数据将会丢失。
使用此种方式的数据库,会将数据序列化为 byte[],因此它们不受垃圾回收器的影响。
方法定义如下:
示例:
public static void main(String[] args) {
try (DB memoryDB = DBMaker.memoryDB().make()) {
ConcurrentMap<String, String> map = memoryDB
.hashMap("map", Serializer.STRING, Serializer.STRING)
.createOrOpen();
map.put("content", "memory database");
String value = map.get("content");
System.out.println("value=" + value);
}
}
堆内存数据库
创建新的内存数据库,该数据库将所有数据存储在堆上,无需序列化。这种模式应该非常快,但数据对垃圾回收器的影响与传统的 Java 集合相同。
📌知识回顾
JVM 堆是 Java 虚拟机中最大的一块内存区域,也是最核心的内存区域之一,它是所有线程共享的内存空间,主要用于存储对象实例和数组(几乎所有的对象都在堆上分配内存)。
堆的的特性:
线程共享:整个 JVM 进程中只有一个堆空间,所有线程都可以访问堆中的对象(需注意线程安全)。
垃圾回收(GC)核心区域:堆是垃圾收集器(Garbage Collector)的主要工作区域,当对象不再被引用时,GC 会回收其占用的堆内存。
可动态扩展:堆的大小可以通过 JVM 参数(-Xms 初始堆大小、-Xmx 最大堆大小)配置,运行时会根据需要在初始值和最大值之间动态调整。
OutOfMemoryError:当堆内存不足且无法再扩展,或 GC 后仍无法为新对象分配内存时,会抛出 java.lang.OutOfMemoryError: Java heap space 异常。
方法定义如下:
示例:
public static void main(String[] args) {
try (DB memoryDB = DBMaker.heapDB().make()) {
ConcurrentMap<String, String> map = memoryDB
.hashMap("map", Serializer.STRING, Serializer.STRING)
.createOrOpen();
map.put("content", "heap memory database");
String value = map.get("content");
System.out.println("value=" + value);
}
}
临时文件数据库
DBMaker 类支持在临时文件夹中创建新数据库,当存储关闭后,文件会被删除。
方法定义如下:
示例:
public static void main(String[] args) throws Exception {
try (DB memoryDB = DBMaker.tempFileDB().make()) {
ConcurrentMap<String, String> map = memoryDB
.hashMap("map", Serializer.STRING, Serializer.STRING)
.createOrOpen();
map.put("content", "temp file database");
String value = map.get("content");
System.out.println("value=" + value);
}
// 暂停运行,方便查看临时文件路径
Thread.sleep(Integer.MAX_VALUE);
}
运行示例,查看 Windows 的临时目录(地址栏输入 %temp% 回车,直接进入临时目录),如下图:
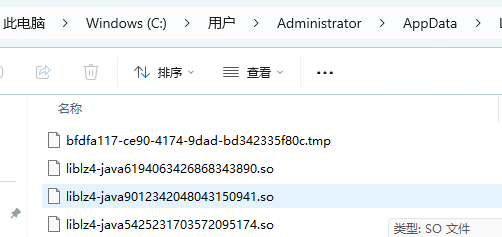
再去手动结束程序,临时目录如下图:
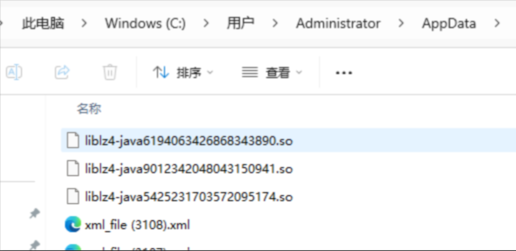
你会发现第一个文件已经被自动删除了。
你注意到了吗?上面所有静态方法都返回了一个 DBMaker.Maker 实例,下面来看看 DBMaker.Maker 是什么……
MapDB广告
DBMaker.Maker 类
DBMaker.Maker 是 DBMaker 类的内部构建器类(Builder),也是 MapDB 中配置数据库实例的核心载体。
当你调用 DBMaker.fileDB()/DBMaker.memoryDB() 等静态方法时,返回的其实就是 DBMaker.Maker 实例 —— 它封装了所有数据库的配置项,并提供链式调用的方法来定制数据库行为,最终通过 make() 方法生成 DB 实例。
下面是常用配置方法:
MapDB 通过头部校验和检测非正常关闭(以及可能的数据损坏)。如果存储被修改但未正确关闭,该校验和将失效。在这种情况下,MapDB 会抛出异常并拒绝打开存储。
而 checksumHeaderBypass() 方法将强制跳过“头部校验和”的比对步骤,即使检测到校验和不一致,MapDB 也不会抛出异常,仍会尝试打开数据库。
注意:该方法本质是 “绕过安全校验”,仅适合在明确知晓数据无关键损坏,且必须强制恢复数据的极端场景使用(如紧急恢复备份、排查异常时)。
启用全存储校验和。整个文件由64位校验和覆盖,以捕获可能的数据损坏。这可能会很慢,因为在存储打开、提交和关闭时,需要遍历整个文件来计算校验和。
添加JVM关闭钩子,并在JVM即将关闭前关闭数据库。
添加JVM关闭钩子,并在JVM即将关闭前关闭数据库。这与 closeOnJvmShutdown() 类似,但数据库在关闭钩子中通过弱引用(WeakReference)被引用,并且可以被垃圾回收(GCed)。这在某些情况下可能会防止内存泄漏,但不能保证数据库一定会被实际关闭。
禁用数据库的并发访问支持。
警告:此选项存在危险。禁用锁后,多线程访问可能会导致数据损坏等问题。MapDB没有快速失败迭代器或任何其他保护措施。
This value has to be power of two, so it is rounded up automatically.
该方法用于优化数据库并发访问性能。通过将数据库内部的数据结构拆分为 segmentCount 个“分段(segment)”,让多个线程可同时操作不同分段,减少线程间的锁竞争,从而提升高并发场景下的吞吐量。
注意,参数 segmentCount 必须是 2 的幂。例如合法值为 2、4、8、16、32 等(2¹、2²、2³...)。这是因为“2 的幂”分段能通过位运算(如 & 操作)快速定位数据所属分段,比非 2 的幂分段的计算效率更高(避免取模等耗时运算),是数据库优化并发的常见设计。
如果传入的 segmentCount 不是 2 的幂(如传入 5、7、10),框架会自动将其向上调整为最近的 2 的幂值(如 5→8、7→8、10→16),确保满足上述性能设计要求,无需开发者手动计算合法值。
启用后台执行器。后台执行器本质是数据库内部的一个后台线程 / 线程池,启用后主要用于处理非即时性、低优先级的异步任务,避免这类任务阻塞用户主线程的数据库操作。
启用 FileChannel 访问。默认情况下,MapDB 使用 java.io.RandomAccessFile,它速度较慢但更稳健,不过不允许并发访问(并行读写)。RAF 仍然是线程安全的,但具有全局锁。FileChannel 没有全局锁,并且比 RAF 更快。然而,内存映射文件可能是最佳选择。
方法用于强制启用“内存映射文件(Memory-Mapped Files,MMAP)” 功能。
如果启用此模式,在 32 位JVM上,你可能会遇到 java.lang.OutOfMemoryError: Map failed 异常。
方法用于选择性启用“内存映射文件(Memory-Mapped Files,MMAP)” 功能。
内存映射文件是一种 I/O 优化技术,能将磁盘上的数据库文件直接映射到 JVM 进程的内存地址空间,避免传统“磁盘读 → 内核缓冲区 → 用户内存”的多步拷贝,提升数据库读写性能。
注意,只有当前 JVM 为 64 位时,才能正常开启内存映射。为什么 64 位才支持呢?
(1)32 位 JVM 最大可寻址内存通常仅 4GB(实际可用远低于此),无法映射较大的数据库文件,强行使用易导致内存溢出。
(2)64 位 JVM 支持 TB 级别的内存地址空间,能从容映射大文件,且主流 Java 数据库会默认将 MMAP 与 64 位 JVM 绑定,避免 32 位环境下的兼容性问题。
以只读模式打开存储,任何尝试修改数据都会抛出 UnsupportedOperationException 异常(“只读”)。
简单示例:
public static void main(String[] args) throws Exception {
try (DB memoryDB = DBMaker.fileDB("file.db")
.fileChannelEnable() // 启用 FileChannel 访问
.make()) {
ConcurrentMap<String, String> map = memoryDB
.hashMap("map", Serializer.STRING, Serializer.STRING)
.createOrOpen();
map.put("content", "hello world");
String value = map.get("content");
System.out.println("value=" + value);
}
}
更多关于 MapDB 的知识,请继续学习后续教程🚀

 川公网安备51010802032098
川公网安备51010802032098