在 Prometheus 中,为了更为方便、快捷的使用 PromQL 语言查询数据,内部提供了大量的内置函数,用于聚合运算等等,同时也提供了很多运算符,如数字运算加减乘除等等。
示例一:使用 rate() 函数计算增长率
rate() 函数是 Prometheus 查询语言 (PromQL) 中的一个内置函数,用于计算时间序列数据的平均增长率。它可以帮助你了解时间序列数据的变化趋势,特别是在监控和警报方面。
rate() 函数的基本语法如下:
rate(metric_name[range_vector])
其中:
rate() 函数会计算指标在指定时间窗口内的平均增长率。具体来说,它会取时间窗口内最后两个数据点,并计算这两个数据点之间的增长率。然后,它会将这个增长率作为整个时间窗口的平均增长率返回。
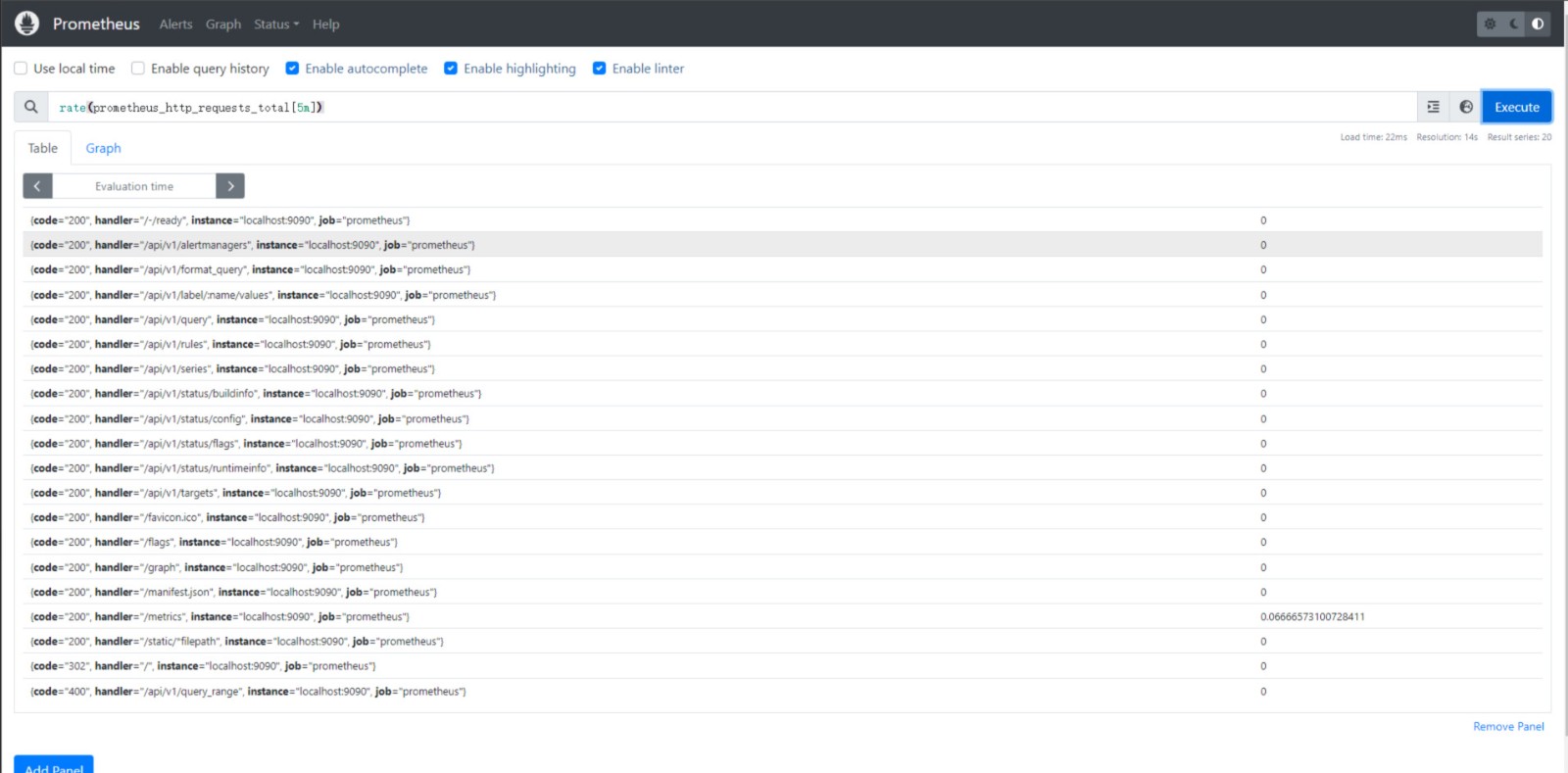
例如,如果你想要计算过去 5 分钟内 prometheus_http_requests_total 指标的平均增长率,你可以使用以下查询:
rate(prometheus_http_requests_total[5m])
这个查询会返回一个标量值,表示过去 5 分钟内 prometheus_http_requests_total 指标的平均增长率。
执行结果如下图:
公共广告位-其他
示例二:使用 sum() 函数求和
sum() 函数用于计算指定时间范围内的时间序列数据的总和。这个函数通常用于聚合多个时间序列数据点,以便得到一个单一的总计值。
sum() 函数的基本语法如下:
sum(metric_name[range_vector])
其中:
注意:sum() 函数会将所有选定时间范围内的数据点相加,不考虑数据点的时间戳。这意味着,如果时间范围包含多个相同的时间戳(这在实际中不太可能,但理论上可能),那么这些值会被多次相加。
此外,sum() 函数通常与 by() 子句一起使用,以便按特定标签对时间序列进行分组并计算每个组的总和。例如,如果你想要计算每个作业(job)在过去一小时内的 HTTP 请求总数,你可以使用以下查询:
sum(http_requests_total{job=~"job1|job2"}[1h]) by (job)
或者
sum by (job) (http_requests_total{job=~"job1|job2"}[1h])
这个查询会返回一个按 job 标签分组的时间序列,每个时间序列表示相应作业在过去一小时内的 HTTP 请求总数。
注意:sum() 函数只能用于计数器(Counter)类型的指标,因为计数器是单调递增的,适合累加。对于其他类型的指标(如 Gauge),使用 sum() 函数可能没有意义,因为 Gauge 指标的值可以任意变化,不一定适合累加。
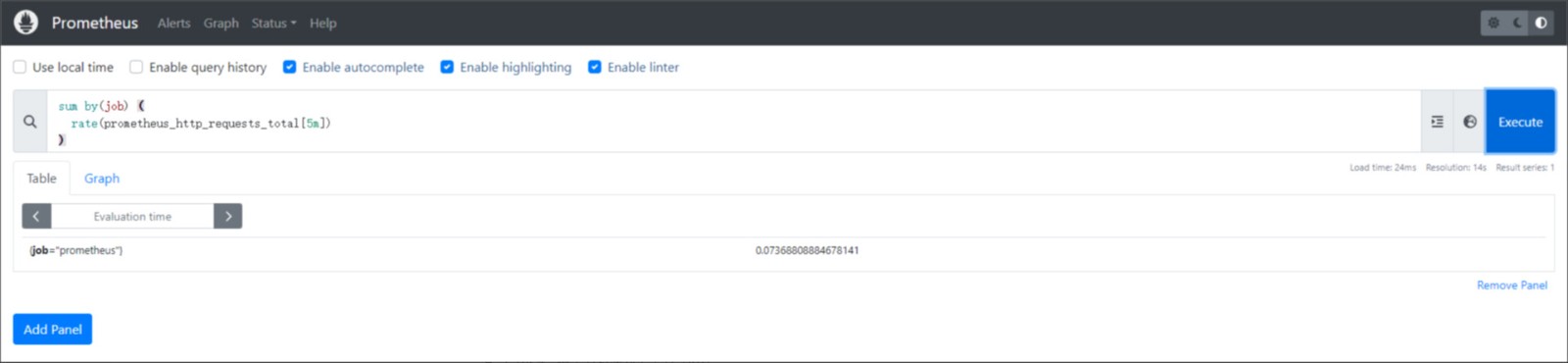
实例:假设 prometheus_http_requests_total 时间序列都有 job 标签,我们可能希望对所有实例的速率求和,这样就能减少输出时间序列,但仍能保留作业维度:
sum by(job) (
rate(prometheus_http_requests_total[5m])
)
让我们逐步分析这个查询:
prometheus_http_requests_total[5m]:prometheus_http_requests_total 是一个计数器类型的指标,通常用于表示 Prometheus 服务器收到的 HTTP 请求总数。[5m] 是一个范围向量选择器,表示选取过去5分钟内的数据点。
rate(prometheus_http_requests_total[5m]):函数 rate() 计算指定时间范围向量内的指标的平均增长率。在这里,它计算了 prometheus_http_requests_total 在过去5分钟内的平均增长率。这个增长率是一个即时向量,因为它表示了在每个时间点上的增长率,而不是一个时间段内的总和。
sum by(job) (...):sum by(job) 表示按照 job 标签对即时向量进行分组,并计算每个组的总和。这意味着查询结果将为每个唯一的 job 标签值提供一个总和,该总和表示该作业在过去5分钟内的平均请求增长率。
综上所述,这个查询将返回每个 Prometheus 作业(由 job 标签标识)在过去5分钟内的 HTTP 请求平均增长率的总和。这个查询有助于了解不同 Prometheus 作业在给定时间范围内的请求增长率情况。如果某个作业的请求增长率异常高或低,这可能表明该作业的性能或流量模式与其他作业有所不同,需要进一步调查。
执行结果如下图:
示例三:使用运算操作符
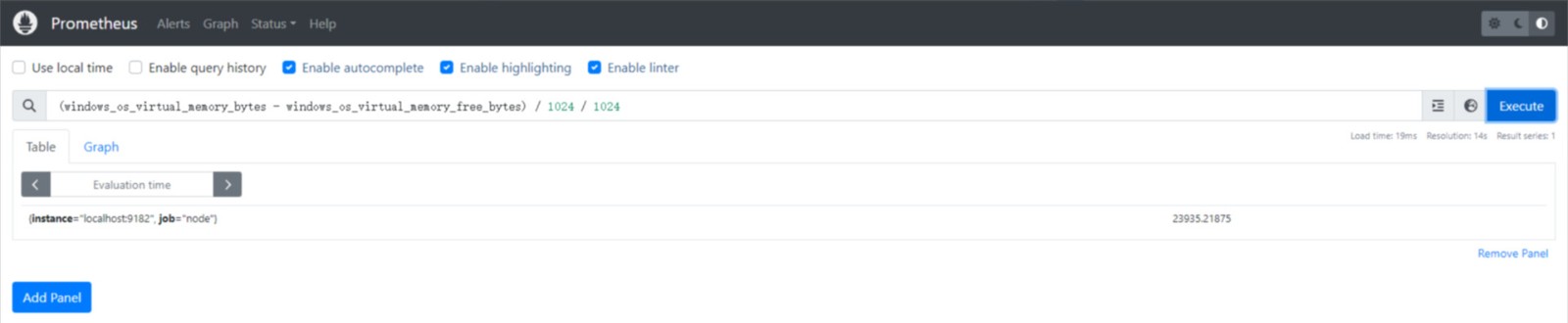
如果我们有两个具有相同维度标签的不同指标,我们可以对它们应用二元运算符,两边具有相同标签集的元素将被匹配并传播到输出中。例如(单位:MiB):
(windows_os_virtual_memory_bytes - windows_os_virtual_memory_free_bytes) / 1024 / 1024
上述表达式将计算 Windows 操作系统上已使用的虚拟内存量,并且将其从字节转换为兆字节(MB)。步操作分析如下:
windows_os_virtual_memory_bytes:这个指标代表了系统的总虚拟内存大小(以字节为单位)。
windows_os_virtual_memory_free_bytes:这个指标代表了系统虚拟内存中当前空闲的部分(以字节为单位)。
windows_os_virtual_memory_bytes - windows_os_virtual_memory_free_bytes:通过减去空闲内存,我们得到了当前已使用的虚拟内存量(以字节为单位)。
/ 1024:将字节转换为千字节(KB)。
/ 1024:再次除以1024,将千字节转换为兆字节(MB)。
最终,这个表达式会返回一个表示已使用虚拟内存量的 Prometheus 即时向量,单位是兆字节(MB)。
运行结果如下图:
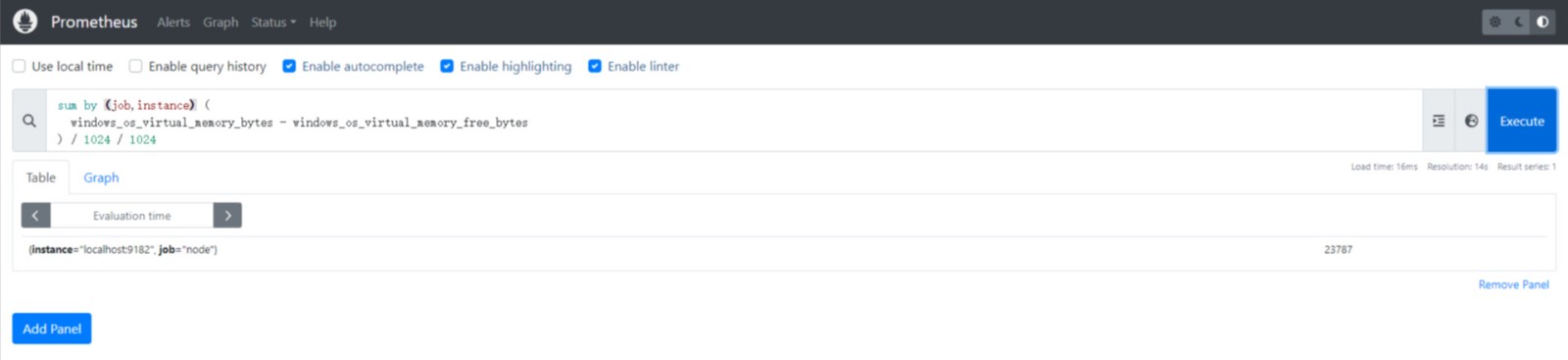
同样的表达式,但通过应用求和,可以这样写:
sum by (job,instance) (
windows_os_virtual_memory_bytes - windows_os_virtual_memory_free_bytes
) / 1024 / 1024
运行结果如下图:
公共广告位-其他
示例四:分组获取前 3 的数据
在 Prometheus 中,topk() 函数是一个向量聚合操作符,用于从给定的向量中选取具有最大或最小值的 k 个样本。
topk() 函数有两种形式:
topk(k, vector):返回向量中最大的 k 个样本。
bottomk(k, vector):返回向量中最小的 k 个样本。
其中,k 是一个整数,表示你想要选取的样本数量,而 vector 是你想要从中选取样本的向量。
例如,假设你有一个名为 prometheus_http_requests_total 的指标,该指标记录了过去一段时间内 HTTP 请求的总数。你可以使用 topk() 函数来找出请求量最高的前 10 个实例:
(1)先执行如下 PromQL 查看 prometheus_http_requests_total 的指标:
prometheus_http_requests_total
执行结果如下图:
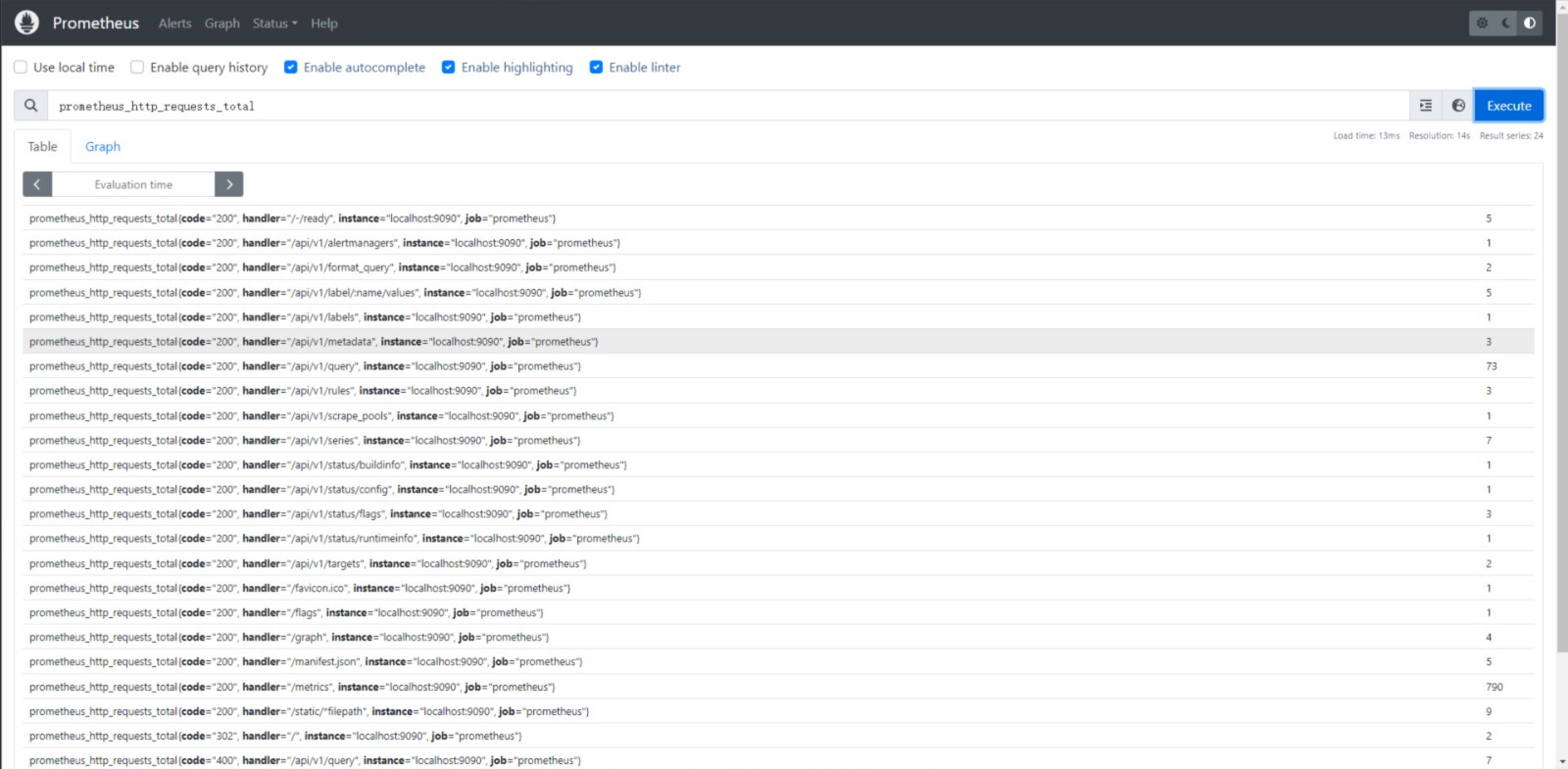
然后,使用 topk() 函数获取 prometheus_http_requests_total 指标中请求数最大的 10 个:
topk(10, prometheus_http_requests_total)
执行结果如下图:
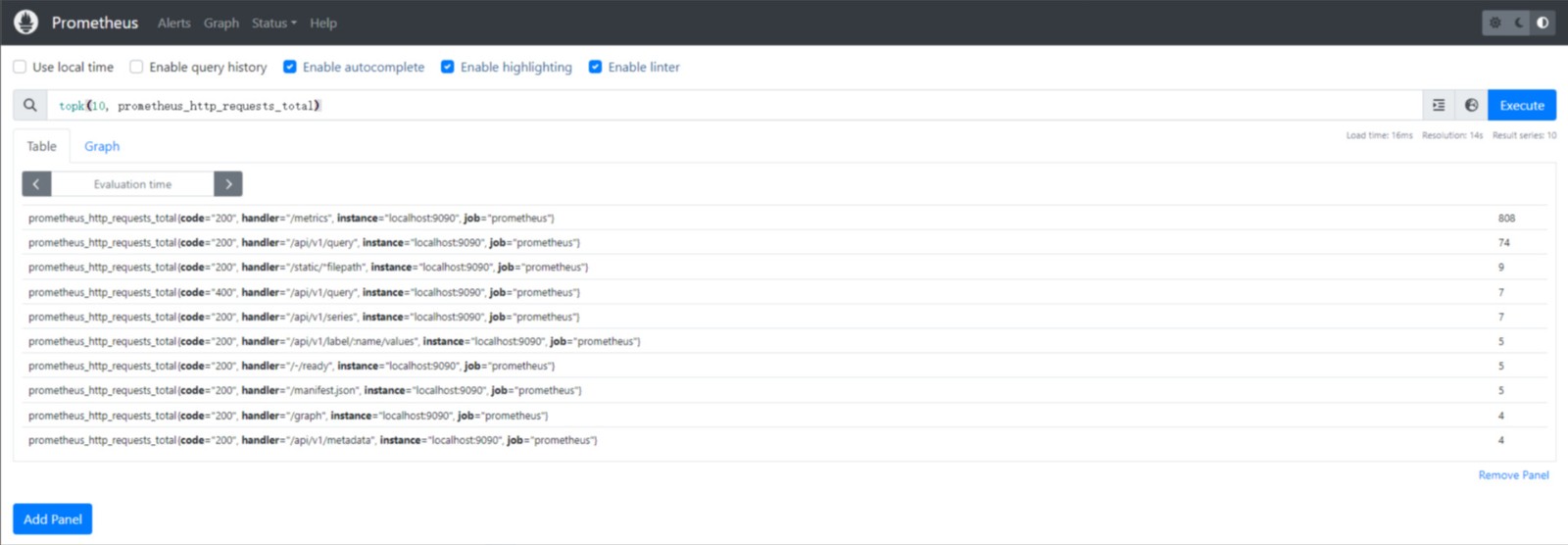
上图返回了一个包含 10 个样本的向量,其中每个样本都是 prometheus_http_requests_total 指标中最大的 10 个值之一。
注意:topk() 函数返回的是样本的原始值,而不是时间序列或标签。如果你需要查看与这些样本相关联的时间序列或标签,你可能需要使用其他 PromQL 函数或操作符来进一步处理结果。
如果同一个虚构集群调度程序为每个实例提供如下 CPU 使用指标:
instance_cpu_time_ns{app="lion", proc="web", rev="34d0f99", env="prod", job="cluster-manager"}
instance_cpu_time_ns{app="elephant", proc="worker", rev="34d0f99", env="prod", job="cluster-manager"}
instance_cpu_time_ns{app="turtle", proc="api", rev="4d3a513", env="prod", job="cluster-manager"}
instance_cpu_time_ns{app="fox", proc="widget", rev="4d3a513", env="prod", job="cluster-manager"}
...
我们可以得到按应用程序(app)和进程类型(proc)分组的前 3 个 CPU 用户,就像这样:
topk(3, sum by (app, proc) (rate(instance_cpu_time_ns[5m])))
查询语句详细分析:
instance_cpu_time_ns[5m]: 这部分选择了一个名为 instance_cpu_time_ns 的指标,并在过去 5 分钟的时间范围内抓取了这个指标的数据。
rate(instance_cpu_time_ns[5m]): 使用 rate 函数计算 instance_cpu_time_ns 指标在过去 5 分钟内的平均增长率。rate 函数通常用于计算计数器(Counter)类型指标的平均增长率,以获取一个类似速率的值。
sum by (app, proc): 这部分使用 sum 聚合操作符对 rate 函数的结果进行聚合,并按 app 和 proc 标签进行分组。这意味着它会计算每个 app 和 proc 组合的平均 CPU 时间增长率的总和。
topk(3, ...): 最后,topk 函数被用来从聚合结果中选择最大的 3 个样本。这些样本将基于 sum by (app, proc) 计算出的总和值进行排序,最大的 3 个值将被返回。
综上所述,整个查询的目的是找出在过去 5 分钟内,按 app 和 proc 分组后,CPU 时间增长率总和最高的前 3 个 app 和 proc 组合。
如果 instance_cpu_time_ns 指标包含每个运行实例的一个时间序列,则可以像这样计算每个应用程序的运行实例数:
count by (app) (instance_cpu_time_ns)
查询语句详细分析:
综上所述,整个查询将返回一个向量,其中的每个样本都包含一个 app 标签和对应的样本数量,表示有多少个时间序列具有相同的 app 标签值。

 川公网安备51010802032098
川公网安备51010802032098