什么是监督学习?本文用最简单的 “猫狗识别” 例子,通俗易懂讲解监督学习原理、基本流程、核心思想、分类(分类任务与回归任务)、常见算法、损失函数与优化,以及监督学习优缺点和与无监督、强化学习的区别,零基础也能快速看懂。
在快速了解机器学习中介绍了机器学习的分类,其中就包含监督学习,下面将简单聊一聊监督学习(Supervised Learning)。
监督学习是机器学习中最基础、应用最广泛的一类方法,核心是:用已标注的数据教模型学会从输入预测输出。
举例说明:教 AI 识别“猫”和“狗”
第一步:给模型提供带标注的训练数据
我们先给模型输入大量已经标注好答案的图片,这就是监督学习里的标注数据:
图片 1:这是猫 🐱
图片 2:这是狗 🐶
图片 3:这是猫 🐱
图片 4:这是狗 🐶
…… 以此类推,提供成千上万张带标签的图片。
第二步:模型进行训练
模型会像学生一样,从这些数据中总结规律。
表面上看,它学到的是:
耳朵尖、脸圆、体型偏小 → 更可能是猫
嘴巴长、耳朵垂、体型偏大 → 更可能是狗
而在底层实现上,模型会把每张图片转换成一组高维特征向量,比如 768 维、1024 维、1536 维等,用这些数字维度来保存和区分猫与狗的特征。
第三步:对新图片进行预测
当训练完成后,我们给模型一张从未见过的动物照片。
模型会先把这张图片也转换成特征向量,再和之前学到的规律进行比对:
注意,这里与之前学到的猫与狗特征进行对比,实际就是计算两个向量的相识度。
向量相似度,就是用数学方法计算两个向量有多像:
模型分类时,本质就是:把新图片的向量,和“猫向量”、“狗向量”比相似度,谁高就判谁。
最常用的两种相识度算法:
(1)欧氏距离(Euclidean Distance):欧氏距离就是高维空间里两点之间的直线距离 ,在大模型、向量检索、聚类里最常用。注意,距离越小 = 越相似。
(2)余弦相似度(Cosine Similarity):余弦相似度是向量检索、大模型 Embedding 里最常用的相似度指标。计算两个向量在方向上的相似程度,忽略向量长度(模长)。实际上是看两个向量的夹角,夹角越小,余弦值越接近。取值范围为 [-1, 1],
如果等于 1:完全同向,最相似
如果等于 0:正交,不相关
如果等于 -1:完全反向,最不相似
监督学习核心思想
监督学习的核心思想可以简单概括为三点:
(1)给模型提供大量带有标准答案的样本数据,每组数据都包含输入信息和对应的正确输出结果。
(2)模型通过学习,自动找出输入与输出之间的内在规律和映射关系,把这些规律以特征向量、权重参数等形式保存在模型内部。
(3)当训练完成后,即使遇到从未见过的全新输入,模型也能依靠学到的规律,自动推理并预测出对应的输出结果。
监督学习关键要素
监督学习的关键要素主要包含以下四点:
(1)特征(Feature / X):指模型接收的输入信息,是用于预测的依据。例如:身高、年龄、图片像素、文本内容等,都会被转化为模型可识别的数据特征。
(2)标签(Label / Y):对应每个输入的标准答案,是模型学习的目标。例如:预测的价格、分类的类别、是否患病的判断结果等。
(3)数据集:由大量特征与标签一一对应的样本对(X, Y)组成,是模型学习规律的基础素材。
(4)目标:通过不断学习,让模型的预测结果尽可能接近真实标签,从而实现准确、可靠的预测能力。
一句话总结:就像老师教学生做题,给例题 + 答案,反复练习,最后会做新题。
监督学习分类
监督学习根据输出结果的类型,主要分为两大类:分类任务和回归任务。
分类任务(Classification)
分类任务是监督学习中非常核心的一类任务,它的目标非常明确:模型根据输入信息,从预先定义好的若干个固定类别中,判断该输入最终归属到哪一个或哪几个类别。
简单理解:分类任务解决的是 “这是什么”“属于哪一类” 的问题。
存在以下分类:
(1)二分类:只有两个结果,例如:是 / 否、正 / 负、垃圾邮件 / 正常邮件
(2)多分类:有三个及以上结果,例如:猫 / 狗 / 鸟、晴天 / 阴天 / 雨天
(3)多标签分类:一个输入对应多个标签,例如:一张图片同时包含 “人”“车”“树”
分类常用于:图像识别、垃圾邮件过滤、情感分析、疾病诊断等。
回归任务(Regression)
回归任务是监督学习中另一大类核心任务,它的目标是:根据输入信息,预测一个连续的数值结果。分类任务回答“是什么类别”,回归任务回答“具体是多少”。
回归任务常见类型包括:
线性回归:输入和输出大致呈线性关系,是最基础、最常用的回归模型。
非线性回归:输入和输出呈曲线关系,更贴近现实复杂场景。
多变量回归:同时使用多个特征(如面积、地段、楼层)来预测一个结果(房价)。
回归任务典型例子如下:
房价预测:根据房屋面积、地段、房龄,预测具体价格
气温预测:根据湿度、气压、风速,预测具体温度
销量预测:根据广告投入、季节、价格,预测具体销量
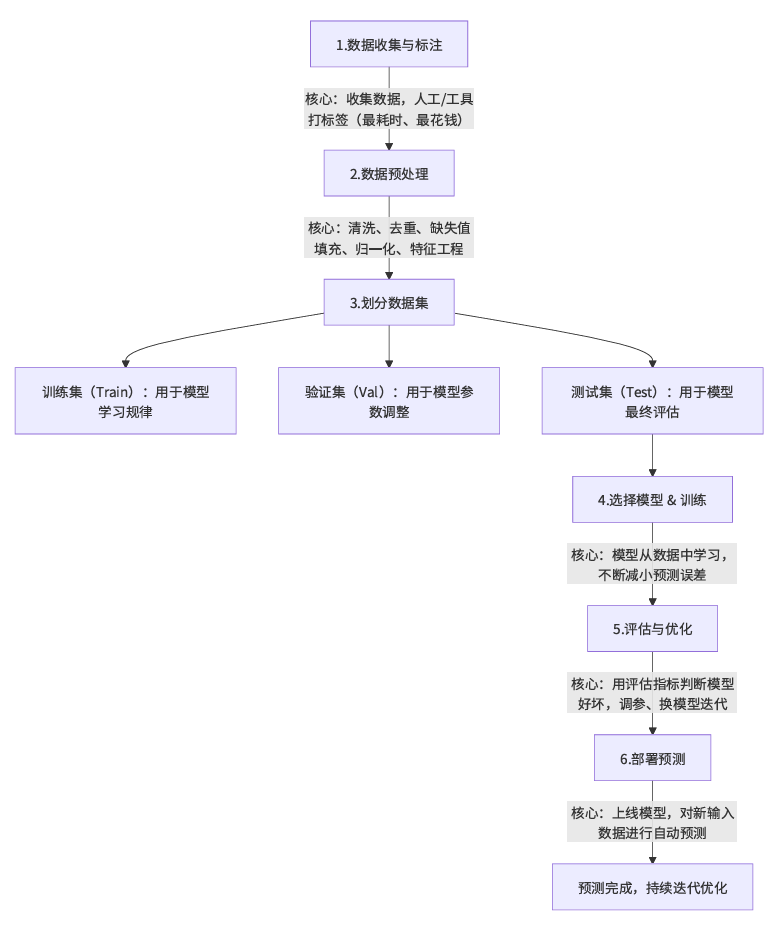
监督学习基本流程
下图是标准版本的监督学习基本流程:
常见监督学习算法
传统经典算法
线性回归(Linear Regression)—— 回归
逻辑回归(Logistic Regression)—— 分类
K 近邻(KNN)
决策树 / 随机森林 / XGBoost、LightGBM
支持向量机(SVM)
朴素贝叶斯(Naive Bayes)
深度学习(也属于监督)
监督学习的核心:损失函数 & 优化
监督学习的本质,就是让模型的输出不断靠近真实标签,而实现这一过程的两大核心就是:损失函数与优化算法。
损失函数(Loss Function)
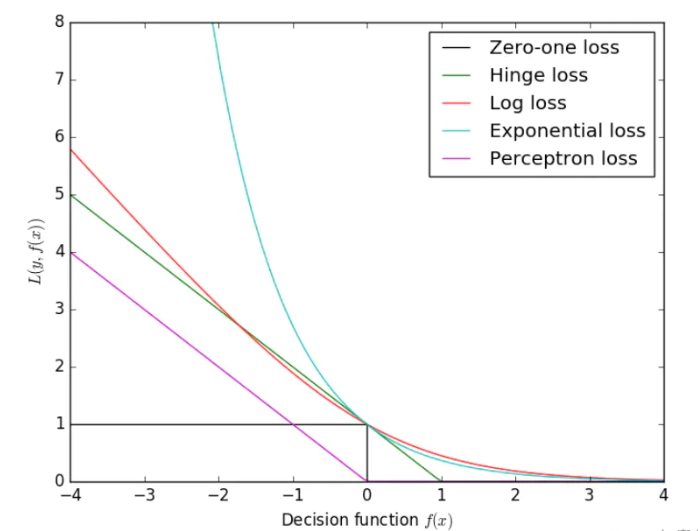
损失函数是监督学习里的“评判标准”,用来量化模型预测值与真实标签之间的差距。
预测越准 → 损失值越小
预测偏差越大 → 损失值越大
可以简单理解为损失函数就是模型当前犯了多少错。
损失函数的意义是把“学得好不好”从模糊感受变成可计算的数值。为后续优化提供明确方向。
注意,模型的目标只需要一个 —— 最小化损失。
优化(Optimization)
优化的目标是最小化整体损失(Loss),让模型输出尽可能接近真实结果。
优化的基本思路:
(1)前向传播:输入数据 → 模型给出预测 → 计算 Loss
(2)反向传播:根据 Loss 计算梯度,告诉模型每个参数该怎么改
(3)更新参数:沿着梯度下降的方向,微调权重
(4)反复迭代:不断重复,直到 Loss 收敛到较低水平
关键算法:梯度下降
梯度下降是监督学习中最核心的优化算法,核心目标是通过迭代更新模型参数,让损失函数(Loss)逐步逼近最小值,从而让模型预测更准确。
简单地说,梯度下降就像下山,每次都往最陡的下坡方向走,直到走到谷底(最小损失)
监督学习的优点 & 缺点
优点
(1)思想直观易懂,学习门槛较低:监督学习的核心逻辑清晰直白 —— 通过标注数据指导模型学习输入与输出的映射关系,原理简单易懂,无论是入门学习还是工程落地,都更容易被理解和掌握。
(2)效果可控稳定,可解释性较强:模型训练过程、预测结果与数据特征高度关联,效果可预期、可调控;尤其在逻辑回归、决策树等传统机器学习模型中,特征权重、决策路径都能清晰追溯,可解释性远优于多数无监督与强化学习方法。
(3)应用成熟落地,工业界主流首选:经过长期发展与验证,监督学习在分类、回归、预测等场景中技术体系完善、工具链丰富、落地案例极多,是互联网、金融、医疗、安防等行业最常用的机器学习方案。
缺点
(1)高度依赖高质量标注数据,数据瓶颈明显:模型效果直接取决于数据质量,缺少精准、足量的标注数据就难以训练出可靠模型,对数据的依赖性远高于其他学习范式。
(2)标注成本高昂,周期冗长:高质量标注需要专业人力审核与校对,人力、时间、资金成本高,复杂场景下的数据标注更是耗时费力,极大限制了模型快速迭代。
(3)泛化能力存在上限,难以突破已知模式:监督学习本质是对已有标注数据的模式拟合与归纳,只能学习“见过”的样本规律,无法自主发现未知知识与全新模式,面对未见过的场景时泛化能力受限。
与无监督/强化学习的区别
下表列举了监督学习、无监督学习和强化学习的区别:
| 类型 | 数据有无标签 | 目标 |
| 监督学习 | 有 | 预测 X→Y |
| 无监督学习 | 无 | 找数据结构、聚类、降维 |
| 强化学习 | 无标签,有奖励 | 学习动作序列最大化奖励 |






 川公网安备51010802032098
川公网安备51010802032098