本文详解 Ollama 结构化输出方法,演示如何通过 cURL、Python 和 JavaScript 调用 API 生成一致 JSON 格式。介绍使用 JSON Schema、Pydantic 和 Zod 强制模型输出结构,实现可靠的数据提取与图像描述,适合开发者快速集成大模型应用。
结构化输出是指让大模型输出我们期待的格式,如让大模型输出 JSON 格式或其他格式,这样我们就可以通过代码来解析这些格式,从中提取数据,从而实现业务需要。通常,我们让大模型输出 JSON 格式(尽量保证每次都输出结构一致的格式)的字符串,然后通过 JSON 库轻松都能解析。例如,从用户输入的内容中提取表单数据,或者从一段文本中提取关键信息,如标题、日期、价格等等,最终形成表单。
而且,结构化输出还允许你在模型响应上强制执行 JSON 模式(有点类似 XML 中的 Schema,定义了 JSON 格式,保证每次输出的 JSON 格式一致),这样你就可以可靠地提取结构化数据、描述图像,或者让每一个回复保持一致。
下面将演示使用 Ollama 进行结构化输出。
准备环境
在本地安装 Ollama 软件,然后运行 ollama pull qwen3:4b-thinking 命令下载 qwen3:4b-thinking 模型,然后通过 ollama run qwen3:4b-thinking 命令运行模型。
详情请参考:
教你如何使用 Ollama 在本机运行大模型
Ollama 快速入门
Ollama 流式传输的环境准备
生成结构化的JSON
下面将分别介绍通过 cURL、Python 和 JavaScript 方式调用 Ollama 服务,生成结构化 JSON:
cURL
curl(全称 Client URL)是一款开源、跨平台的命令行工具与数据传输库,用于基于 URL 语法在网络上传输数据,支持数十种网络协议,是开发者、运维人员必备的网络调试与自动化利器。
注意,Windows 的命令窗口不支持单引号 ' 包裹 JSON,必须用 双引号 ",且 JSON 内部的双引号要转义。下面是 Linux 语句:
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "gpt-oss",
"messages": [{"role": "user", "content": "用一句话介绍一下加拿大"}],
"stream": false,
"format": "json"
}'
Windows 下面:
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d "{\"model\": \"qwen3:4b-thinking\",\"messages\": [{ \"role\": \"user\", \"content\": \"用一句话介绍一下加拿大\"}],\"stream\": false,\"format\": \"json\"}"
运行结果:
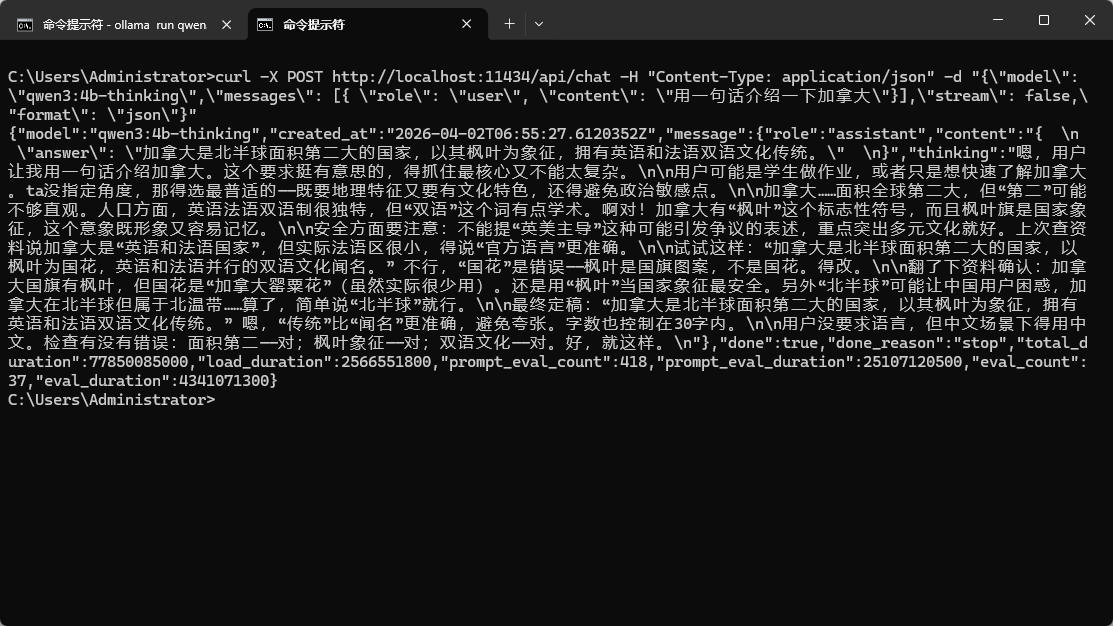
将上面的回复进行格式化,如下:
{
"model": "qwen3:4b-thinking",
"created_at": "2026-04-02T06:55:27.6120352Z",
"message": {
"role": "assistant",
"content": "{ \n \"answer\": \"加拿大是北半球面积第二大的国家,以其枫叶为象征,拥有英语和法语双语文化传统。\" \n}",
"thinking": "嗯,用户让我用一句话介绍加拿大。这个要求挺有意思的,得抓住最核心又不能太复杂。\n\n用户可能是学生做作业,或者只是想快速了解加拿大。ta没指定角度,那得选最普适的——既要地理特征又要有文化特色,还得避免政治敏感点。\n\n加拿大……面积全球第二大,但“第二”可能不够直观。人口方面,英语法语双语制很独特,但“双语”这个词有点学术。啊对!加拿大有“枫叶”这个标志性符号,而且枫叶旗是国家象征,这个意象既形象又容易记忆。\n\n安全方面要注意:不能提“英美主导”这种可能引发争议的表述,重点突出多元文化就好。上次查资料说加拿大是“英语和法语国家”,但实际法语区很小,得说“官方语言”更准确。\n\n试试这样:“加拿大是北半球面积第二大的国家,以枫叶为国花,英语和法语并行的双语文化闻名。” 不行,“国花”是错误——枫叶是国旗图案,不是国花。得改。\n\n翻了下资料确认:加拿大国旗有枫叶,但国花是“加拿大罂粟花”(虽然实际很少用)。还是用“枫叶”当国家象征最安全。另外“北半球”可能让中国用户困惑,加拿大在北半球但属于北温带……算了,简单说“北半球”就行。\n\n最终定稿:“加拿大是北半球面积第二大的国家,以其枫叶为象征,拥有英语和法语双语文化传统。” 嗯,“传统”比“闻名”更准确,避免夸张。字数也控制在30字内。\n\n用户没要求语言,但中文场景下得用中文。检查有没有错误:面积第二——对;枫叶象征——对;双语文化——对。好,就这样。\n"
},
"done": true,
"done_reason": "stop",
"total_duration": 77850085000,
"load_duration": 2566551800,
"prompt_eval_count": 418,
"prompt_eval_duration": 25107120500,
"eval_count": 37,
"eval_duration": 4341071300
}
看见了吗,message.content 内容就是一个 JSON 字符串,注意自己处理 \n 等符号。
Python
先使用 pip install ollama 安装 ollama 依赖,再运行代码如下:
from ollama import chat
response = chat(
model='gpt-oss',
messages=[{'role': 'user', 'content': '和我说说加拿大。'}],
format='json'
)
print(response.message.content)
运行结果:
$ python .\ollama_example2.py
{"answer": "好的!我来和你聊聊加拿大,这个北美的国家可是个超有特色的宝藏地儿~ 😄\n\n**1️⃣ 位置和基....和中国的联系?我可以再详细说~ 😊"}
JavaScript
先使用 npm install ollama 安装依赖,再运行如下代码:
// 导入依赖
import ollama from 'ollama'
const response = await ollama.chat({
model: 'qwen3:4b-thinking',
// 消息内容
messages: [{ role: 'user', content: '和我说说加拿大。' }],
format: 'json'
})
console.log(response.message.content)
运行结果:
$ node .\ollama_example2.js
{"role": "assistant", "content": "哈哈,你问加拿大啊!我来给......你挖得更细! 😄"}
注意,上面返回的格式和 Python、cURL 方式不同。至少 message.content 中依然是一个 JSON 字符串。
使用模式生成结构化JSON
前面我们仅向 format 字段提供了“json”字符串,而使用模式生成结构化 JSON 则是将一个 JSON 模式设置给 format 字段。
注意,理想情况下,我们还应在提示词中将 JSON 模式作为字符串进行传递,以确保模型的响应始终符合要求。
下面依然分别通过 cURL、Python 和 JavaScript 方式进行演示:
cURL
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwen3:4b-thinking",
"messages": [{"role": "user", "content": "和我讲讲加拿大。"}],
"stream": false,
"format": {
"type": "object",
"properties": {
"name": {"type": "string"},
"capital": {"type": "string"},
"languages": {
"type": "array",
"items": {"type": "string"}
}
},
"required": ["name", "capital", "languages"]
}
}'
如果在 Windows 中运行如下命令,请先将语句转换成符合 Windows 执行的语法,
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d "{\"model\": \"qwen3:4b-thinking\",\"messages\": [{\"role\": \"user\", \"content\": \"和我讲讲加拿大。\"}],\"stream\": false,\"format\": {\"type\": \"object\",\"properties\": {\"name\": {\"type\": \"string\"},\"capital\": {\"type\": \"string\"},\"languages\": {\"type\": \"array\",\"items\": {\"type\": \"string\"}}},\"required\": [\"name\", \"capital\", \"languages\"]}}"
运行结果:
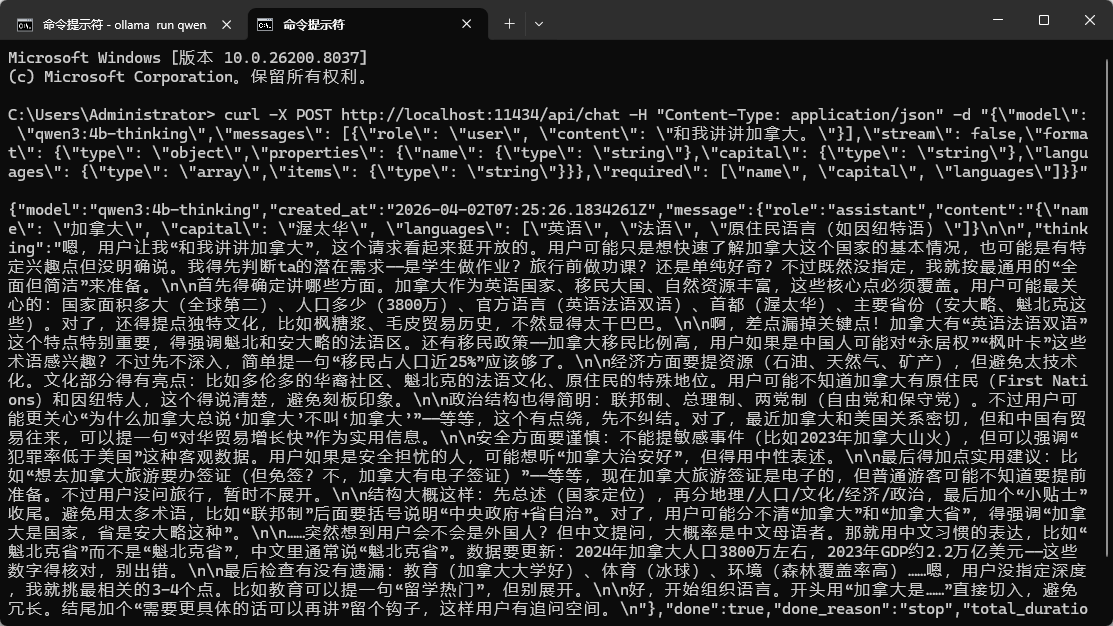
内容格式化后如下:
{
"model": "qwen3:4b-thinking",
"created_at": "2026-04-02T07:25:26.1834261Z",
"message": {
"role": "assistant",
"content": "{\"name\": \"加拿大\", \"capital\": \"渥太华\", \"languages\": [\"英语\", \"法语\", \"原住民语言(如因纽特语)\"]}\n\n",
"thinking": "嗯,用户让我“和我讲讲加拿大”,这.....讲”留个钩子,这样用户有追问空间。\n"
},
"done": true,
"done_reason": "stop",
"total_duration": 225271201500,
"load_duration": 102076400,
"prompt_eval_count": 828,
"prompt_eval_duration": 86081364200,
"eval_count": 42,
"eval_duration": 6556566300
}
Python
Pydantic 是一个用于 Python 的数据验证与解析库,通过类型注解自动校验数据格式、保证类型安全,并能轻松实现对象与 JSON 互转。
使用 Pydantic 模型,并将 model_json_schema() 传递给 format,然后验证响应:
注意:运行前记得使用 pip install ollama 和 pip install pydantic 命令安装依赖库。
# 导入 ollama 的 chat 函数
from ollama import chat
# 导入 Pydantic 基类 BaseModel,定义结构化数据模型,让 AI 必须按这个格式返回
from pydantic import BaseModel
# 定义结构化数据模型
# 告诉AI:必须返回包含 name、capital、languages 三个字段的 JSON 格式
class Country(BaseModel):
name: str # 国家名称(字符串类型)
capital: str # 首都(字符串类型)
languages: list[str] # 官方语言(字符串列表)
# 调用 AI,并强制返回固定 JSON 结构
# format 参数 = 让模型严格按照 Country 结构输出
response = chat(
model='qwen3:4b-thinking', # 使用带思考能力的 qwen3 模型
messages=[{'role': 'user', 'content': '和我讲讲加拿大。'}],
# 让 AI 严格按照 Country 模型输出 JSON
# model_json_schema() → 把 Pydantic 模型转成 AI 能识别的 JSON 格式规则
format=Country.model_json_schema(),
)
# 把 AI 返回的字符串自动转成 Python 对象
country = Country.model_validate_json(response.message.content)
print(country)
运行结果:
$ python .\ollama_example3.py
name='加拿大' capital='渥太华' languages=['英语', '法语', '原住民语言(如因纽特语)', '其他小语种(如魁北克法语)']
JavaScript
使用 zodToJsonSchema() 序列化 Zod 模式并解析结构化响应,先执行下面命令安装依赖:
npm install zod@3.23.8 zod-to-json-schema@3.23.0
注意,如果 zod 和 zod-to-json-schema 版本不匹配会直接导致 zodToJsonSchema(Country) 输出空结构,最终导致模型调用失败。
再运行代码:
import ollama from 'ollama'
import { z } from 'zod'
import { zodToJsonSchema } from 'zod-to-json-schema'
const Country = z.object({
name: z.string(),
capital: z.string(),
languages: z.array(z.string()),
})
const response = await ollama.chat({
model: 'gpt-oss',
messages: [{ role: 'user', content: '和我讲讲加拿大。' }],
format: zodToJsonSchema(Country),
})
const country = Country.parse(JSON.parse(response.message.content))
console.log(country)
运行结果:
{ name: '加拿大', capital: '渥太华', languages: [ '英语', '法语(魁北克省)' ] }
更多示例
提取结构化数据
使用 pydantic 的 BaseModel 定义你想要返回的对象,然后让模型填充这些字段,代码如下:
from ollama import chat
from pydantic import BaseModel
# 定义宠物的数据模型
class Pet(BaseModel):
# 宠物名称
name: str
# 动物种类
animal: str
# 宠物年龄
age: int
# 宠物颜色
color: str | None
# 宠物最喜欢的玩具
favorite_toy: str | None
class PetList(BaseModel):
pets: list[Pet]
response = chat(
model='qwen3:4b-thinking',
messages=[{'role': 'user',
'content': '我有两只猫,分别叫露娜和洛基。露娜喜欢玩毛线球,洛基喜欢玩逗猫棒。露娜是黑色的,洛基是灰色的。露娜3岁了,洛基2岁了。'}],
# 指定输出格式为PetList模型的JSON结构,让模型按该结构返回数据
format=PetList.model_json_schema(),
)
# 将模型返回的JSON格式内容,校验并转换为PetList对象
pets = PetList.model_validate_json(response.message.content)
print(pets)
运行结果:
$ python .\ollama_example4.py
pets=[Pet(name='露娜', animal='猫', age=3, color='黑色', favorite_toy='毛线球'), Pet(name='洛基', animal='猫', age=2, color='灰色', favorite_toy='逗猫棒')]
具有结构化输出的视觉功能
视觉模型也接受相同的 format 参数,从而能够对图像进行确定性描述,代码如下:
from ollama import chat
from pydantic import BaseModel
from typing import Literal, Optional
# 定义识别到的物体数据模型,描述图片中单个物体的信息
class Object(BaseModel):
# 物体名称(如:猫、杯子、桌子)
name: str
# 识别置信度(0~1之间的浮点数,表示AI识别的准确程度)
confidence: float
# 物体属性描述(如:颜色、材质、状态)
attributes: str
# 定义图片整体描述数据模型
class ImageDescription(BaseModel):
# 图片整体摘要/一句话描述
summary: str
# 图片中识别到的所有物体列表(多个Object对象)
objects: list[Object]
# 场景类型(如:客厅、街道、森林)
scene: str
# 图片主色调列表
colors: list[str]
# 时间段:只能是指定的4个值之一(Morning/Afternoon/Evening/Night)
time_of_day: Literal['Morning', 'Afternoon', 'Evening', 'Night']
# 环境:只能是 Indoor/Outdoor/Unknown 三种之一
setting: Literal['Indoor', 'Outdoor', 'Unknown']
# 图片中的文字内容(可选字段,没有文字时为None)
text_content: Optional[str] = None
response = chat(
model='gemma3',
messages=[{
'role': 'user',
'content': '描述这张照片并列出你识别到的物体。',
'images': ['path/to/image.jpg'],
}],
format=ImageDescription.model_json_schema(),
#temperature=0 表示结果固定、确定性最高、无随机性
options={'temperature': 0},
)
# 将AI返回的JSON字符串,校验并转换为ImageDescription对象
image_description = ImageDescription.model_validate_json(response.message.content)
print(image_description)
我们常常听人说,人们因工作过度而垮下来,但是实际上十有八九是因为饱受担忧或焦虑的折磨。 —— 卢伯克.J.






 川公网安备51010802032098
川公网安备51010802032098