LinkedHashMap 是 Java 集合框架中一种特殊的 Map 实现,它继承自 HashMap 并实现了 Map 接口。与 HashMap 相比,LinkedHashMap 最大的特点是能够维护键值对的插入顺序或访问顺序,同时保留了 HashMap 的哈希表特性,兼具有序性和高效性。
LinkedHashMap 重要特性
有序性:
默认按插入顺序维护键值对(即迭代顺序与插入顺序一致)。
可通过构造方法指定为访问顺序(最近访问的元素放在末尾,适合实现 LRU 缓存)。
有序性通过内部维护的双向链表实现,每个节点记录前驱和后继引用。
存储结构:
底层采用「哈希表(数组 + 链表 / 红黑树) + 双向链表」的混合结构。
哈希表用于保证查询、插入、删除的高效性(平均时间复杂度 O (1))。
双向链表用于维护键值对的顺序,额外空间开销略高于 HashMap。
继承关系与兼容性:
非线程安全:
LinkedHashMap 构造方法
LinkedHashMap 提供了 5 种构造方法:
LinkedHashMap()
LinkedHashMap(int initialCapacity)
LinkedHashMap(int initialCapacity, float loadFactor)
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
initialCapacity:初始桶数量。
loadFactor:加载因子。
accessOrder:排序模式开关:
LinkedHashMap(Map<? extends K,? extends V> m)
LinkedHashMap 关键方法与扩展
除了继承自 HashMap 的所有方法,LinkedHashMap 有两个核心方法:
void afterNodeInsertion(boolean evict)
protected boolean removeEldestEntry(Map.Entry<K, V> eldest)
什么是 LRU?
LRU(Least Recently Used,最近最少使用)是一种经典的缓存淘汰策略,核心思想是:当缓存空间满时,优先淘汰「最久未被使用」的元素,保留「最近被使用」的元素。这种策略基于 “近期使用过的元素,未来更可能被再次使用” 的假设,在实际场景中(如内存缓存、数据库查询缓存等)应用广泛。
LRU 的核心原理
LRU 的工作流程示例
假设缓存容量为 3,模拟操作过程:
操作步骤 | 缓存内容(按 “最近使用” 排序,右侧为最新) | 说明 |
1. 放入 A | [A] | 缓存空,直接放入 |
2. 放入 B | [A, B] | 容量未满,B 成为最新 |
3. 放入 C | [A, B, C] | 容量满,C 成为最新 |
4. 访问 B | [A, C, B] | B 被使用,成为最新 |
5. 放入 D | [C, B, D] | 容量超 3,淘汰最久未用的 A |
6. 访问 C | [B, D, C] | C 被使用,成为最新 |
7. 放入 E | [D, C, E] | 容量超 3,淘汰最久未用的 B |
通过上述流程可见,每次操作后,“最近使用” 的元素会被 “置顶”(移到序列末尾),满容量时淘汰最左侧(最久未用)的元素。
java 广告位
LinkedHashMap 使用示例
插入顺序示例
下面是 LinkedHashMap 保持插入顺序的示例代码,展示了它与普通 HashMap 在迭代顺序上的区别:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
// 按插入顺序排序(默认)
LinkedHashMap<String, Integer> insertOrderMap = new LinkedHashMap<>();
insertOrderMap.put("one", 1);
insertOrderMap.put("two", 2);
insertOrderMap.put("three", 3);
insertOrderMap.put("four", 4);
// 迭代顺序与插入顺序一致
System.out.println("插入顺序迭代:");
for (Map.Entry<String, Integer> entry : insertOrderMap.entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
}
运行结果:
插入顺序迭代:
one=1
two=2
three=3
four=4
注意,LinkedHashMap 本身不支持自定义排序,它的核心特性是保持插入顺序或访问顺序(通过构造参数控制),无法像 TreeMap 那样通过 Comparator 自定义排序规则。
如果需要自定义排序逻辑,应该使用 TreeMap;
如果需要按访问顺序排序(最近访问的元素放在最后),可以使用带参数的构造方法:
// 第三个参数为 true 表示按访问顺序排序
Map<String, Integer> accessOrderedMap = new LinkedHashMap<>(16, 0.75f, true);
访问顺序与 LRU 缓存示例
LinkedHashMap 除了默认的插入顺序,还支持访问顺序(通过构造参数 accessOrder = true 启用),这一特性非常适合实现 LRU(Least Recently Used,最近最少使用)缓存。
注意,当 LinkedHashMap 以 accessOrder = true 初始化时:
利用 LinkedHashMap 的访问顺序特性,结合重写 removeEldestEntry() 方法,可以实现自动淘汰「最久未使用」元素的 LRU 缓存:
下面示例实现了最大容量的 LRU,会自动移除最久未访问的元素:
import java.util.LinkedHashMap;
import java.util.Map;
// 实现简单的 LRU 缓存(最多存储 3 个元素)
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int maxSize;
public LRUCache(int maxSize) {
// 初始容量16,加载因子0.75,按访问顺序排序
super(16, 0.75f, true);
this.maxSize = maxSize;
}
// 当元素数量超过maxSize时,自动移除最久未访问的元素
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
}
public class LRUExample {
public static void main(String[] args) {
LRUCache<String, Integer> cache = new LRUCache<>(3);
cache.put("a", 1);
cache.put("b", 2);
cache.put("c", 3);
System.out.println("初始缓存:" + cache.keySet()); // [a, b, c]
cache.get("a"); // 访问"a",使其成为最近访问的元素
System.out.println("访问a后:" + cache.keySet()); // [b, c, a]
cache.put("d", 4); // 超过容量,移除最久未访问的"b"
System.out.println("添加d后:" + cache.keySet()); // [c, a, d]
}
}
运行结果:
初始缓存:[a, b, c]
访问a后:[b, c, a]
添加d后:[c, a, d]
与 HashMap、TreeMap 的对比
特性 | LinkedHashMap | HashMap | TreeMap |
有序性 | 插入顺序或访问顺序 | 无序 | 自然顺序或比较器顺序 |
底层结构 | 哈希表 + 双向链表 | 哈希表+链表/红黑树 | 红黑树 |
查找效率 | 平均 O (1) | 平均 O (1) | O(log n) |
空间开销 | 较高(维护链表) | 中等 | 较高(树结构) |
适用场景 | 需要保持顺序或实现 LRU 缓存 | 常规键值映射(无序) | 需要排序的映射场景 |
LinkedHashMap 原理分析
LinkedHashMap 是 HashMap 的子类,在 HashMap 哈希表结构的基础上,通过维护一个双向链表记录节点的访问 / 插入顺序,从而实现 “有序” 特性。
其核心原理可概括为:哈希表保证高效存取,双向链表保证顺序性。
类结构与核心字段
LinkedHashMap 继承自 HashMap,并新增了与双向链表相关的字段:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
// 双向链表的头节点(最久访问/最早插入)
transient LinkedHashMap.Entry<K,V> head;
// 双向链表的尾节点(最近访问/最晚插入)
transient LinkedHashMap.Entry<K,V> tail;
// 排序模式:true=访问顺序,false=插入顺序(默认)
final boolean accessOrder;
}
其中,LinkedHashMap.Entry 是对 HashMap.Node 的扩展,新增了双向链表的指针:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 前驱、后继节点
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
结构示意图:
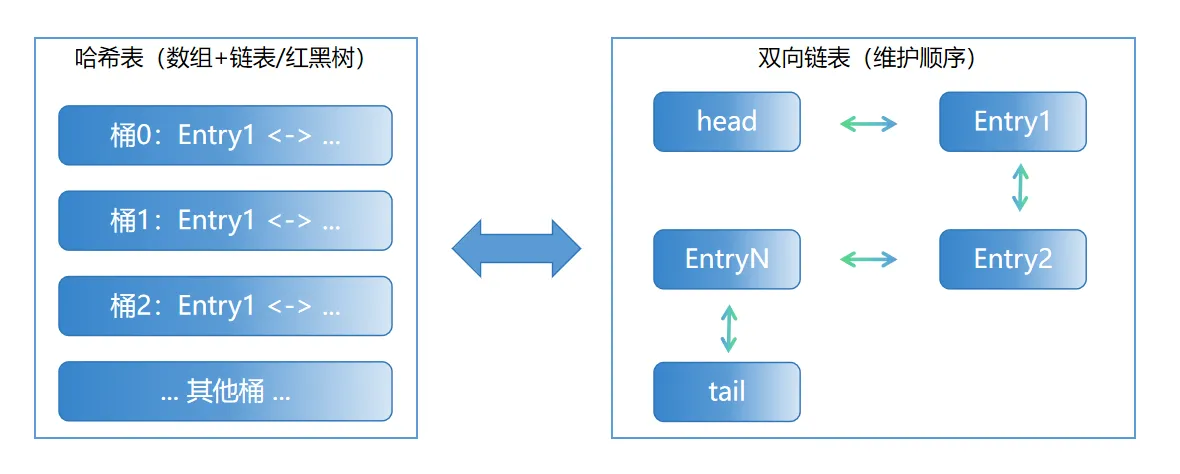
核心原理:双向链表的维护
LinkedHashMap 的“有序”特性完全依赖双向链表的维护,关键操作包括:节点插入时的链表追加、节点访问时的链表调整。
插入元素时的顺序维护(put 操作)
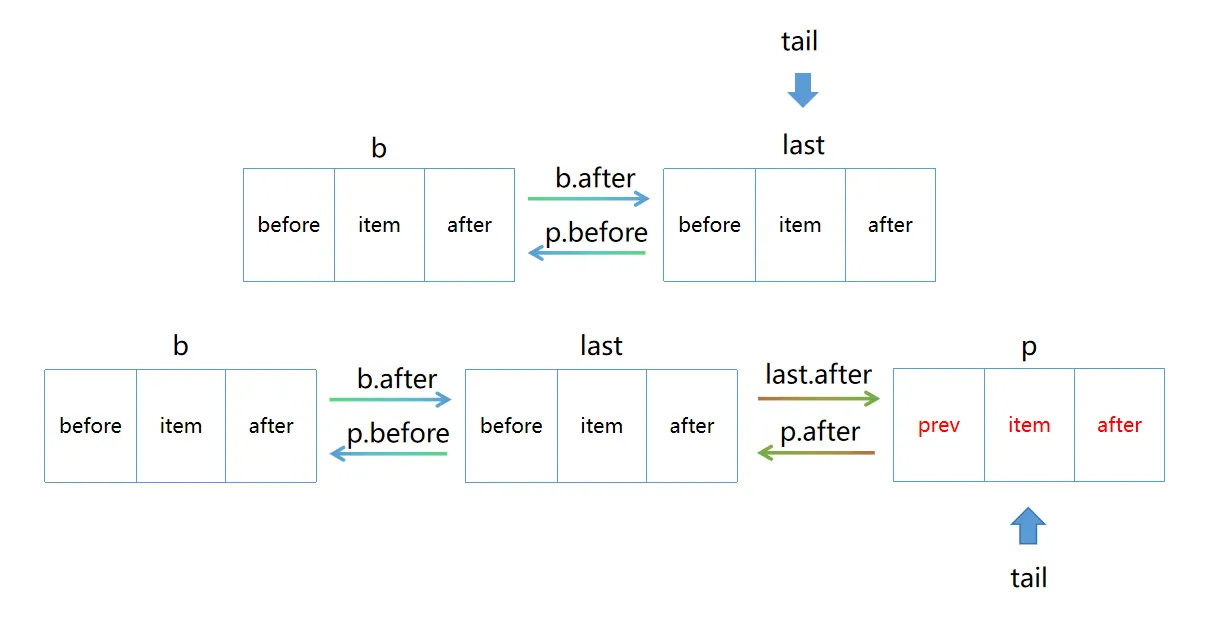
当调用 put 方法时,先执行 HashMap 的插入逻辑(计算哈希、定位桶位、处理哈希冲突),然后通过 linkNodeLast 方法将新节点追加到双向链表的尾部:
// 将新节点插入到双向链表的尾部,使其成为"最新"节点(无论是插入顺序还是访问顺序中,都是最近操作的节点)
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
// 保存当前链表的尾节点引用
LinkedHashMap.Entry<K,V> last = tail;
// 将新节点设为新的尾节点
tail = p;
// 如果原链表为空(尾节点为null),说明这是第一个节点
if (last == null)
// 头节点也指向该节点(链表中唯一节点)
head = p;
else {
// 新节点的前驱指针指向原尾节点
p.before = last;
// 原尾节点的后继指针指向新节点,完成双向链接
last.after = p;
}
// 执行后,新节点成为链表最后一个节点,保持了插入/访问的顺序性
}
如下图:
注意:
访问元素时的顺序维护(get 操作)
当调用 get 方法访问元素时,若开启 accessOrder = true,会触发 afterNodeAccess 方法,将当前节点移到链表尾部(标记为 “最近访问”):
void afterNodeAccess(Node<K,V> e) { // move node to last(将节点移到链表末尾)
LinkedHashMap.Entry<K,V> last; // 暂存当前链表的尾节点
// 只有在“访问顺序模式”且当前节点不是尾节点时,才需要调整位置
if (accessOrder && (last = tail) != e) {
// 将节点转换为LinkedHashMap.Entry类型(包含双向链表指针)
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e;
LinkedHashMap.Entry<K,V> b = p.before; // 保存当前节点的前驱节点
LinkedHashMap.Entry<K,V> a = p.after; // 保存当前节点的后继节点
// 步骤1:断开当前节点与后继节点的链接(当前节点将移到尾部,后继指针置空)
p.after = null;
// 步骤2:处理前驱节点与后继节点的链接(移除当前节点原位置的关联)
if (b == null) {
// 若当前节点是头节点(无前驱),则更新头节点为原后继节点
head = a;
} else {
// 若有前驱,将前驱的后继指向原后继节点
b.after = a;
}
// 步骤3:处理后继节点与前驱节点的链接
if (a != null) {
// 若有后继,将后继的前驱指向原前驱节点
a.before = b;
} else {
// 若当前节点是尾节点(无后继,理论上不会进入此分支,因为前面已判断last != e)
last = b;
}
// 步骤4:将当前节点插入到链表尾部(与原尾节点建立关联)
if (last == null) {
// 若链表为空(理论上不会发生,因为e是已存在的节点),则头节点设为当前节点
head = p;
} else {
// 原尾节点的后继指向当前节点,当前节点的前驱指向原尾节点
p.before = last;
last.after = p;
}
// 步骤5:更新尾节点为当前节点(当前节点成为新的尾节点,即“最近使用”)
tail = p;
// 增加修改计数器,用于快速失败机制(迭代时检测结构变化)
++modCount;
}
}
参考下图理解代码中如何断开连接:
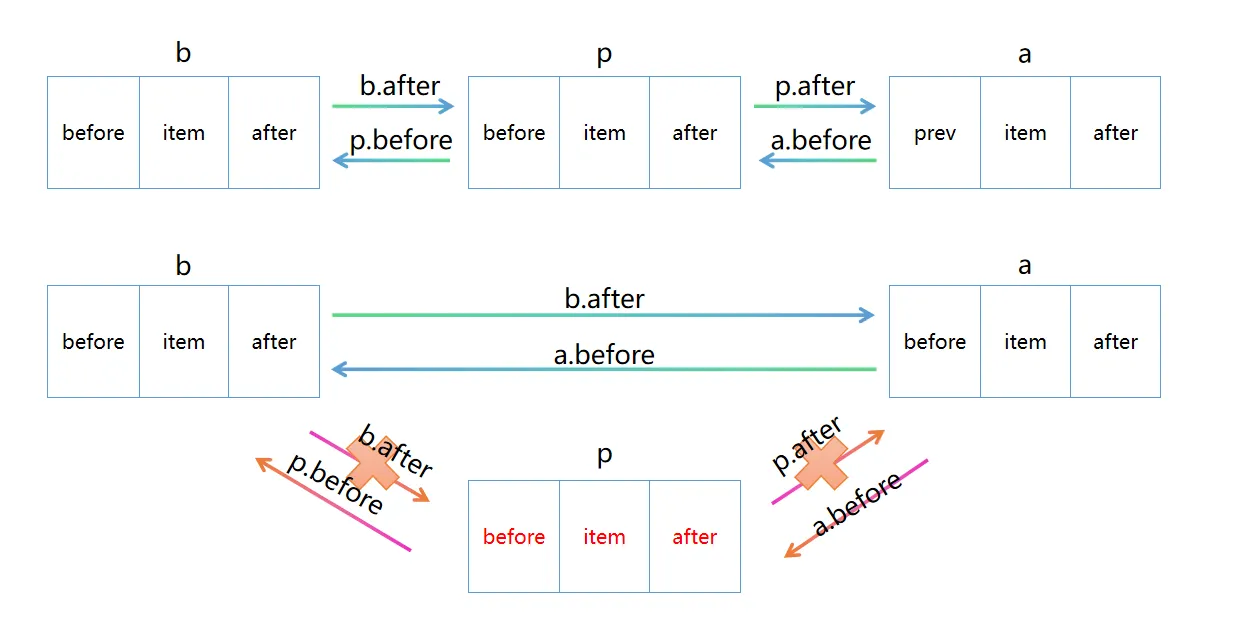
每次访问后,节点被移到链表尾部,链表头部自然成为 “最久未访问” 的节点,这是 LRU 缓存的核心逻辑。
删除元素时的链表维护
当节点被删除(如 remove 或 LRU 淘汰)时,afterNodeRemoval 方法会将节点从双向链表中移除,保证链表的完整性:
// 删除节点后,移除其在双向链表中的链接,保证链表的完整性
void afterNodeRemoval(Node<K,V> e) {
// 将节点转换为LinkedHashMap的Entry类型(包含before和after指针)
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e;
// 获取当前节点的前驱节点(before)
LinkedHashMap.Entry<K,V> b = p.before;
// 获取当前节点的后继节点(after)
LinkedHashMap.Entry<K,V> a = p.after;
// 断开当前节点与前后节点的链接(帮助GC回收)
p.before = p.after = null;
// 处理前驱节点的后继指针
if (b == null) {
// 若前驱为null,说明当前节点是头节点,更新头节点为后继节点
head = a;
} else {
// 否则,将前驱节点的after指向当前节点的后继节点
b.after = a;
}
// 处理后继节点的前驱指针
if (a == null) {
// 若后继为null,说明当前节点是尾节点,更新尾节点为前驱节点
tail = b;
} else {
// 否则,将后继节点的before指向当前节点的前驱节点
a.before = b;
}
}
迭代顺序的实现
LinkedHashMap 重写了 entrySet() 等方法,返回的迭代器通过遍历双向链表实现顺序输出,而非遍历哈希表的桶数组:
/**
* 抽象基类,封装 LinkedHashMap 所有迭代器的共同逻辑
* 负责基于双向链表进行顺序遍历,维护迭代状态和并发修改检查
*/
abstract class LinkedHashIterator {
// 下一个要返回的链表节点(初始指向链表头部)
LinkedHashMap.Entry<K,V> next;
// 当前正在处理的节点(用于 remove 操作)
LinkedHashMap.Entry<K,V> current;
// 迭代过程中预期的修改次数,用于检测并发修改
int expectedModCount;
/**
* 初始化迭代器状态
* 从双向链表的头部开始遍历,记录初始修改次数
*/
LinkedHashIterator() {
next = head; // 迭代起点为链表头节点(最久访问/最早插入的元素)
expectedModCount = modCount; // 记录当前集合的修改次数,用于后续校验
current = null; // 初始无当前节点
}
/**
* 判断是否还有下一个元素
* @return 若存在下一个节点则返回 true,否则 false
*/
public final boolean hasNext() {
return next != null; // 只要 next 不为 null,就还有元素未遍历
}
/**
* 获取下一个链表节点,并更新迭代状态
* 核心遍历逻辑:按双向链表的 after 指针顺序移动
* @return 下一个 Entry 节点
*/
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
// 检查并发修改:如果集合在迭代期间被修改(如 add/remove),则抛出异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// 如果没有下一个节点,抛出异常(hasNext() 为 false 时调用 next())
if (e == null)
throw new NoSuchElementException();
current = e; // 更新当前节点为即将返回的节点
next = e.after; // 移动到下一个节点(通过 after 指针,遵循链表顺序)
return e;
}
/**
* 移除当前迭代到的节点(需在 next() 之后调用)
* 依赖 LinkedHashMap 的 removeNode 方法实现,同时更新修改次数校验值
*/
public final void remove() {
Node<K,V> p = current;
// 如果当前节点为 null(未调用 next() 或已移除过),抛出异常
if (p == null)
throw new IllegalStateException();
// 检查并发修改
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null; // 标记当前节点已被移除,避免重复删除
// 调用 HashMap 的 removeNode 方法删除节点(会自动维护双向链表)
removeNode(p.hash, p.key, null, false, false);
expectedModCount = modCount; // 更新预期修改次数,与当前集合状态同步
}
}
/**
* 键(Key)迭代器:专门用于遍历 LinkedHashMap 的键集合
*/
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
/**
* 获取下一个键
* @return 下一个节点的 Key
*/
public final K next() { return nextNode().getKey(); }
}
/**
* 值(Value)迭代器:专门用于遍历 LinkedHashMap 的值集合
*/
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
/**
* 获取下一个值
* @return 下一个节点的 Value
*/
public final V next() { return nextNode().value; }
}
/**
* 键值对(Entry)迭代器:专门用于遍历 LinkedHashMap 的键值对集合
*/
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
/**
* 获取下一个键值对
* @return 下一个 Entry 节点
*/
public final Map.Entry<K,V> next() { return nextNode(); }
}
因此,迭代顺序严格遵循双向链表的顺序(插入顺序或访问顺序)。
LinkedHashMap 适用场景
下面是几个 LinkedHashMap 适用场景:
(1)需要维护插入顺序的场景:如日志记录、历史操作跟踪等,需按添加顺序处理键值对。
(2)LRU 缓存实现:通过访问顺序模式,可轻松实现「最近最少使用 LRU」缓存策略(如上述示例)。
(3)需要频繁迭代的场景:由于内部链表维护顺序,迭代效率高于 HashMap(无需遍历整个哈希表)。
注意:LinkedHashMap 是有序性与高效性的平衡选择,在需要顺序保证的场景中,性能通常优于 TreeMap,是 HashMap 的理想有序替代方案。
更多信息参考 https://docs.oracle.com/javase/8/docs/api/java/util/LinkedHashMap.html API 文档。

 川公网安备51010802032098
川公网安备51010802032098