数据类型是编程的基础,它定义了数据的存储方式和可执行的操作。
在 Python3 中,数据类型主要分为 6 大类,如下图:
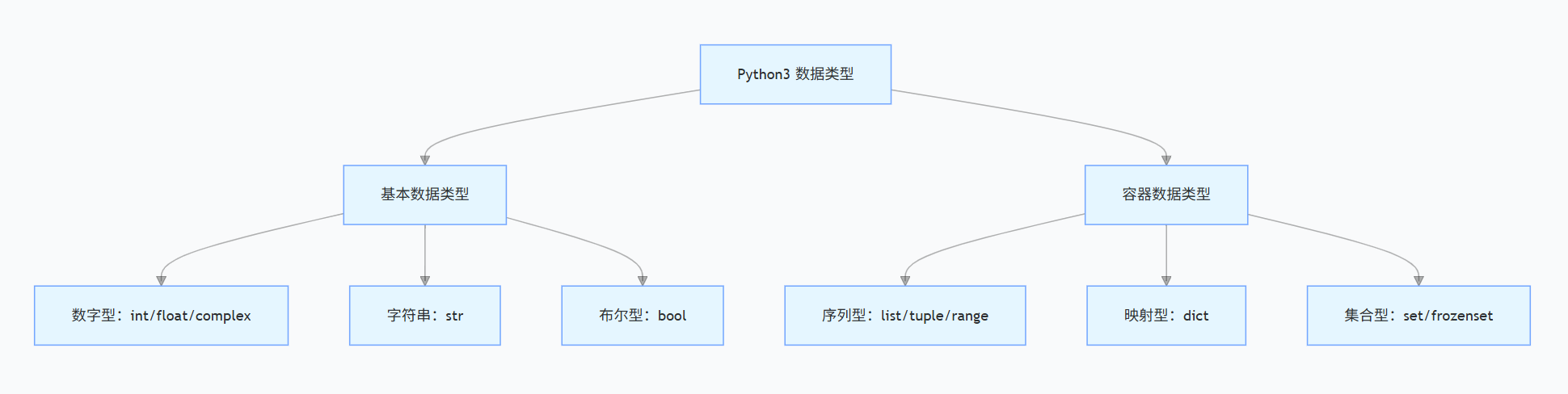
注意了,Python 是动态类型语言,变量的类型是由赋给它的值的类型决定的,如果将字符串赋值给变量,变量的类型就是字符串,将数字赋值给变量,变量的类型就是数字型。
下面将分别介绍 Python3 中的各种数据类型:
数字型(Number)

数字类型用于表示数值,如数量、金额等等,包含 3 种:
示例:
# 整数(int)
a = 10 # 正整数
b = -5 # 负整数
c = 0 # 零
print(type(a)) # 输出:<class 'int'>
# 浮点数(float)
d = 3.14 # 普通浮点数
e = 1.23e5 # 科学计数法,等价于 123000.0
f = -0.001 # 负浮点数
print(type(d)) # 输出:<class 'float'>
# 复数(complex)
g = 2 + 3j # 实部2,虚部3
print(type(g)) # 输出:<class 'complex'>
字符串(str)
字符串(String)是 Python 中最基础且常用的数据类型,本质是字符的有序序列,用于表示文本信息。例如字符串“abcde”,该字符串有 5 个字符组成,分别是字符‘a’、‘b’、‘c’、‘d’和‘e’。
字符串中每个字符均有一个索引,索引从 0 开始,从左边到右递增,如下图:
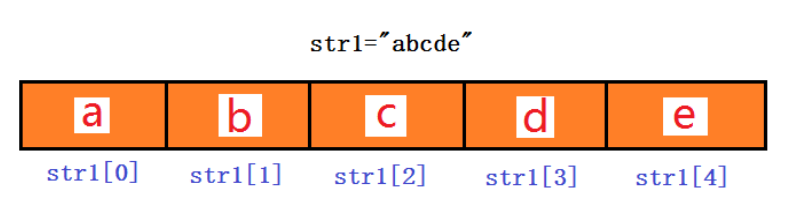
注意,字符串具有如下特性:
(1)不可变性:字符串一旦创建,就无法直接修改其中的某个字符,如不能通过 s[0] = 'A' 改变第一个字符。
(2)有序性:字符按插入顺序排列,可以通过索引(位置编号,从 0 开始)精准访问单个字符。
(3)字符类型无限制:可以包含字母、数字、符号、中文等任意字符。
(4)支持转义:用 \ 表示特殊字符(如换行 \n、制表符 \t、引号 \' 等)。
Python 中,使用单引号 '、双引号 " 或三引号 '''/""" 对字符串进行包裹。例如:
# 基础定义
s1 = 'hello' # 单引号
s2 = "Python" # 双引号
s3 = '''多行
字符串''' # 三引号(支持换行)
s4 = """也可以用
双引号三引号"""
print(type(s1)) # 输出:<class 'str'>
还支持转义字符,如 \n 换行等,例如:
# 转义字符
s5 = "Hello\nPython" # \n 换行
print(s5)
# 输出:
# Hello
# Python
s6 = r"Hello\nPython" # r 表示原始字符串,禁止转义
print(s6) # 输出:Hello\nPython
除了上述这些,Python 还为字符串提供了切片操作。切片是处理字符串的核心操作,本质是从字符串中截取指定范围的子字符串,支持正向 / 反向索引、灵活的步长控制。
切片语法格式:
字符串[起始索引:结束索引:步长]
注意,起始索引、结束索引、步长均可以省略。切片的字符串包含起始索引,不包含结束索引。
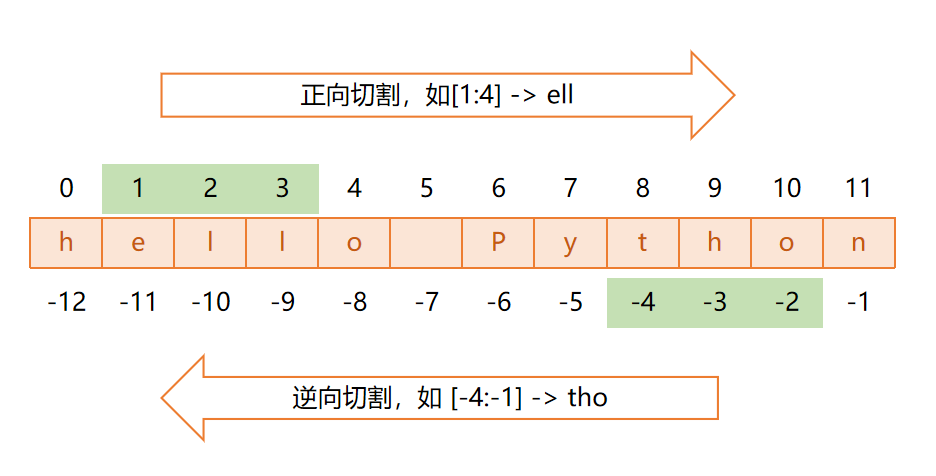
示例:
# 字符串切片(核心操作)
str = "hello python"
# 忽略结束位置,取第1个字符
print(str[0]) # 输出:h
# 取索引1到3(左闭右开)
print(str[1:4]) # 输出:ell
# 从开头取到索引2,忽略起始位置,默认从0开始
print(str[:3]) # 输出:hel
# 从索引3取到结尾
print(str[3:]) # 输出:lo python
# 从后往前取,取倒数第二个到倒数第四个
print(str[-4:-1]) # 输出:tho
# 取倒数第五个开始到最左边的所有字符
print(str[:-4]) # 输出:hello py
# 取最后一个字符
print(str[-1:]) # 输出:n
print(str[:-1]) # 输出:hello pytho
# 步长为2
print(str[1:8:2]) # 输出:el y
Python广告
布尔型(bool)
布尔值是 Python 中最基础的数据类型之一,核心作用是表示 “真” 或 “假”。类似于生活中的电源开关,打开开关表示真,关闭开关表示假。
布尔值常用于条件判断(如 if 语句)、循环控制(如 while 循环)等场景。
布尔类型只有两个值:True(真)、False(假),非 0 / 非空值转布尔值为 True,0 / 空值为 False。
简单示例:
# 基础定义
x = True
y = False
print(type(x)) # 输出:<class 'bool'>
# 类型转换(新手重点)
print(bool(0)) # 0 → False
print(bool(100)) # 非0整数 → True
print(bool("")) # 空字符串 → False
print(bool("abc")) # 非空字符串 → True
print(bool([])) # 空列表 → False
print(bool([1,2])) # 非空列表 → True
序列型
序列类型(Sequence Types) 是一类可迭代、有序、可通过索引访问元素的容器类型,核心特征是有序性和可索引。Python3 主要提供了列表(list)、元组(tuple)、范围(range)序列数据类型:
list(列表)
列表是可变的(允许增加、删除、更新元素),元素采用有序存储,因此也可以有序访问,使用 [] 包裹,元素类型可混合存储,即一个列表中存在数字、字符串或对象。例如:
创建列表:
empty_list = [] # 空列表
num_list = [1, 2, 3, 4, 5] # 整数列表
mix_list = [1, "Python", True, [6, 7]] # 混合类型列表(列表支持任意类型)
print("空列表:", empty_list) # 输出:空列表:[]
print("普通列表:", num_list) # 输出:普通列表:[1, 2, 3, 4, 5]
print("混合列表:", mix_list) # 输出:混合列表:[1, 'Python', True, [6, 7]]
# 通过其他可迭代对象创建(如range、字符串)
range_list = list(range(0, 10, 2)) # 从 range 创建:[0,2,4,6,8]
str_list = list("hello") # 从字符串创建:['h','e','l','l','o']
print("range创建列表:", range_list) # 输出:range创建列表:[0, 2, 4, 6, 8]
print("字符串创建列表:", str_list) # 输出:字符串创建列表:['h', 'e', 'l', 'l', 'o']
注意,上面的 range(0, 10, 2) 用于生成从 0 开始,到 10 结束,步长为 2 的整数序列,即 [0,2,4,6,8]。
range() 是 Python 中生成整数序列的内置函数,核心作用是「按需生成连续 / 步进的整数」,常配合 for 循环使用,语法如下:
range(stop) # 形式1:仅指定结束值(起始默认0,步长默认1)
range(start, stop) # 形式2:指定起始+结束值(步长默认1)
range(start, stop, step) # 形式3:指定起始+结束+步长
列表是支持修改的,因此我们可以队列表进行新增、修改、删除和查找元素等操作,例如:
# 新增元素
lst = [1, 2, 3]
# append:末尾添加单个元素
lst.append(4)
print("append后:", lst) # 输出:append后:[1, 2, 3, 4]
# extend:末尾添加可迭代对象(如列表、元组)
lst.extend([5, 6])
print("extend后:", lst) # 输出:extend后:[1, 2, 3, 4, 5, 6]
# insert:指定索引位置插入元素(索引0开头,-1结尾)
lst.insert(2, "插入的元素") # 在索引2位置插入
print("insert后:", lst) # 输出:insert后:[1, 2, '插入的元素', 3, 4, 5, 6]
# 删除元素
# pop:删除指定索引元素(默认删除最后一个),返回被删除的值
del_val = lst.pop(2) # 删除索引2的元素
print("pop删除的值:", del_val) # 输出:pop删除的值:插入的元素
print("pop后:", lst) # 输出:pop后:[1, 2, 3, 4, 5, 6]
# remove:删除第一个匹配的元素(按值删除)
lst.remove(4)
print("remove后:", lst) # 输出:remove后:[1, 2, 3, 5, 6]
# 修改元素(通过索引直接赋值)
lst[3] = 4 # 将索引3的元素改为4
print("修改后:", lst) # 输出:修改后:[1, 2, 3, 4, 6]
# 查找元素
# 索引访问:正索引(0开头)、负索引(-1结尾)
print("索引0的元素:", lst[0]) # 输出:索引0的元素:1
print("索引-1的元素:", lst[-1]) # 输出:索引-1的元素:6
# index:查找元素的第一个匹配索引(元素不存在报错)
idx = lst.index(4)
print("元素4的索引:", idx) # 输出:元素4的索引:3
# count:统计元素出现次数
cnt = lst.count(2)
print("元素2出现次数:", cnt) # 输出:元素2出现次数:1
# in/not in:判断元素是否存在
print("6是否在列表中:", 6 in lst) # 输出:6是否在列表中:True
print("7是否不在列表中:", 7 not in lst) # 输出:7是否不在列表中:True
# del:删除整个列表/指定切片
del lst[1:3] # 删除索引 1~2 的元素
# del lst # 删除列表对象(后续访问lst会报错)
print("删除后:", lst)
# clear:清空列表所有元素
lst.clear()
print("clear后:", lst) # 输出:clear后:[]
列表切片,切片的语法在字符串中已经介绍,这里就不再赘述:
# 语法:列表[起始索引:结束索引:步长],左闭右开(包含起始,不包含结束)
slice_lst = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 截取索引2到5的元素(不包含5)
print("切片[2:5]:", slice_lst[2:5]) # 输出:切片[2:5]:[2, 3, 4]
# 截取从开头到索引5的元素
print("切片[:5]:", slice_lst[:5]) # 输出:切片[:5]:[0, 1, 2, 3, 4]
# 截取从索引5到结尾的元素
print("切片[5:]:", slice_lst[5:]) # 输出:切片[5:]:[5, 6, 7, 8, 9]
# 步长2截取所有元素
print("切片[::2]:", slice_lst[::2]) # 输出:切片[::2]:[0, 2, 4, 6, 8]
# 步长-1:反转列表
print("切片[::-1]:", slice_lst[::-1]) # 输出:切片[::-1]:[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
列表排序,支持升序和降序,默认是升序;反转可以使用 [::-1] 切片语法实现,但是 reverse() 更方便,例如:
sort_lst = [5, 2, 8, 1, 9, 3]
# sort:原地排序(修改原列表),默认升序
sort_lst.sort()
print("sort升序:", sort_lst) # 输出:sort升序:[1, 2, 3, 5, 8, 9]
# sort降序
sort_lst.sort(reverse=True)
print("sort降序:", sort_lst) # 输出:sort降序:[9, 8, 5, 3, 2, 1]
# sorted:返回新列表(不修改原列表)
new_lst = sorted(sort_lst)
print("sorted新列表:", new_lst) # 输出:sorted新列表:[1, 2, 3, 5, 8, 9]
print("原列表不变:", sort_lst) # 输出:原列表不变:[9, 8, 5, 3, 2, 1]
# reverse:原地反转列表
sort_lst.reverse()
print("reverse反转:", sort_lst) # 输出:reverse反转:[1, 2, 3, 5, 8, 9]
列表的遍历(注意,for 语句将在后续章节介绍,可以跳过):
traverse_lst = ["a", "b", "c", "d"]
# 遍历元素
for elem in traverse_lst:
print("遍历元素:", elem) # 依次输出a、b、c、d
# 遍历索引+元素(enumerate)
for idx, elem in enumerate(traverse_lst):
print(f"索引{idx}:{elem}") # 输出:索引0:a 索引1:b ...
# 遍历索引(通过len)
for idx in range(len(traverse_lst)):
print(f"索引{idx}的元素:", traverse_lst[idx])
列表的高级操作,主要介绍列表拼接和重复,以及如何队列表进行统计,如计算长度、最大值、最小值和求和,用起来非常方便:
# 列表拼接(+)和重复(*)
lst1 = [1, 2]
lst2 = [3, 4]
print("列表拼接:", lst1 + lst2) # 输出:列表拼接:[1, 2, 3, 4]
print("列表重复:", lst1 * 3) # 输出:列表重复:[1, 2, 1, 2, 1, 2]
# 列表推导式(简洁创建/过滤列表)
# 后续章节介绍,可以跳过
# 生成1-10的偶数列表
even_lst = [x for x in range(1, 11) if x % 2 == 0]
print("列表推导式(偶数):", even_lst) # 输出:[2, 4, 6, 8, 10]
# 列表长度(len)、最大值(max)、最小值(min)、求和(sum)
num_lst = [1, 2, 3, 4, 5]
print("列表长度:", len(num_lst)) # 输出:5
print("最大值:", max(num_lst)) # 输出:5
print("最小值:", min(num_lst)) # 输出:1
print("求和:", sum(num_lst)) # 输出:15
tuple(元组)
元组的特性和上述介绍的列表一样,唯一的区别是元组不能被修改。如果试图修改元组将会报错“TypeError: 'tuple' object does not support item assignment”,例如:
元组的创建,下面将介绍多种创建元组的方法:
empty_tuple = () # 空元组
num_tuple = (1, 2, 3, 4, 5) # 整数元组
mix_tuple = (1, "Python", True, (6, 7)) # 混合类型+嵌套元组
print("空元组:", empty_tuple) # 输出:空元组:()
print("普通元组:", num_tuple) # 输出:普通元组:(1, 2, 3, 4, 5)
print("混合嵌套元组:", mix_tuple) # 输出:(1, 'Python', True, (6, 7))
# 省略括号(元组打包,仅单个元素时需加逗号)
simple_tuple = 10, 20, 30 # 省略括号,等价于 (10,20,30)
single_tuple = (88,) # 单个元素必须加逗号,否则不是元组(是int类型)
wrong_tuple = (99) # 这是整数,不是元组!
print("省略括号的元组:", simple_tuple) # 输出:(10, 20, 30)
print("单个元素元组:", single_tuple, type(single_tuple)) # 输出:(88,) <class 'tuple'>
print("错误的单个元素写法:", wrong_tuple, type(wrong_tuple)) # 输出:99 <class 'int'>
# 通过其他可迭代对象创建(如列表、range)
list_to_tuple = tuple([1, 2, 3]) # 列表转元组
range_to_tuple = tuple(range(0, 6, 2)) # range转元组
print("列表转元组:", list_to_tuple) # 输出:(1, 2, 3)
print("range转元组:", range_to_tuple) # 输出:(0, 2, 4)
元组的访问,如果你拥有其他编程语言经验,访问元组就像访问数组一样可以直接通过下标进行访问,例如:
t = (10, 20, 30, 40, (50, 60))
# 正索引访问(0开头)
print("索引0的元素:", t[0]) # 输出:10
print("索引3的元素:", t[3]) # 输出:40
# 负索引访问(-1结尾)
print("索引-1的元素(最后一个):", t[-1]) # 输出:(50, 60)
print("索引-2的元素:", t[-2]) # 输出:40
# 嵌套元组访问(多层索引)
print("嵌套元组的索引0元素:", t[-1][0]) # 输出:50(先取最后一个元素,再取其索引0)
元组的切片,和列表语法一致,左闭右开,例如:
slice_tuple = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
# 截取索引2到5的元素(不包含5)
print("切片[2:5]:", slice_tuple[2:5]) # 输出:(2, 3, 4)
# 截取从开头到索引5的元素
print("切片[:5]:", slice_tuple[:5]) # 输出:(0, 1, 2, 3, 4)
# 截取从索引5到结尾的元素
print("切片[5:]:", slice_tuple[5:]) # 输出:(5, 6, 7, 8, 9)
# 步长2截取所有元素
print("切片[::2]:", slice_tuple[::2]) # 输出:(0, 2, 4, 6, 8)
# 步长-1:反转元组
print("切片[::-1]:", slice_tuple[::-1]) # 输出:(9, 8, 7, 6, 5, 4, 3, 2, 1, 0)
元组的拼接表示多个元组可以使用“+”符号进行连接,生成一个新的元组。重复表示可以使用“*N”形式将元组重复 N 次,生成新的元组,例如:
t1 = (1, 2)
t2 = (3, 4)
# 拼接(+):生成新元组,原元组不变
concat_tuple = t1 + t2
print("元组拼接:", concat_tuple) # 输出:(1, 2, 3, 4)
print("原t1不变:", t1) # 输出:(1, 2)
# 重复(*):生成新元组,原元组不变
repeat_tuple = t1 * 3
print("元组重复3次:", repeat_tuple) # 输出:(1, 2, 1, 2, 1, 2)
元组的查找用于查询指定值在元组中的位置下标,统计则用于计算指定元素在元组中出现的次数,例如:
find_tuple = (1, 2, 3, 2, 4, 2, 5)
# index:查找元素的第一个匹配索引(元素不存在报错)
idx = find_tuple.index(2)
print("元素2的第一个索引:", idx) # 输出:1
# 可选:指定查找范围(索引2到5)
idx_range = find_tuple.index(2, 2, 5)
print("索引2-5内元素2的索引:", idx_range) # 输出:3
# count:统计元素出现次数
cnt = find_tuple.count(2)
print("元素2出现次数:", cnt) # 输出:3
# in/not in:判断元素是否存在
print("5是否在元组中:", 5 in find_tuple) # 输出:True
print("6是否不在元组中:", 6 not in find_tuple) # 输出:True
元组的遍历,下面介绍三种遍历元组的方式,for 语句的用法将在后续章节介绍,可以跳过下面内容:
traverse_tuple = ("苹果", "香蕉", "橙子")
# 遍历元素
for fruit in traverse_tuple:
print("遍历元素:", fruit) # 依次输出苹果、香蕉、橙子
# 遍历索引+元素(enumerate)
for idx, fruit in enumerate(traverse_tuple):
print(f"索引{idx}:{fruit}") # 输出:索引0:苹果 索引1:香蕉 ...
# 遍历索引(通过len)
for idx in range(len(traverse_tuple)):
print(f"索引{idx}的元素:", traverse_tuple[idx])
元组的不可变性,表示元组是不能进行修改的,但是,如果元组内部包含的元素是可以被修改的,如列表,则我们可以修改列表的值,例如:
immutable_tuple = (1, 2, 3)
# 拼接 + 切片
new_tuple = immutable_tuple[:1] + (100,) + immutable_tuple[2:]
print("间接修改后的新元组:", new_tuple) # 输出:(1, 100, 3)
print("原元组仍不变:", immutable_tuple) # 输出:(1, 2, 3)
# 元组转列表进行修改,再转回元组
temp_list = list(immutable_tuple)
temp_list[0] = 100 # 列表可修改
new_tuple2 = tuple(temp_list)
print("转列表修改后的元组:", new_tuple2) # 输出:(100, 2, 3)
# 嵌套元组中的可变元素(如列表)可修改
nested_tuple = (1, [2, 3], 4)
nested_tuple[1][0] = 999 # 修改元组内的列表元素
print("修改嵌套列表后的元组:", nested_tuple) # 输出:(1, [999, 3], 4)
# 直接修改元素会报错(元组不可变)
immutable_tuple[0] = 100
# 报错:TypeError: 'tuple' object does not support item assignment
元组的其他常用操作:
# 长度(len)、最大值(max)、最小值(min)、求和(sum)
num_tuple = (1, 2, 3, 4, 5)
print("元组长度:", len(num_tuple)) # 输出:5
print("最大值:", max(num_tuple)) # 输出:5
print("最小值:", min(num_tuple)) # 输出:1
print("求和:", sum(num_tuple)) # 输出:15
# 元组解包(核心实用功能)
a, b, c = (10, 20, 30) # 解包:变量数=元素数
print(f"解包后:a={a}, b={b}, c={c}") # 输出:a=10, b=20, c=30
# 星号解包(变量数≠元素数)
first, *middle, last = (1, 2, 3, 4, 5)
print(f"星号解包:first={first}, middle={middle}, last={last}") # 输出:first=1, middle=[2,3,4], last=5
# 元组比较(按元素依次比较)
t_a = (1, 2, 3)
t_b = (1, 2, 4)
print("t_a < t_b:", t_a < t_b) # 输出:True(前两个元素相等,第三个3<4)
range(范围)
range() 是一个内置的函数,主要用于生成整数序列,常配合循环(如 for 循环)使用,它不会直接生成完整的列表,而是返回一个可迭代的 range 对象。
range() 有三种使用形式,如下:
# 形式1:仅结束值(start 默认 0,step 默认 1)
range(stop) # 生成 0~stop 的整数,如 0,1,2,3,4
# 形式2:起始值 + 结束值(step 默认 1)
range(start, stop) # 生成 start~stop 的整数
# 形式3:起始值 + 结束值 + 步长
range(start, stop, step)
range 的创建:
# 形式1:仅指定结束值(start=0,step=1)
r1 = range(5)
print("r1 = range(5) →", list(r1)) # 输出:[0, 1, 2, 3, 4]
# 形式2:指定起始+结束值(step=1)
r2 = range(2, 8)
print("r2 = range(2,8) →", list(r2)) # 输出:[2, 3, 4, 5, 6, 7]
# 形式3:指定起始+结束+步长(正数步长:递增)
r3 = range(1, 10, 2)
print("r3 = range(1,10,2) →", list(r3)) # 输出:[1, 3, 5, 7, 9]
# 形式4:指定起始+结束+步长(负数步长:递减)
r4 = range(10, 1, -3)
print("r4 = range(10,1,-3) →", list(r4)) # 输出:[10, 7, 4]
# 异常情况:无效范围(生成空序列)
r5 = range(5, 2) # 递增但 start > stop → 空
r6 = range(2, 5, -1) # 递减但 start < stop → 空
print("r5 = range(5,2) →", list(r5)) # 输出:[]
print("r6 = range(2,5,-1) →", list(r6)) # 输出:[]
range 的访问,和列表元组一样,支持通过索引进行访问,例如:
r = range(0, 10, 1) # 0-9
# 正索引(0开头)
print("r[0] →", r[0]) # 输出:0(第一个元素)
print("r[5] →", r[5]) # 输出:5(第六个元素)
# 负索引(-1结尾)
print("r[-1] →", r[-1]) # 输出:9(最后一个元素)
print("r[-3] →", r[-3]) # 输出:7(倒数第三个元素)
# 索引越界报错
print(r[10])
# 报错:IndexError: range object index out of range
range 的切片,切片语法参考字符串切片,这里不再赘述。注意,切片将生成新的 range 对象,例如:
r = range(0, 10) # 0-9
# 切片语法:[start:stop:step](左闭右开,包含左边,不包含右边,和列表一致)
# 切片1:截取索引2到6的元素
slice1 = r[2:7]
print("r[2:7] →", list(slice1)) # 输出:[2, 3, 4, 5, 6]
# 切片2:截取前5个元素,实际 r[0:5]
slice2 = r[:5]
print("r[:5] →", list(slice2)) # 输出:[0, 1, 2, 3, 4]
# 切片3:截取从索引5到结尾的元素
slice3 = r[5:]
print("r[5:] →", list(slice3)) # 输出:[5, 6, 7, 8, 9]
# 切片4:步长2截取所有元素
slice4 = r[::2]
print("r[::2] →", list(slice4)) # 输出:[0, 2, 4, 6, 8]
# 切片5:步长-1反转(生成递减的 range)
slice5 = r[::-1]
print("r[::-1] →", list(slice5)) # 输出:[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
range 判断成员是否在 range 中,例如:
r = range(0, 10, 2) # 0,2,4,6,8
# in 用于判断元素是否存在 range 中
print("5 in r →", 5 in r) # 输出:False(5不在序列中)
print("6 in r →", 6 in r) # 输出:True(6在序列中)
# not in 用于判断元素是否不存在 range 中
print("9 not in r →", 9 not in r) # 输出:True(9不在序列中)
range 的遍历,遍历涉及了 for 语句,该语句将在后续章节详细介绍,可直接跳过下面内容:
# 遍历元素
print("遍历 range(5) 元素:")
for num in range(5):
print(num, end=" ") # 输出:0 1 2 3 4
print("\n")
# 遍历索引(通过 len + range)
r = range(2, 8)
print("遍历 range(2,8) 索引+元素:")
for idx in range(len(r)):
print(f"索引{idx}:{r[idx]}") # 输出:索引0:2 索引1:3 ... 索引5:7
print("\n")
# enumerate 遍历(索引+元素)
print("enumerate 遍历 range(1,10,2):")
for idx, num in enumerate(range(1, 10, 2)):
print(f"索引{idx}:{num}") # 输出:索引0:1 索引1:3 ... 索引4:9
range 自带的属性,如 start 表示起始值,stop 表示结束值,step 表示步长。以及对 range 的统计便捷工具 max 最大值、min 最小值、sum 求和,例如:
r = range(1, 10, 2)
# 获取 range 的核心属性(start/stop/step,Python 3.3+ 才支持)
print("r.start →", r.start) # 输出:1(起始值)
print("r.stop →", r.stop) # 输出:10(结束值)
print("r.step →", r.step) # 输出:2(步长)
# 长度计算(len)
print("len(r) →", len(r)) # 输出:5(元素个数)
# 最大值/最小值/求和(仅数值序列有效)
print("max(r) →", max(r)) # 输出:9(最大值)
print("min(r) →", min(r)) # 输出:1(最小值)
print("sum(r) →", sum(r)) # 输出:25(求和:1+3+5+7+9)
range 的比较,注意,range 对象的比较并非比较内存地址或对象本身,而是比较其生成的整数序列是否完全一致 —— 只要两个 range 对象的 start、stop、step 参数推导出来的整数序列相同,就判定为相等(==),否则不相等。例如:
# 规则:元素序列相同则相等,与 start/stop/step 写法无关
r1 = range(0, 5) # 0,1,2,3,4
r2 = range(0, 6, 1) # 0,1,2,3,4,5
r3 = range(4, -1, -1) # 4,3,2,1,0
r4 = range(0, 5, 1) # 0,1,2,3,4
print("r1 == r4 →", r1 == r4) # 输出:True(序列相同)
print("r1 == r2 →", r1 == r2) # 输出:False(序列不同)
print("r1 == r3 →", r1 == r3) # 输出:False(序列顺序不同)
range 的转换:range 对象本身是一个可以迭代的序列生成器,不直接存储完整的数据。而在实际开发中,我们常常需要将其转换为列表、元组、集合等,例如:
r = range(1, 6)
# 转列表
lst = list(r)
print("range 转列表 →", lst) # 输出:[1, 2, 3, 4, 5]
# 转元组
tup = tuple(r)
print("range 转元组 →", tup) # 输出:(1, 2, 3, 4, 5)
# 转集合
s = set(r)
print("range 转集合 →", s) # 输出:{1, 2, 3, 4, 5}
Python广告
字典(dict)
在 Python3 中,字典是中最核心、最常用的可变、无序、键值对(key-value) 数据结构,你可以把它理解成现实中的 “字典”—— 通过 “关键字(key)” 快速查找对应的 “释义(value)”,这也是它和列表(按索引查找)最核心的区别。如下图:

上图定义了三个键值对,我们可以根据 key1 快速找到对应的值 value1。如下图:
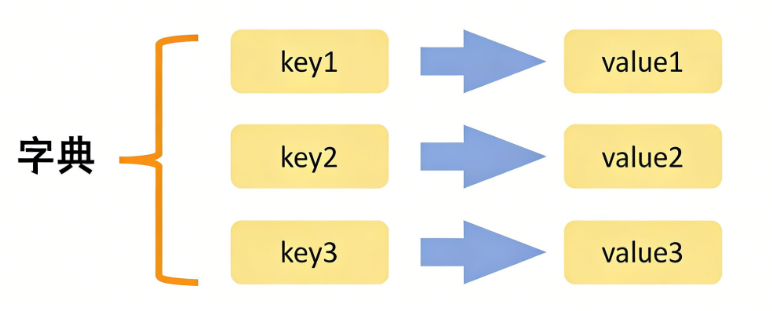
其实字典在我们生活中经常会用到,例如小区的门牌号,你只需要知道门牌号就可以快速找到门牌号对应的房屋。还有快递取件码,快递员可以通过取件码快速找到你的快递。
我们可以使用字典存储用户信息,将用户的 ID 作为字典的键,键对应的值保存用户详细信息,当要查询某个用户的信息时,可以通过用户 ID 快速查询出来。如果你学过 Java,字典和 Java 中的 Map 就很相似。
注意,字典用 {} 包裹,且键(key)是唯一、不可变(字符串 / 数字 / 元组)的,键对应的值(value)可是任意值。
创建字典,下面将介绍多种创建字典的方式,例如:
# 方式1:基础创建(空字典、普通字典、嵌套字典)
empty_dict = {} # 空字典
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
print("空字典:", empty_dict) # 输出:{}
print("普通嵌套字典:", person)
# 输出:{'name': '张三', 'age': 25, 'gender': '男', 'hobbies': ['篮球', '阅读'], 'address': {'city': '北京', 'district': '朝阳'}}
# dict() 构造函数创建
# 键值对参数
dict1 = dict(name="李四", age=30, gender="女")
print("dict()参数创建:", dict1) # 输出:{'name': '李四', 'age': 30, 'gender': '女'}
# 列表/元组的键值对序列
dict2 = dict([("a", 1), ("b", 2), ("c", 3)])
print("列表键值对创建:", dict2) # 输出:{'a': 1, 'b': 2, 'c': 3}
# 从 zip 对象创建
dict3 = dict(zip(["x", "y", "z"], [10, 20, 30]))
print("zip创建:", dict3) # 输出:{'x': 10, 'y': 20, 'z': 30}
# 字典推导式(简洁创建/过滤),可跳过,后续将介绍推导式
# 生成键为1-5,值为键的平方的字典
square_dict = {x: x*x for x in range(1, 6)}
print("字典推导式:", square_dict) # 输出:{1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
字典的访问,和元组、列表不同,字典不支持通过索引进行访问,唯一访问字典的方式是通过字典的键,例如:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 键访问(直接用[key],键不存在报错)
print("访问name:", person["name"]) # 输出:张三
print("访问嵌套字典的city:", person["address"]["city"]) # 输出:北京
# print(person["height"]) # 报错:KeyError: 'height'
print("\n")
# get() 访问(键不存在返回默认值,推荐)
print("get访问age:", person.get("age")) # 输出:25
print("get访问不存在的height(默认None):", person.get("height")) # 输出:None
print("get访问height(指定默认值):", person.get("height", 175)) # 输出:175
print("\n")
# 获取所有键/值/键值对
# keys() 获取所有的键
print("所有键(keys()):", list(person.keys()))
# 输出:['name', 'age', 'gender', 'hobbies', 'address']
# values() 获取所有的值
print("所有值(values()):", list(person.values()))
# 输出:['张三', 25, '男', ['篮球', '阅读'], {'city': '北京', 'district': '朝阳'}]
# items() 获取所有的键值对
print("所有键值对(items()):", list(person.items()))
# 输出:[('name', '张三'), ('age', 25), ...]
字典新增非常简单,可以直接进行赋值,也可以使用 setdefault() 函数,如果键存在,则返回;否则则新增,并返回默认值。例如:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 直接赋值
person["height"] = 180;
print("新增height后:", person)
# setdefault() 用于键存在则返回值,不存在则新增并返回默认值
# 键存在(gender),返回值不修改
gender = person.setdefault("gender", "未知")
print("setdefault存在的键:", gender) # 输出:男
# 键不存在(email),新增并返回默认值
email = person.setdefault("email", "zhangsan@example.com")
print("setdefault新增键:", email) # 输出:zhangsan@example.com
print("新增email后:", person) # 输出:... 'email': 'zhangsan@example.com' ...
字典的修改,支持对单个键的值进行修改,和批量修改,如下:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 直接赋值(键存在则修改,不存在则新增)
person["age"] = 26 # 修改已有键
person["height"] = 180 # 新增键值对
print("修改age + 新增height后:", person)
print("\n")
# 输出:... 'age': 26, ... 'height': 180 ...
# update() 批量修改/新增
# 传入字典
person.update({"gender": "男", "phone": "13800138000"})
print("update批量修改后:", person)
print("\n")
# 传入键值对参数
person.update(hobbies=["篮球", "阅读", "旅行"], address={"city": "上海"})
print("update批量修改后:", person)
# 输出:... 'gender': '男', 'phone': '13800138000', 'hobbies': ['篮球', '阅读', '旅行'], 'address': {'city': '上海'} ...
字典删除和清空,支持使用 del、pop() 和 popitem() 删除键,以及 clear() 清空整个字典,例如:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# del 删除指定键值对/整个字典
del person["age"] # 删除指定键
print("del删除age后:", person) # 无age字段
# del person # 删除整个字典,后续访问 person 会报错
# pop() 删除指定键,返回对应值(键不存在可指定默认值)
hobbies = person.pop("hobbies")
print("pop删除hobbies返回值:", hobbies) # 输出:['篮球', '阅读', '旅行']
# print(person.pop("weight")) # 报错:KeyError: 'weight'
weight = person.pop("weight", 70) # 指定默认值,不报错
print("pop不存在的weight(默认值):", weight) # 输出:70
# popitem() 删除最后插入的键值对(Python3.7+),返回键值对元组
person.setdefault("email", "zhangsan@example.com")
last_item = person.popitem()
print("popitem删除的键值对:", last_item) # 输出:('email', 'zhangsan@example.com')
# clear() 清空所有键值对(字典对象保留)
temp_dict = {"a": 1, "b": 2}
temp_dict.clear()
print("clear清空后:", temp_dict) # 输出:{}
字典的遍历,涉及 for 语句的用法,for 语句将在后续章节介绍,可以跳过:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 遍历键(默认遍历 keys())
print("遍历键:")
for key in person:
print(key, end=" ") # 输出:name age gender address height
print("\n")
# 遍历值
print("遍历值:")
for value in person.values():
print(value, end=" ") # 输出:张三 26 男 {'city': '上海'} 180
print("\n")
# 遍历键值对(最常用)
print("遍历键值对:")
for key, value in person.items():
print(f"{key}: {value}")
# 输出:
# name: 张三
# age: 26
# gender: 男
# address: {'city': '上海'}
# height: 180
字典判断键是否存在,以及统计字典中键的个数,例如:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 判断键是否存在(in / not in,仅判断键)
print("name是否在字典中:", "name" in person) # 输出:True
print("phone是否不在字典中:", "phone" not in person) # 输出:True
# 统计字典长度(键值对个数)
print("字典长度:", len(person)) # 输出:5
字典复制,复制分为浅复制和深度复制,浅复制指只复制第一层,嵌套的子对象仍然共用。例如:
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 浅拷贝(copy() / dict()):顶层独立,嵌套字典共享
person_copy = person.copy()
person_copy["address"]["city"] = "广州" # 修改嵌套字典
print("浅拷贝后原字典address:", person["address"])
# 输出: {'city': '广州', 'district': '朝阳'}
深复制指递归复制所有层级,完全独立,互不影响。下面示例将借助 copy 库完成,可以跳过,后续将介绍如何引入库以及库的概念,例如:
import copy
person = {
"name": "张三",
"age": 25,
"gender": "男",
"hobbies": ["篮球", "阅读"], # 值可以是任意类型
"address": {"city": "北京", "district": "朝阳"} # 嵌套字典
}
# 深度复制
person_deep = copy.deepcopy(person)
# 修改复制后的字典
person_deep["address"]["city"] = "深圳"
print("深拷贝后原字典address:", person["address"])
# 输出:{"city": "北京", "district": "朝阳"}(原字典不变)
字典的排序,不仅列表和元组支持排序,字典同样支持排序,可以按键排序,也可以按值排序,例如:
person = {
"name": "张三",
"age": 25,
"gender": "男"
}
# 按键排序(sorted())
sorted_keys = sorted(person.keys())
print("按键排序的键列表:", sorted_keys)
# 输出:['age', 'gender', 'name']
# 按值排序(需指定key参数)
score_dict = {"math": 90, "chinese": 95, "english": 88}
# 按值升序
# 注意,sorted() 方法中使用了 lambda 表达式,后续章节将详细介绍,可以跳过
sorted_by_value_asc = sorted(score_dict.items(), key=lambda x: x[1])
print("按值升序:", sorted_by_value_asc)
# 输出:[('english', 88), ('math', 90), ('chinese', 95)]
# 按值降序
sorted_by_value_desc = sorted(score_dict.items(), key=lambda x: x[1], reverse=True)
print("按值降序:", sorted_by_value_desc)
# 输出:[('chinese', 95), ('math', 90), ('english', 88)]
字典的其他高级操作:
# 合并字典(Python3.9+ | 操作符)
dict_a = {"a": 1, "b": 2}
dict_b = {"b": 3, "c": 4}
merged_dict = dict_a | dict_b # 重复键取dict_b的值
print("| 合并字典:", merged_dict) # 输出:{'a': 1, 'b': 3, 'c': 4}
# 解包字典(**)
# 下面使用 def 定义了一个名为 print_persion 的函数,后续将详细介绍,可跳过
def print_person(name, age):
print(f"姓名:{name},年龄:{age}")
person_info = {"name": "王五", "age": 28}
print_person(**person_info)
# 等价于 print_person(name="王五", age=28),输出:姓名:王五,年龄:28
# 获取默认值并更新(setdefault 函数的应用)
# 统计列表元素出现次数
words = ["apple", "banana", "apple", "orange", "banana", "apple"]
count_dict = {}
for word in words:
count_dict.setdefault(word, 0) # 不存在则设为0
count_dict[word] += 1
print("元素计数:", count_dict) # 输出:{'apple': 3, 'banana': 2, 'orange': 1}
集合型
集合中的元素无序且不可重复,使用大括号 {} 表示;空集合必须用 set() 创建,支持交集、并集、差集等常见集合运算。
Python3 支持可变集合(set)和不可变集合(frozenset)。
set(可变集合)
在 Python3 中,set(可变集合)是无序、不重复的元素集合,支持增、删、查等核心操作,还支持集合间的交、并、差等数学运算。
创建集合,使用 {}(注意,空集合不要使用 {},必须使用 set(),因为 {} 表示空字典) 和 set() 创建集合,例如:
# 空集合(注意:{} 是空字典,必须用 set() 创建空集合)
empty_set = set()
print("空集合:", empty_set) # 输出: set()
# 从列表/元组/字符串创建集合(自动去重)
num_set = {1, 2, 3, 3, 4} # 直接创建(去重后:{1,2,3,4})
str_set = set("hello") # 从字符串创建(去重后:{'h','e','l','o'})
print("去重后的数字集合:", num_set) # 输出: {1, 2, 3, 4}
print("字符串转集合:", str_set) # 输出: {'h', 'e', 'l', 'o'}
添加元素:向集合添加元素可以使用 add() 方法,或者使用 update() 更新集合,例如:
num_set = {1, 2, 3, 3, 4}
# add(): 添加单个元素(元素不存在则添加,存在则无操作)
num_set.add(5)
print("add(5) 后:", num_set) # 输出: {1, 2, 3, 4, 5}
num_set.add(3) # 添加已存在的元素,无变化
print("add(3) 后:", num_set) # 输出: {1, 2, 3, 4, 5}
# update(): 批量添加元素(接收可迭代对象:列表/元组/集合等)
num_set.update([6, 7], (8, 9))
print("update([6,7], (8,9)) 后:", num_set) # 输出: {1,2,3,4,5,6,7,8,9}
删除元素:从集合中删除元素和列表、字段不同,列表通过索引删除,字典使用键进行删除,集合直接通过元素本身进行删除,例如:
num_set = {1,2,3,4,5,6,7,8,9}
# remove(): 删除指定元素(元素不存在则报错 KeyError)
num_set.remove(9)
print("remove(9) 后:", num_set) # 输出: {1,2,3,4,5,6,7,8}
# num_set.remove(10) # 报错:KeyError: 10
# discard(): 删除指定元素(元素不存在则无操作,推荐用这个避免报错)
num_set.discard(8)
print("discard(8) 后:", num_set) # 输出: {1,2,3,4,5,6,7}
num_set.discard(10) # 无报错,集合不变
print("discard(10) 后:", num_set) # 输出: {1,2,3,4,5,6,7}
# pop(): 随机删除并返回一个元素(集合无序,无法指定删除)
popped_elem = num_set.pop()
print("pop() 删除的元素:", popped_elem) # 随机输出(如 1)
print("pop() 后集合:", num_set) # 如 {2,3,4,5,6,7}
# clear(): 清空集合所有元素
num_set.clear()
print("clear() 后集合:", num_set) # 输出: set()
集合查询/判断:和列表、元组一样,集合也可以使用 in 和 not in 操作符判断某个元素是否在集合中,除此以外,集合还支持使用 issubset() 判断子集、issuperset() 判断超集和 isdisjoint() 两个集合是否相交等操作(关于子集、超集和相交可以自行查阅相关数学书籍),例如:
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
# 判断元素是否在集合中(in / not in)
print("3 是否在 a 中:", 3 in a) # 输出: True
print("5 是否不在 a 中:", 5 not in a) # 输出: True
# 判断集合关系(子集、超集、不相交)
c = {3, 4}
print("c 是否是 a 的子集:", c.issubset(a)) # 输出: True
print("a 是否是 c 的超集:", a.issuperset(c)) # 输出: True
print("a 和 b 是否不相交:", a.isdisjoint(b)) # 输出: False(有交集 3,4)
集合运算:用于计算两个集合是否是交集、并集、差集、对称差集操作,例如:
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
# 交集(& 或 intersection()):两个集合都有的元素
intersection = a & b
# 等价于 a.intersection(b)
print("a 和 b 的交集:", intersection) # 输出: {3,4}
# 并集(| 或 union()):两个集合所有元素(去重)
union = a | b
# 等价于 a.union(b)
print("a 和 b 的并集:", union) # 输出: {1,2,3,4,5,6}
# 差集(- 或 difference()):a 有但 b 没有的元素
difference = a - b
# 等价于 a.difference(b)
print("a - b 的差集:", difference) # 输出: {1,2}
# 对称差集(^ 或 symmetric_difference()):两个集合中互不相同的元素
sym_diff = a ^ b
# 等价于 a.symmetric_difference(b)
print("a 和 b 的对称差集:", sym_diff) # 输出: {1,2,5,6}
集合推导式:用于快速创建集合,后续将详细介绍推导式,可以跳过:
# 生成 1-10 中偶数的集合
even_set = {x for x in range(1, 11) if x % 2 == 0}
print("集合推导式生成的偶数集合:", even_set) # 输出: {2,4,6,8,10}
frozenset(不可变集合)
frozenset(不可变集合)是 Python 中 set 的不可变版本,它的元素一旦被创建就无法增删改,因此不能使用 add()/remove() 等修改操作,但支持集合的查询、关系判断、数学运算(交并差等),还能作为字典的键或另一个集合的元素(注意,不可变集合可以作为字典的键,字典的键要求不可变,因此可变集合不能作为字典的键)。
创建不可变集合:不可变集合必须使用 frozenset() 进行创建,例如:
# 创建空的 frozenset
empty_fs = frozenset()
print("空的不可变集合:", empty_fs) # 输出: frozenset()
# 从可迭代对象(列表/元组/字符串/普通集合)创建(自动去重)
# 从列表创建(去重)
num_fs = frozenset([1, 2, 3, 3, 4])
# 从字符串创建(去重)
str_fs = frozenset("hello")
# 从普通 set 创建
normal_set = {5, 6, 7}
fs_from_set = frozenset(normal_set)
print("列表转不可变集合(去重):", num_fs) # 输出: frozenset({1, 2, 3, 4})
print("字符串转不可变集合(去重):", str_fs) # 输出: frozenset({'h', 'e', 'l', 'o'})
print("普通 set 转不可变集合:", fs_from_set) # 输出: frozenset({5, 6, 7})
注意,Python3 的不可变集合是不支持修改操作的,如果对不可变集合进行修改将抛出 AttributeError 异常,例如:
num_fs = frozenset([1, 2, 3, 3, 4])
# 尝试修改会直接报错(AttributeError)
try:
num_fs.add(5)
except AttributeError as e:
print("\n报错(add 操作):", e)
# 输出: 'frozenset' object has no attribute 'add'
try:
num_fs.remove(3)
except AttributeError as e:
print("报错(remove 操作):", e)
# 输出: 'frozenset' object has no attribute 'remove'
try:
num_fs.clear()
except AttributeError as e:
print("报错(clear 操作):", e)
# 输出: 'frozenset' object has no attribute 'clear'
不可变集合也支持使用 in 和 not in 操作符判断某个元素是否存在于不可变集合中,例如:
a = frozenset({1, 2, 3, 4})
b = frozenset({3, 4, 5, 6})
c = frozenset({3, 4})
# 判断元素是否在集合中(in / not in)
print("\n3 是否在 a 中:", 3 in a) # 输出: True
print("5 是否不在 a 中:", 5 not in a) # 输出: True
# 判断集合关系(子集、超集、不相交)
print("c 是否是 a 的子集:", c.issubset(a)) # 输出: True
print("a 是否是 c 的超集:", a.issuperset(c)) # 输出: True
print("a 和 b 是否不相交:", a.isdisjoint(b)) # 输出: False(有交集 3,4)
# 获取集合长度(len())
print("a 的元素个数:", len(a)) # 输出: 4
# 遍历 frozenset(和普通 set 一样)
print("\n遍历 a 的元素:", end=" ")
for elem in a:
print(elem, end=" ") # 输出: 1 2 3 4(顺序不固定,集合无序)
print()
不可变集合的数学运算,和集合一样,这里不在赘述。注意:不可变集合的运算结果仍是 frozenset,而非普通 set。例如:
# 交集(& 或 intersection()):两个集合都有的元素
intersection = a & b
# 等价于 a.intersection(b)
print("\na 和 b 的交集:", intersection) # 输出: frozenset({3, 4})
# 并集(| 或 union()):两个集合所有元素(去重)
union = a | b
# 等价于 a.union(b)
print("a 和 b 的并集:", union) # 输出: frozenset({1, 2, 3, 4, 5, 6})
# 差集(- 或 difference()):a 有但 b 没有的元素
difference = a - b
# 等价于 a.difference(b)
print("a - b 的差集:", difference) # 输出: frozenset({1, 2})
# 对称差集(^ 或 symmetric_difference()):互不相同的元素
sym_diff = a ^ b
# 等价于 a.symmetric_difference(b)
print("a 和 b 的对称差集:", sym_diff) # 输出: frozenset({1, 2, 5, 6})
注意,我们可以将不可变集合作为字典的键,普通 set 不能作为字典键(因为可变),例如:
# 正确示例:frozenset 作为字典键
fs_key = frozenset([1, 2, 3])
my_dict = {fs_key: "这是不可变集合作为键"}
print("\n字典(键为 frozenset):", my_dict)
# 输出: {frozenset({1,2,3}): '这是不可变集合作为键'}
# 普通 set 不能作为另一个 set 的元素,但 frozenset 可以
fs_elem = frozenset([4, 5])
set_with_fs = {1, 2, fs_elem}
print("包含 frozenset 的普通集合:", set_with_fs)
# 输出: {1, 2, frozenset({4, 5})}
更多关于不可变集合的其他操作,例如:
a = frozenset({1, 2, 3, 4})
fs_to_set = set(a) # 转换为普通集合
fs_to_set.add(5) # 普通 set 可修改
new_fs = frozenset(fs_to_set) # 再转换为不可变集合
print("修改后转回 frozenset:", new_fs)
# 输出: frozenset({1, 2, 3, 4, 5})
# 比较两个 frozenset(== / !=)
print("a 和 new_fs 是否相等:", a == new_fs) # 输出: False
print("a 和 frozenset({1,2,3,4}) 是否相等:", a == frozenset({1,2,3,4})) # 输出: True
到这里,Python 中主要的数据类型就介绍完了,请多多练习,掌握上面的数据类型。
更多 Python3 知识,请继续学习后续章节。

 川公网安备51010802032098
川公网安备51010802032098