在 Python 中,模块(Module)是组织代码的核心方式。从本质上来说,模块就是一个后缀为 .py 的文件,该文件内部包含了各种 Python 定义以及语句。
我们借助模块能够将复杂的代码进行合理拆分,实现分而治之。代码的复用性得到显著提高,在不同的项目中,可以轻松调用模块里已经写好的代码,避免重复编写。
同时,这也大幅增强了代码的可维护性,当代码出现问题或者需要进行功能更新时,只需要针对具体模块进行修改,而不会对整个项目的其他部分造成过多影响。
内置模块
内置模块是 Python 解释器自带的模块,无需安装,开箱即用。它们由 Python 官方维护,覆盖了绝大多数基础功能场景。
常用的内置模块及用途如下:
sys 模块:用来与 Python 解释器交互,如获取命令行参数、Python 版本信息等。
os 模块:用来与操作系统交互,如文件 / 目录操作、环境变量管理等。
math 模块:用来进行数学运算,如三角函数、常量(π、e)、幂运算等。
datetime 模块:用于日期时间处理,如:时间格式化、时间差计算等。
json 模块:用于 JSON 数据编解码,如:字典与 JSON 字符串互转等。
random 模块:用于生成随机数,如随机整数、随机选择列表元素等。
注意,导入模块使用 import 语句,关于 import 语句将在后续详细介绍。
示例1:使用 sys 模块获取 Python 版本和命令行参数
import sys
print("Python 版本:", sys.version) # 输出 Python 版本信息
print("命令行参数:", sys.argv) # 输出运行脚本时的命令行参数
示例2:使用 math 模块进行数学计算
import math
print("π 的值:", math.pi) # 输出 3.141592653589793
print("10 的平方根:", math.sqrt(10)) # 输出 3.1622776601683795
示例3:使用 datetime 处理时间
from datetime import datetime
now = datetime.now() # 获取当前时间
print("当前时间:", now.strftime("%Y-%m-%d %H:%M:%S")) # 格式化输出
Python广告
import 详解
在 Python3 中,import 语句是实现模块复用的核心语法,它允许你将其他模块中定义的函数、类、变量等引入到当前代码中使用。
注意:一个 .py 文件就是一个模块,模块名就是文件名(不含 .py)。比如 math.py 是模块 math,你写的 utils.py 是模块 utils。
import 语句的基本用法如下:
(1)导入整个模块
import 模块名
用于将整个模块引入当前作用域,要使用模块内的成员时需要加 模块名. 前缀。示例:
# 导入 Python 内置的 math 模块
import math
# 使用 math 模块中的 pi 常量和 sqrt 函数
print(math.pi) # 输出:3.141592653589793
print(math.sqrt(16)) # 输出:4.0
(2)导入模块并指定别名
import 模块名 as 别名
用于为模块起一个简短的别名,尤其适合长模块名,目的是简化我们的输入(例如,一个用于处理 Markdown 的模块名为 forProcessingMarkdown.py 每次都要输入 forProcessingMarkdown 太繁琐了,使用别名机制可以启动一个简短别名)。例如:
# 导入 numpy 并简写为 np(行业通用写法)
import numpy as np
# 导入 pandas 并简写为 pd
import pandas as pd
arr = np.array([1,2,3]) # 使用别名调用模块成员
print(arr) # 输出:[1 2 3]
(3)从模块中导入指定成员(函数 / 类 / 变量)
from 模块名 import 成员1, 成员2, ...
用于只导入模块中需要的部分,无需加模块名前缀,直接使用成员名。例如:
# 只导入 math 模块中的 pi 和 sqrt
from math import pi, sqrt
print(pi) # 直接使用,无需math.前缀
print(sqrt(25)) # 输出:5.0
(4)从模块导入指定成员并指定别名
from 模块名 import 成员名 as 别名
用来解决成员名冲突,或简化成员名。例如:
# 假设自定义了一个 sqrt 函数,避免和 math 模块中的 sqrt 冲突
from math import sqrt as math_sqrt
def sqrt(num):
return num * num
print(math_sqrt(16)) # 用别名调用math的sqrt,输出4.0
print(sqrt(16)) # 调用自定义的sqrt,输出256
(5)导入模块中的所有成员(不推荐使用)
from 模块名 import *
用于导入模块中所有公开成员(公开成员指以非下划线开头的成员),可以直接使用,不需要添加前缀。导入所有成员,容易引发命名冲突(比如两个模块都有 sum 函数)。 代码可读性差,无法判断成员来自哪个模块。 例如:
from math import *
print(pi) # 输出3.141592653589793
print(cos(0)) # 输出1.0
自定义模块
自定义模块是你自己编写的 .py 文件,用于封装自己的代码逻辑,方便在不同项目 / 脚本中复用。
创建自定义模块详细步骤如下:
(1)创建一个 .py 文件(如 my_module.py),写入以下内容:
# my_module.py - 自定义模块示例
# 定义常量
PI = 3.1415926
# 定义函数
def circle_area(radius):
"""计算圆的面积"""
if radius < 0:
raise ValueError("半径不能为负数")
return PI * radius * radius
# 定义类
class Calculator:
"""简单计算器类"""
def add(self, a, b):
return a + b
def subtract(self, a, b):
return a - b
步骤 2:在同一目录下创建另一个脚本(如 main.py),导入并使用自定义模块:
# main.py - 使用自定义模块
# 导入整个自定义模块
import my_module
# 使用模块中的常量
print("圆周率:", my_module.PI)
# 使用模块中的函数
try:
area = my_module.circle_area(5)
print("半径为5的圆面积:", area)
except ValueError as e:
print("错误:", e)
# 使用模块中的类
calc = my_module.Calculator()
print("3 + 5 =", calc.add(3, 5))
print("10 - 4 =", calc.subtract(10, 4))
# 也可以选择性导入
from my_module import circle_area, Calculator
print("半径为3的圆面积:", circle_area(3))
创建成功后,目录结构如下图:

运行 main.py 文件,输出如下:
圆周率: 3.1415926
半径为5的圆面积: 78.539815
3 + 5 = 8
10 - 4 = 6
半径为3的圆面积: 28.274333400000003
运行成功后,会自动在当前文件所在的目录创建一个名为 __pycache__ 文件夹,其中多了一个 my_module.cpython-313.pyc 文件,如下图:
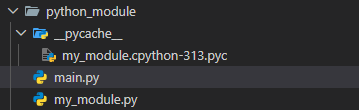
__pycache__ 是 Python 运行时自动生成的文件夹,核心作用是提升模块导入效率。Python 是解释型语言,但并非直接解释源码执行,而是分两步:
当你第一次导入某个模块(如 import my_module)时:
简单来说,__pycache__ 是 Python 的字节码缓存目录,目的是避免重复编译,加速模块导入。
Python广告
模块搜索路径
Python 执行 import 语句时,会按照固定的搜索路径顺序查找对应的模块文件(.py/.pyc/.so 等)。
模块搜索路径本质是一个字符串列表,Python 会按列表顺序依次查找模块,找到第一个匹配的模块就停止;如果遍历完都没找到,就抛出 ModuleNotFoundError。
这个列表可以通过 sys.path 查看和修改,例如:
import sys
print(sys.path)
# 结果:
# ['/home/cloudlab', '/home/cloudlab', '/usr/local/lib/python312.zip',
# '/usr/local/lib/python3.12', '/usr/local/lib/python3.12/lib-dynload',
# '/usr/local/lib/python3.12/site-packages', '/opt/pvc_site_packages']
列表中包含以下几类路径(优先级从高到低):
(1)执行脚本的当前目录(最高优先级)
当你运行 python3 test.py 时,test.py 所在的目录会被优先加入搜索路径。例如:
import sys
import os
# 打印当前脚本所在目录
print("当前脚本目录:", os.path.abspath(".")) # 输出:当前脚本目录: /home/cloudlab
# 打印搜索路径列表的第一个元素(通常就是当前目录)
print("sys.path[0]:", sys.path[0]) # 输出:sys.path[0]: /home/cloudlab
(2)PYTHONPATH 环境变量指定的目录
PYTHONPATH 是 Python 专属的环境变量,你可以手动添加自定义路径,让 Python 能找到这些路径下的模块。
(3)Python 标准库目录
Python 内置模块(如 math、os、sys)所在的目录,由 Python 安装路径决定,无需手动配置。例如:
import sys
# 查找标准库目录(通常包含 site-packages 上级目录)
for path in sys.path:
if "lib/python3." in path and "site-packages" not in path:
print("标准库目录:", path)
# 输出:
# 标准库目录: /usr/local/lib/python3.12
# 标准库目录: /usr/local/lib/python3.12/lib-dynload
(4)site-packages 目录(第三方库目录)
这是安装第三方库(如 numpy、pandas)的默认目录,pip install 安装的包都会放在这里,Python 会自动将其加入搜索路径。例如:
import site
# 打印 site-packages 目录路径
print("第三方库目录:", site.getsitepackages())
# 输出:
# 第三方库目录: ['/usr/local/lib/python3.12/site-packages']
(5)虚拟环境的路径
如果使用虚拟环境(venv/conda),Python 会优先使用虚拟环境内的 site-packages 目录,隔离全局环境的依赖。
修改搜索路径
临时修改搜索路径
通过修改 sys.path 列表,可以临时添加自定义路径(程序退出后失效),这是解决模块找不到的常用临时方案。例如:
import sys
import os
# 添加自定义模块目录(绝对路径)
my_module_path = "/home/user/my_custom_modules"
if my_module_path not in sys.path:
sys.path.append(my_module_path) # 追加到列表末尾(优先级低)
# sys.path.insert(0, my_module_path) # 插入到列表开头(优先级最高)
# 现在可以导入 /home/user/my_custom_modules 下的模块了
import my_module
永久修改搜索路径
永久修改修改搜索路径有两种方式:
(1) 修改 PYTHONPATH 环境变量
export PYTHONPATH="/home/user/my_modules:$PYTHONPATH"
执行 source ~/.bashrc 生效。
(2)创建 .pth 文件
在 site-packages 目录下创建一个 .pth 文件(如 my_paths.pth),内容为要添加的路径(每行一个):
/home/user/my_modules
/opt/another_modules
Python 启动时会自动加载 .pth 文件中的路径到 sys.path。
Python广告
安装第三方模块
第三方模块是由社区 / 开发者开发的、非 Python 内置的模块,需要手动安装后才能使用。
在 Python 中,pip 是官方推荐的包管理工具,用于安装、升级和卸载第三方模块,和 Linux 中 的 apt 类似。
pip 命令简单用法:
(1)安装指定模块,语法如下:
pip install 模块名
例如: 安装数据分析库 pandas ,自动安装当前最新稳定版。
$ pip install pandas
(2)安装指定版本的模块,如果需要固定模块版本(避免版本兼容问题),语法如下:
pip install 模块名==版本号
例如:安装 pandas 2.0.0 版本
$ pip install pandas==2.0.0
Defaulting to user installation because normal site-packages is not writeable
Collecting pandas==2.0.0
Downloading pandas-2.0.0.tar.gz (5.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.3/5.3 MB 2.2 MB/s eta 0:00:00
Installing build dependencies ... done
...
(3)升级已安装的模块,语法如下:
pip install --upgrade 模块名
# 简写
pip install -U 模块名
示例:升级 pandas 到最新版本
$ pip install -U pandas
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: pandas in d:\anaconda3\lib\site-packages (2.2.3)
Collecting pandas
Downloading pandas-3.0.1-cp313-cp313-win_amd64.whl.metadata (19 kB)
Requirement already satisfied: numpy>=1.26.0 in d:\anaconda3\lib\site-packages (from pandas) (2.1.3)
Requirement already satisfied: python-dateutil>=2.8.2 in c:\users\administrator\appdata\roaming\python\python313\site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: tzdata in d:\anaconda3\lib\site-packages (from pandas) (2025.2)
Requirement already satisfied: six>=1.5 in c:\users\administrator\appdata\roaming\python\python313\site-packages (from python-dateutil>=2.8.2->pandas) (1.17.0)
Downloading pandas-3.0.1-cp313-cp313-win_amd64.whl (9.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.7/9.7 MB 1.3 MB/s eta 0:00:00
Installing collected packages: pandas
...
Successfully installed pandas-3.0.1
pip 的基础命令总结:
# 检查 pip 版本(确认是否安装)
# 或 pip3 --version(区分 Python2/3)
pip --version
# 安装指定模块(最新版本)
pip install 模块名 # 如:pip install requests
# 安装指定版本
pip install 模块名==版本号 # 如:pip install requests==2.31.0
# 升级模块
pip install --upgrade 模块名 # 如:pip install --upgrade requests
# 卸载模块
pip uninstall 模块名 # 如:pip uninstall requests
# 查看已安装的第三方模块
$ pip list
Package Version
------------------------- -----------
annotated-types 0.7.0
anyio 4.9.0
astor 0.8.1
asttokens 3.0.0
attrs 25.3.0
beautifulsoup4 4.13.4
black 22.8.0
...
# 查看指定模块的信息
pip show 模块名 # 如:pip show requests
$ pip show requests
Name: requests
Version: 2.32.4
Summary: Python HTTP for Humans.
Home-page: https://requests.readthedocs.io
Author: Kenneth Reitz
Author-email: me@kennethreitz.org
License: Apache-2.0
Location: D:\Program Files\Python313\Lib\site-packages
Requires: certifi, charset_normalizer, idna, urllib3
Required-by: mcp-server-fetch
解决下载慢的问题
由于网络原因,推荐使用国内镜像源安装,这样安装的速度将会更快:
(1)临时使用,通过 pip 命令临时指定镜像地址,如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
(2)永久配置,通过配置文件指定镜像地址,如下:
# Windows:在用户目录下创建 pip/pip.ini,写入:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
# Linux/Mac:在用户目录下创建 .pip/pip.conf,写入同上内容
包(Package)
包(Package)是 Python 中组织代码的方式,本质上是一个包含 __init__.py 文件的文件夹,用于将相关的模块(.py 文件)分组管理,解决模块命名冲突、代码结构混乱的问题。
包的构成
一个包有下面部分构成:
文件夹:包的物理载体,名称就是包名(遵循 Python 标识符规则,小写 + 下划线)。
__init__.py:包的标识文件(Python 3.3+ 支持“隐式命名空间包”,可省略,但建议始终保留),可以是空文件,也可用于初始化包、导出模块 / 变量等。
模块文件:包内的 .py 文件,比如 utils.py、core.py 等,是实际存放代码的地方。
子包:包内的子文件夹(同样包含 __init__.py),形成嵌套结构。
包的作用
使用包,主要作用如下:
避免模块名冲突:不同包下的模块可以同名(比如 pkg1/utils.py 和 pkg2/utils.py 互不冲突)。
模块化管理代码:将功能相关的代码归到同一个包,比如 requests 包处理 HTTP 请求,numpy 包处理数值计算。
方便代码复用:包可以被其他项目导入使用,是第三方库的基础形式。
包的基本使用
先搭建一个典型的包结构,以数据分析工具包“ data_analysis”为例,如下图:
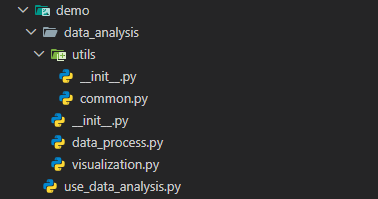
各个文件的作用说明:
data_analysis/ # 根包
├── __init__.py # 包初始化文件
├── data_process.py # 数据处理模块
├── visualization.py # 可视化模块
└── utils/ # 子包
├── __init__.py
└── common.py # 通用工具模块
其中,各个文件内容如下:
def clean_data(df):
"""清洗数据:去除空值"""
return filter(lambda x: x % 2 == 0, df)
def normalize_data(df):
"""数据标准化"""
return map(lambda x: x * 2, df)
def plot_line_chart():
print('Plotting line chart...')
def print_info(msg):
"""打印带时间戳的信息"""
from datetime import datetime
print(f"[{datetime.now()}] {msg}")
__init__.py 文件
__init__.py 是 Python 中标识包(Package) 的核心文件,它的核心作用是将普通文件夹转换为 Python 可识别的包,让文件夹内的 .py 文件可以被 import 导入。
如果存在一个目录:
__init__.py 不仅是 “标记文件”,还可以编写代码,实现以下功能:
(1)控制对外暴露的接口
默认情况下,导入包时需要写完整路径(如 from my_package.module1 import func1),通过 __init__.py 可以简化导入,让用户直接从包名导入核心功能。例如:
# 1.导出当前模块中的函数,让外部可以直接从当前包导入的函数
# 用来控制 from...import 语句能够导入的函数
# 相当于对外暴露出哪些函数能够被使用
from .data_process import clean_data, normalize_data
from .utils.common import print_info
# 2.定义 __all__(配合 from package import * 使用)
# 该配置用来控制 “from 模块 import *” 语句能够导入的函数
# 如果不指定 __all__,则 from ... import * 可以导入上面 from import 导出的所有函数
# 如果指定了 __all__,则 from ... import * 则仅仅能导入 __all__ 指定的函数
__all__ = ["clean_data", "normalize_data", "print_info"]
(2)初始化包的全局变量/资源
可以在 __init__.py 中定义包级别的常量、初始化配置等,包内所有模块均可访问。例如:
# my_package/__init__.py
# 定义包的版本号(全局常量)
__version__ = "1.0.0"
# 初始化配置
DEFAULT_CONFIG = {
"timeout": 30,
"encoding": "utf-8"
}
# 导入时执行初始化逻辑
print(f"正在加载 my_package v{__version__}")
__init__.py 内容如下:
from .data_process import clean_data, normalize_data
from .visualization import plot_line_chart
from .utils.common import print_info
__all__ = ["print_info"]
utils/__init__.py 内容如下:
from .common import print_info
__all__ = ["print_info"]
使用自定义包
在 use_data_analysis.py 文件中编写如下代码,导入 data_analysis 包暴露的函数,如下:
# 从 data_analysis 包中导入函数
from data_analysis import clean_data, normalize_data, print_info
# 使用包中的函数
val1 = clean_data([1,2,3,4,5])
print(list(val1))
val2 = normalize_data([1,2,3,4,5])
print(list(val2))
print_info("hello world")
运行结果:
[2, 4]
[2, 4, 6, 8, 10]
[2026-03-23 17:43:48.726446] hello world
如果将上面代码的“from data_analysis import clean_data, normalize_data, print_info”语句改为“from data_analysis import print_info”,如下:
from data_analysis import *
# 使用包中的函数
# 不能使用,在 __all__ 中没有声明
# val1 = clean_data([1,2,3,4,5])
# print(list(val1))
# 不能使用,在 __all__ 中没有声明
# val2 = normalize_data([1,2,3,4,5])
# print(list(val2))
print_info("hello world")
Python广告
虚拟环境(Virtual Environment)
虚拟环境(Virtual Environment)是 Python 中隔离不同项目依赖的核心工具,解决了一个系统中多个项目需要不同版本模块的经典问题。
例如项目 A 需要 requests 2.20,项目 B 需要 requests 3.0,如下图:
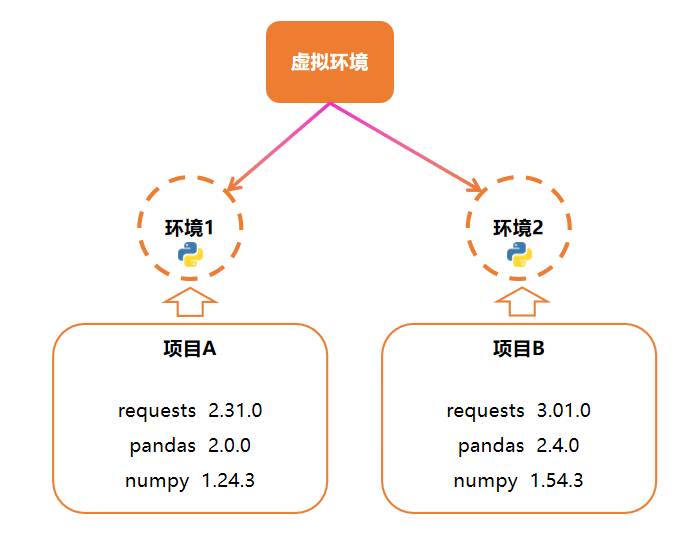
注意,虚拟环境本质是一个独立的文件夹,包含:
当激活虚拟环境时,系统会临时修改环境变量(如 PATH),让终端优先使用该环境内的 Python/pip,而非系统全局的。
Python 3.4 及以上版本内置了 venv 模块,无需额外安装,是官方推荐的虚拟环境工具。
创建虚拟环境
# 语法:python -m venv 虚拟环境目录名
# -m 表示运行 Python 的内置模块,这里运行的是 venv 模块(虚拟环境模块)
# 最后一个 venv 是虚拟环境的文件夹名称(可自定义,比如 myenv)
python -m venv venv
注意,目录名推荐用 venv 或 .venv(隐藏目录),是行业通用规范。
当上述命令执行成功后,会在用户主目录中创建一个名为 venv 的目录,如下图:
打开 venv 目录,目录中的内容如下图:
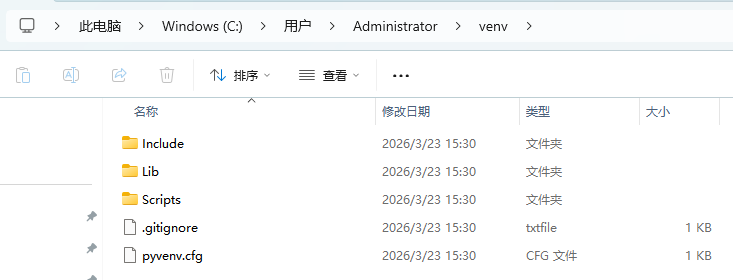
进入到 Scripts 目录,其中包含了 pip.exe、pip3.exe、python.exe 和 activate.bat 等命令,如下图:
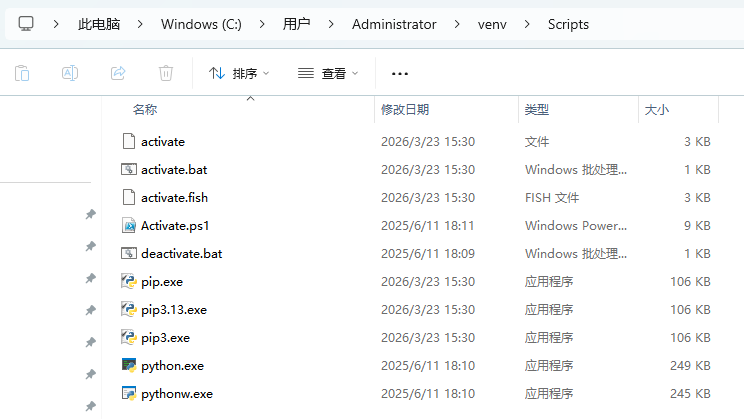
激活虚拟环境
上面成功创建了一个名为 venv 的环境,下面来激活 venv 环境。环境激活后,终端提示符会显示环境名(如 (venv)),表示当前操作生效于该环境。
例如:执行如下命令
C:\Users\Administrator\venv> Scripts\activate.bat
激活后,命令提示符如下图:

使用虚拟环境
虚拟环境激活后,python/pip 命令会指向该环境内的版本,安装的模块仅存于该环境,例如:
(venv) C:\Users\Administrator\venv> pip install pandas
Collecting pandas
Using cached pandas-3.0.1-cp313-cp313-win_amd64.whl.metadata (19 kB)
Collecting numpy>=1.26.0 (from pandas)
Using cached numpy-2.4.3-cp313-cp313-win_amd64.whl.metadata (6.6 kB)
Collecting python-dateutil>=2.8.2 (from pandas)
Using cached python_dateutil-2.9.0.post0-py2.py3-none-any.whl.metadata (8.4 kB)
Collecting tzdata (from pandas)
Downloading tzdata-2025.3-py2.py3-none-any.whl.metadata (1.4 kB)
Collecting six>=1.5 (from python-dateutil>=2.8.2->pandas)
Using cached six-1.17.0-py2.py3-none-any.whl.metadata (1.7 kB)
Using cached pandas-3.0.1-cp313-cp313-win_amd64.whl (9.7 MB)
Using cached numpy-2.4.3-cp313-cp313-win_amd64.whl (12.3 MB)
Using cached python_dateutil-2.9.0.post0-py2.py3-none-any.whl (229 kB)
Using cached six-1.17.0-py2.py3-none-any.whl (11 kB)
Downloading tzdata-2025.3-py2.py3-none-any.whl (348 kB)
Installing collected packages: tzdata, six, numpy, python-dateutil, pandas
Successfully installed numpy-2.4.3 pandas-3.0.1 python-dateutil-2.9.0.post0 six-1.17.0 tzdata-2025.3
[notice] A new release of pip is available: 25.1.1 -> 26.0.1
[notice] To update, run: python.exe -m pip install --upgrade pip
执行上面语句,将在 venv 环境中安装最新版本的 pandas。然后,访问 venv\Lib\site-packages 目录,下面存放的就是我们刚才安装的库。
导出 / 导入依赖清单
为了确保项目在不同环境下面拥有相同版本的依赖项,我们可以通过 pip freeze 命令把当前项目已经装好的所有包和版本号,保存到一个文件里(通常是 requirements.txt)。如下:
pip freeze > requirements.txt
这样别人就能知道你用了哪些版本,避免环境不一致。
当要其他人也需要运行该项目时,可以通过 pip install -r 命令一次性安装项目所有的依赖,而且依赖的版本项和你完全一致,另一个环境就复刻出来了。如下:
pip install -r requirements.txt
上面命令就会自动把项目依赖一起装上,避免手动一个一个的安装,requirements.txt 类似 java 项目中的 pom.xml 文件。
总结起来:导出,即把当前环境“拍照存档”;导入,即按存档恢复一模一样的环境。
退出虚拟环境
执行 deactivate 命令退出虚拟环境,虚拟环境退出后,终端提示符的 (venv) 消失,恢复使用系统全局 Python。例如:
# 任意系统通用命令
deactivate
删除虚拟环境
当虚拟环境不再需要时,可以直接删除虚拟环境文件夹即可,例如:
# Linux/Mac
rm -rf venv
# Windows(CMD)
rmdir /s /q venv
Python广告
其他虚拟环境工具
除了内置的 venv,还有更便捷的第三方工具,适合复杂项目:
virtualenv(兼容 Python2/3)
virtualenv 是一个用于创建独立 Python 环境的工具。它可以帮助我们在同一台机器上同时拥有多个不同版本的 Python 环境,并且每个环境之间相互隔离,不会互相影响。
virtualenv 解决了以下问题:
依赖冲突:不同的项目可能依赖于相同包的不同版本,virtualenv 允许每个项目拥有独立的包依赖,避免版本冲突。
环境隔离:virtualenv 允许我们创建干净的 Python 环境,可以用于测试或实验新的包或代码,而不会影响全局 Python 环境。
权限问题:virtualenv 可以在没有管理员权限的情况下安装 Python 包。
自 Python 3.3 起,标准库中包含了 venv 模块,它也用于创建虚拟环境。但是,virtualenv 提供了一些 venv 没有的功能:
更高的性能(因为它具有 app-data 种子方法)。
支持为任意安装的 Python 版本创建虚拟环境,并能自动发现它们。
能够通过 pip 升级。
提供更丰富的编程 API,可以在不创建虚拟环境的情况下描述它们。
virtualenv 的安装和使用:
安装 virtualenv
首先,确保你已经安装了 Python 和 pip。然后可以通过以下命令安装 virtualenv:
$ pip install virtualenv
Collecting virtualenv
Downloading virtualenv-21.2.0-py3-none-any.whl.metadata (3.5 kB)
Collecting distlib<1,>=0.3.7 (from virtualenv)
Downloading distlib-0.4.0-py2.py3-none-any.whl.metadata (5.2 kB)
Collecting filelock<4,>=3.24.2 (from virtualenv)
Downloading filelock-3.25.2-py3-none-any.whl.metadata (2.0 kB)
Requirement already satisfied: platformdirs<5,>=3.9.1 in C:\Users\Administrator\AppData\Roaming\Python\Python313\site-packages (from virtualenv) (4.3.8)
Collecting python-discovery>=1 (from virtualenv)
Downloading python_discovery-1.2.0-py3-none-any.whl.metadata (5.4 kB)
Downloading virtualenv-21.2.0-py3-none-any.whl (5.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.8/5.8 MB 85.6 kB/s 0:00:58
Downloading distlib-0.4.0-py2.py3-none-any.whl (469 kB)
Downloading filelock-3.25.2-py3-none-any.whl (26 kB)
Downloading python_discovery-1.2.0-py3-none-any.whl (31 kB)
Installing collected packages: distlib, filelock, python-discovery, virtualenv
Successfully installed distlib-0.4.0 filelock-3.25.2 python-discovery-1.2.0 virtualenv-21.2.0
安装完成后,可以通过 virtualenv --version 来确认安装是否成功,例如:
$ virtualenv --version
virtualenv 21.2.0 from D:\Program Files\Python313\Lib\site-packages\virtualenv\__init__.py
创建虚拟环境
使用 virtualenv 命令可以轻松创建虚拟环境,并指定环境目录:
virtualenv <环境目录名>
例如,创建一个名为 myenv 的虚拟环境:
$ virtualenv myenv
could not migrate app data from C:\Users\Administrator\AppData\Local\pypa\virtualenv to C:\Users\Administrator\AppData\Local\pypa\virtualenv\Cache: Error("Cannot move a directory 'C:\\Users\\Administrator\\AppData\\Local\\pypa\\virtualenv' into itself 'C:\\Users\\Administrator\\AppData\\Local\\pypa\\virtualenv\\Cache'."), using old location
created virtual environment CPython3.13.5.final.0-64-x86_64 in 658ms
creator CPython3Windows(dest=C:\Users\Administrator\myenv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, via=copy, app_data_dir=C:\Users\Administrator\AppData\Local\pypa\virtualenv)
added seed packages: pip==26.0.1
activators BashActivator,BatchActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
这会在当前目录下创建一个名为 myenv 的文件夹,包含 Python 解释器和常见的包管理工具。
激活虚拟环境
在 Linux/macOS 中,使用 source 命令激活虚拟环境:
source myenv/bin/activate
在 Windows 中,使用以下命令:
.\myenv\Scripts\activate.bat
激活后,命令提示符会变成如下所示,显示虚拟环境的名称:
(myenv) C:\Users\Administrator>
此时,所有的 Python 包安装操作都将在该虚拟环境中进行,而不会影响全局环境。
停用虚拟环境
完成工作后,你可以使用 deactivate 命令来停用虚拟环境:
.\myenv\Scripts\deactivate.bat
停用后,命令行会恢复到系统的全局环境。
Anaconda
Anaconda 是一个面向数据科学与机器学习的 Python 发行版,核心作用就是:
一键装好 Python + 常用科学计算库(NumPy、Pandas、Matplotlib 等)+ 环境管理工具,不用自己一个个配依赖。
使用浏览器访问 https://www.anaconda.com/ 地址,如下图:
根据需要,下载需要的版本,然后成功安装 Anaconda。
启动 Anaconda,界面如下图:

点击“Environments”查看当前创建的所有 Python 虚拟环境,如下图:
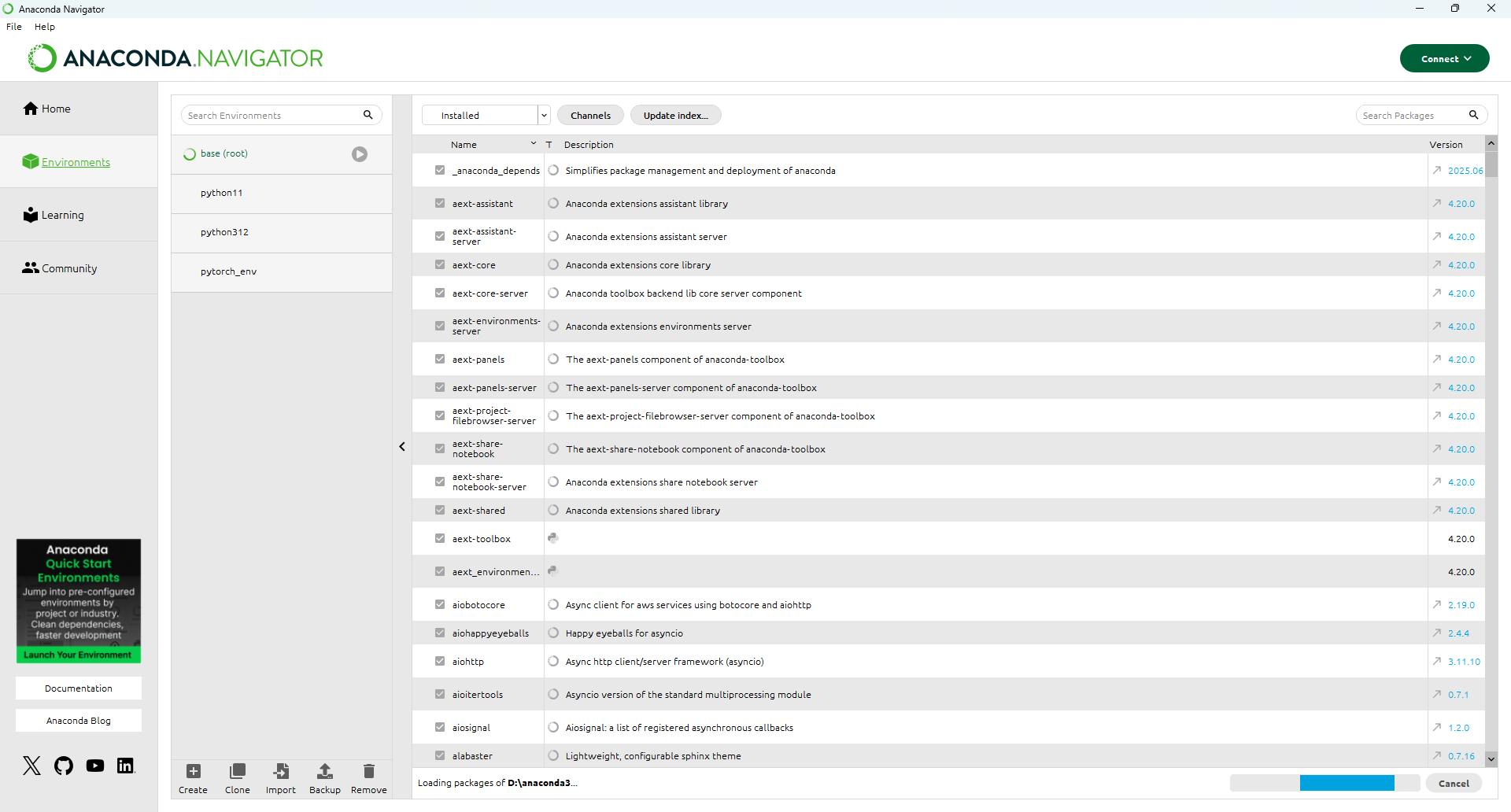
点击底部的  按钮,管理虚拟环境。
按钮,管理虚拟环境。
下面是 Anaconda 的管理命令,如下:
# 验证 Anaconda 是否安装成功(查看版本)
conda --version
conda -V
# 激活环境
conda activate 环境名称
# 升级 conda 本身(建议定期升级)
conda update conda -y # -y 自动确认所有提示
# 查看 conda 所有命令帮助
conda --help
# 查看某个命令的详细用法(如 create)
conda create --help
# 列出所有已创建的虚拟环境
conda info --envs
conda env list # 简写,更常用
# 基础语法:conda create -n 环境名 python=版本号 -y
conda create -n my_env python=3.10 -y # 创建名为 my_env、Python3.10 的环境
# 创建时直接安装指定包
conda create -n ml_env python=3.9 numpy pandas -y
# 复制环境(基于已有环境创建新环境)
conda create -n new_env --clone my_env -y
# 删除环境
conda remove -n my_env --all -y
# 基础语法:conda install 包名=版本号 -y
conda install numpy -y # 安装最新版 numpy
conda install pandas=2.0.0 -y # 安装指定版本 pandas
# 从指定频道(源)安装(如清华源)
conda install -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ scipy -y
# 安装多个包
conda install numpy pandas matplotlib -y
# 也可使用 pip(环境内)
pip install requests # 适合 conda 仓库没有的包
# 查看当前环境已安装的所有包
conda list
# 查看指定包的信息(如 numpy)
conda list numpy
# 搜索 conda 仓库中的包
conda search tensorflow
# 更新指定包
conda update numpy -y
# 更新当前环境所有包
conda update --all -y
# 卸载包
conda remove numpy -y
更多 Python3 知识,请继续学习后续章节。

 川公网安备51010802032098
川公网安备51010802032098