本章将介绍 Python3 中关于文件的操作(读取和写入,I/O,Input/Output),文件操作对编程非常重要,通常我们通过文件(txt、csv、json 等)提供数据,而不是通过控制台输入。而且,程序处理后的结果也往往写入到文件中,并非输出到控制台。
在 Python3 中,对文件操作进行了高度封装,提供了语法简洁、安全性高的文件处理方法。
Python3 原生就支持读取、写入、追加、关闭等基础操作(不需要使用 import 导入库),同时内置自动资源管理、字符编码处理等功能。这无疑降低了对文件操作的门槛,又能有效避免内存泄漏(忘记释放资源)、数据丢失等问题。
文件路径
在操作文件之前,必须先准确告诉 Python ,待操作文件的具体位置,这个位置就是文件路径。文件路径是连接程序与文件的桥梁,路径错误会直接导致 FileNotFoundError(文件没有找到)异常。
下面是 Windows 中的文件路径(Windows 中使用反斜杠分隔路径):
C:\Users\Administrator\.conda\envs\python308\LICENSE_PYTHON.txt
下面是 Linux 中的文件路径(Linux 中使用斜杠分隔路径):
/etc/nginx/modules-enabled/50-mod-http-xslt-filter.conf
注意,上面两个路径指定了文件的完整路径,我们称为绝对路径。什么是绝对路径下面将进行介绍?
绝对路径
绝对路径是文件在计算机中的完整、唯一路径,从磁盘根目录开始,一直精确到目标文件,不受程序运行位置影响。在 Windows 中,从盘符开始,如 C:\xxx 或 D:\xxx,盘符在 Windows 中就是根路径。而在 Linux/Unix/max 系统中,根即 /,所有的磁盘路径均从 / 开始。
绝对路径的特点:固定不变、定位精准,适合固定位置的文件;例如:
注意:Windows 中路径的 \ 是转义字符,Python 中需写为 \\ 或使用原始字符串 r"C:\Users\test.txt"。
相对路径
相对路径是相对于当前程序运行目录的文件路径,不写完整根目录,简洁灵活。相对路径中有两个特殊符号:
例如,我们有一个 python 脚本,完整路径为 C:\Users\Administrator\python\demo\hello.py,如下图:
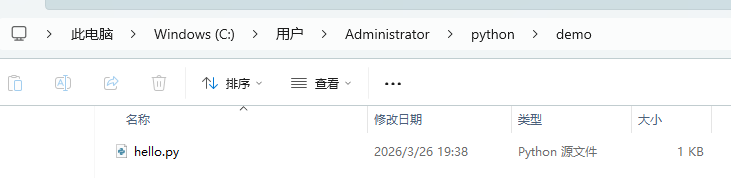
如果我们在 C:\Users\Administrator\python 目录下面执行 python demo\hello.py,如下图:
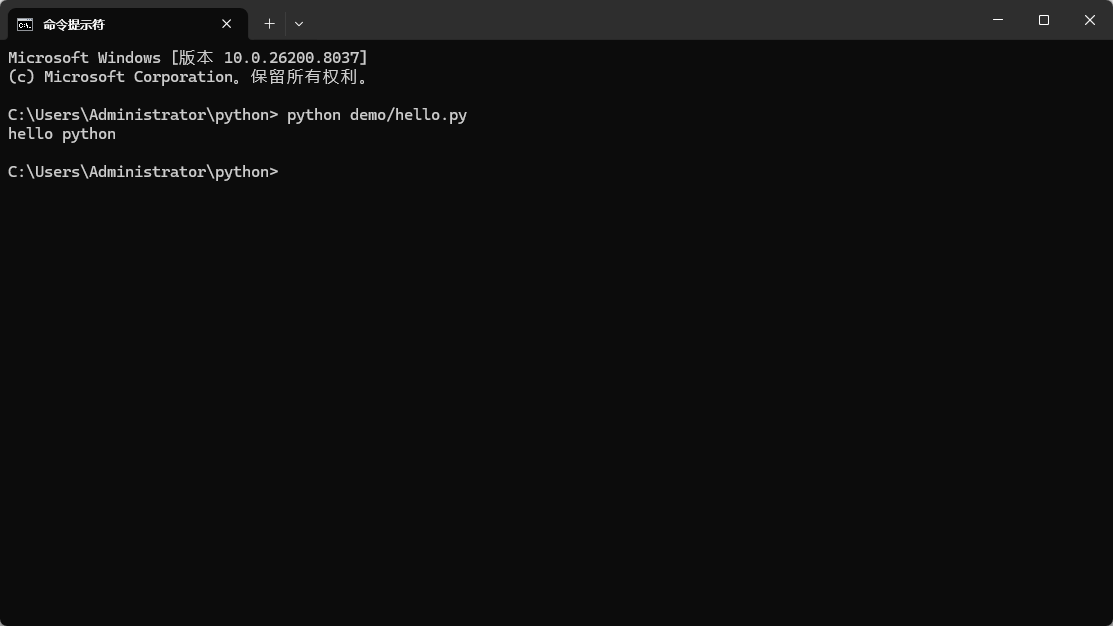
成功运行了 hello.py 脚本,其中 demo/hello.py 就是相对路径,相对当前目录 C:\Users\Administrator\python,去查找 demo\hello.py 脚本。
如果我们将 hello.py 脚本移动到上级目录 C:\Users\Administrator\python 中,如下图:
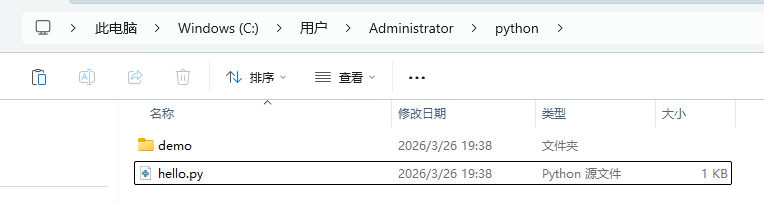
此时,当前目录为 C:\Users\Administrator\python\demo,则可以通过“..”定位到上级目录执行 hello.py 脚本,如下图:
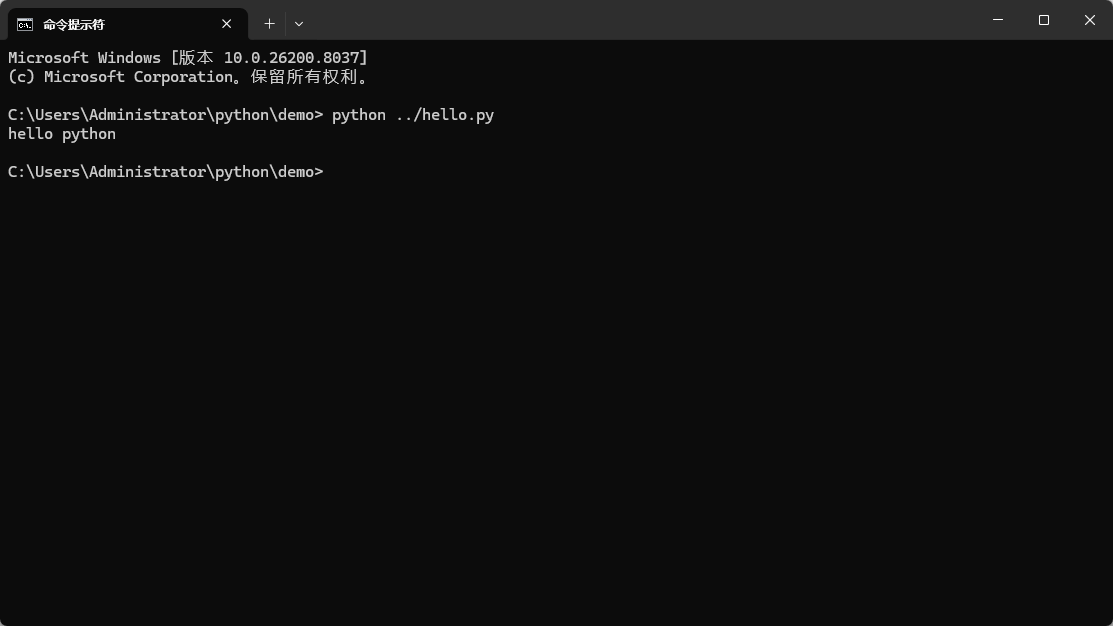
依旧执行成功,记住了,一个“..”代表一层上级目录,如果是两层上级目录,则使用“../..”,三层或多层依次类推。
相对目录的特点:依赖程序运行位置,适合项目内部文件(如配置文件、数据文件),如果程序运行位置发生变化,相对路径会失效。
相对目录的基础写法:
直接写文件名:data.txt(表示程序当前目录下的文件)
子目录:files/log.txt(当前目录下 files 文件夹中的文件)
上级目录:../config.txt(当前目录的上一级目录中的文件)
上上级目录:../../config.txt(当前目录的上上级目录中的文件)
Python广告
文件打开和关闭
记住了,操作文件的标准流程如下图:

注意:关闭文件是必要的步骤,忘记关闭会占用系统资源,甚至导致文件数据无法正常保存。你可以想象你去洗手,先打开水龙头、洗手,最后却忘记关闭水龙头,会怎么样呢?
open() 函数
open() 是 Python3 内置函数,用于打开文件,返回一个文件对象(文件句柄),所有文件读写操作都基于这个对象。如果该文件不能被打开,则引发 OSError 错误。
open() 语法如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
open("test.txt") # 相对路径(当前文件夹)
open("/home/user/a.txt") # 绝对路径
r 表示只读(默认),文件必须存在,否则报错。
w 表示只写,如果文件不存在则创建,如果存在则清空文件内容。
a 表示追加写入,如果文件不存在则创建,写入的内容追加到文件的末尾。
r+ 表示读写,文件必须存在。
w+ 表示读写,先清空文件,再读写。
a+ 表示追加 + 读写,写入的内容永远添加在文件末尾。
b 表示二进制模式,用于图片、视频、exe 等文件(如 'rb'、'wb')。
t 表示文本模式(默认),用于文本文件(如 'rt'、'text')。
# 打开中文文本不乱码
open("test.txt", "r", encoding="utf-8")
0:关闭缓冲(仅二进制模式可用)
1:行缓冲(仅文本模式)
其他整数:自定义缓冲区大小
读取时:将所有换行符统一转为 \n
写入时:将 \n 转为系统默认换行符
常用值:''(禁止自动转换换行符)
with open
with 是 Python 的上下文管理器语法,作用就是自动帮你管理资源,不用手动开关 / 释放。使用 with 时:
在代码块开始时自动执行初始化 / 打开操作
在代码块结束时自动执行清理 / 关闭操作
即使中途报错、异常退出,with 也能保证资源被正常释放。
如果我们将 with 搭配 open() 使用时,语法如下:
with open(文件路径, 模式, 编码...) as 文件对象:
# 在这里读写文件
with 会自动帮我们干下面这些事:
自动打开文件
代码块结束后自动关闭文件
即使报错也能安全关闭,不会损坏文件
示例:这是传统方式打开和读取文件,必须手动关闭文件。
f = open("test.txt", "r", encoding="utf-8")
content = f.read()
f.close() # 必须手动写,忘记写就会造成文件泄漏
相比传统方式,更推荐使用 with open() 方式,如下:
with open("test.txt", "r", encoding="utf-8") as f:
content = f.read()
注意,当运行时出了 with 缩进代码块,文件会自动关闭,完全不用手动调用 close() 方法关闭文件。
读文件
读取文件指将磁盘上文件中的数据加载到程序中,而 Python 提供了多种读取方法,适配不同大小、不同格式的文件,下面将分别介绍。
read() 函数
read() 函数会一次性读取文件的全部内容,返回一个字符串。注意,该函数仅仅适合小型文件,如配置文件、短文本。如果使用该函数读取大文件,会导致占用大量内存,导致程序卡顿。
示例:
假如 test.txt 文件内容如下:
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
Python 脚本如下:
with open("test.txt", "r", encoding="utf-8") as f:
content = f.read() # 读取全部内容
print(content)
运行结果:
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
readline() 函数
readline() 函数每次只读取文件的一行内容,读取完毕后指针移动到下一行。该函数特别适合需要逐行处理数据的场景,如读取日志、表格文件等等,不用一次性把整个文件读进内存,更省资源。
示例:复用前面的 test.txt 文件
with open("test.txt", "r", encoding="utf-8") as f:
line1 = f.readline() # 读取第一行
print(line1, end="")
line2 = f.readline() # 读取第二行
print(line2, end="")
readlines() 函数
readlines() 函数用来一次性读取文件的所有行,返回一个列表,列表中每个元素对应文件的一行。该函数适合需要对所有行进行批量处理的场景。
示例:复用前面的 test.txt 文件
with open("test.txt", "r", encoding="utf-8") as f:
# ['第一行内容\n', '第二行内容\n', ...]
lines = f.readlines()
for line in lines:
print(line, end="")
注意,这个函数和 read() 函数一样,也是一次性将文件的内容读取到内存中,不要使用该函数来读取大文件,避免消耗大量内存。
大文件读取
假如给你一个 10 GB 大小的文件,你该如何最优读取呢?使用 read() 或 readlins() 函数读取,这肯定行不通,一次性至少需要 10 GB 内存,哪里有那么多的内存。而且很容易导致内存不足、程序卡顿或崩溃。
此时,推荐使用 readline() 函数逐行迭代读取,这样内存占用极低(仅仅需要存储一行数据的内容)。每次只加载一行数据到内存,处理完就释放,内存始终只占很小空间,效率更稳定,也不会导致内存爆满。
示例:
with open("test.txt", "r", encoding="utf-8") as f:
# 逐行读取,无需手动调用 readline()
for line in f:
# 处理每一行数据
print(line.strip())
文件指针

文件指针就是文件里的位置标记,用来标记接下来要从哪里读、往哪里写。注意:
打开文件时,指针默认在文件开头;
读取内容后,指针会向后移动;
指针移动到末尾,再次读取会返回空内容;
那么,如何控制指针呢?可以通过 seek(偏移量) 函数手动移动指针到指定位置。
语法格式:
seek(偏移量, 参考位置)
参数说明:
正数:向文件末尾移动
负数:向文件开头移动(仅支持二进制模式)
0:文件开头(最常用)
1:当前指针位置
2:文件末尾
示例 1:从文件开头偏移
# 用 rb 二进制模式,不会自动解码
with open("test.txt", "rb") as f:
# 移动指针,跳过5个字节
# 如果不采用二进制,会出现错误
f.seek(5)
# 读取字节
content = f.read()
# 安全解码,跳过不完整字节,避免错误
print(content.decode("utf-8", errors="ignore"))
运行结果:
明月光,疑是地上霜。
举头望明月,低头思故乡。
示例 2:读取文件末尾内容
with open("test.txt", "rb") as f:
# 指针移到文件末尾
f.seek(0, 2)
# 从末尾向前移动10字节,读取最后10字节
f.seek(-10, 2)
print(f.read().decode("utf-8", errors="ignore"))
运行结果:
故乡。
示例 3:重置指针到文件开头
with open("test.txt", "r", encoding="utf-8") as f:
print(f.read()) # 第一次读取,指针到末尾
f.seek(0) # 重置指针到文件开头
print(f.read()) # 再次读取全部内容
运行结果:
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
示例 4:基于当前位置偏移
with open("test.txt", "rb") as f:
f.seek(10) # 移到第10字节
f.seek(5, 1) # 在当前位置再向后移5字节 → 总15字节
print(f.tell()) # tell() 查看当前指针位置 → 输出15
# 读取字节
content = f.read()
print(content.decode("utf-8", errors="ignore"))
运行结果:
15
,疑是地上霜。
举头望明月,低头思故乡。
Python广告
写文件
写文件指将程序中的数据保存到本地磁盘文件中,实现数据的持久化。
在 Python 中,提供了两种写文件模式,分别是:覆盖写和追加写,下面将分别详细介绍。
覆盖写
“覆盖”的意思是指一个物体或事物遮盖、覆盖另一个物体或范围,使其被隐藏或包裹起来。
覆盖写(overwrite)是计算机科学技术名词,指在存储介质原有数据位置写入新数据的操作过程。这就会导致旧数据被新数据覆盖,从而旧数据丢失。
在 Python3 中,覆盖写需通过 w 模式打开文件,然后先清空文件原有全部内容,再写入新的数据。如果文件不存在,就自动新建一个文件。主要特点是旧内容会被直接删掉,只保留最新写入的内容。
注意:操作一定要非常谨慎,操作不当可能会导致文件数据丢失。例如,在磁盘上有一个保存着重要数据的文件名为 my_data.txt,而刚好你要进行写出的文件名也为 my_data.txt,恰巧又使用了覆盖写模式,那么程序会自动将磁盘上已经存在的 my_data.txt 文件清空,写入新数据。这就导致以前的重要数据没有了,而且原来的内容基本无法恢复,即使能恢复,难度也极大,几乎等于“找不回来”。
📢重要提示:尽量不用覆盖写,或者覆盖写之前先判断文件是否存在。如果文件存在,则对文件进行备份,或者给出错误提示,程序退出。
示例:
with open("test.txt", "w+", encoding="utf-8") as f:
# 读取原有内容
content = f.read()
print(f"原始内容:{content}") # 为空,原始内容被清空了
# 写入新内容
f.write("这是新内容,原有内容会被清空!")
# 再次读取内容
f.seek(0) # 将文件指针移动到文件开头
content = f.read()
print(f"新增内容:{content}")
执行结果:
原始内容:
新增内容:这是新内容,原有内容会被清空!
追加写
覆盖写入会清空原有内容,然后将新的内容写入文件。而追加写入则是在原有内容的末尾继续添加新的内容。
在 Python 中,使用 a 模式打开文件,执行追加写入操作。追加写时执行的动作如下:
通过上述可知,追加写操作适合日志记录、数据累加保存等等。
示例:
with open("test.txt", "a+", encoding="utf-8") as f:
# 文件原始内容
f.seek(0)
content = f.read()
print(f"文件原始内容:\n{content}")
# 追加到文件最后
f.write("长风破浪会有时,直挂云帆济沧海。\n")
f.write("海内存知己,天涯若比邻。\n")
f.seek(0)
content = f.read()
print(f"文件追加后的内容:\n{content}")
运行结果:
with open("test.txt", "a+", encoding="utf-8") as f:
# 文件原始内容
f.seek(0)
content = f.read()
print(f"文件原始内容:\n{content}")
# 追加到文件最后
f.write("长风破浪会有时,直挂云帆济沧海。\n")
f.write("海内存知己,天涯若比邻。\n")
f.seek(0)
content = f.read()
print(f"文件追加后的内容:\n{content}")
更多 Python3 知识,请继续学习后续章节。

 川公网安备51010802032098
川公网安备51010802032098