Redis Stream(流)是 Redis 5.0 版本引入的一个新的数据类型。
Redis Stream 以更抽象的方式模拟日志数据结构,但日志仍然是完整的,它就像一个仅附加模式打开的日志文件。至少从概念上来讲,Redis 流是一种在内存中表示的抽象数据类型,他们实现了更加强大的操作,以此来克服日志文件本身的限制。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身就有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说,Redis 的发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息,会导致消息丢失。然而,Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Stream 是 Redis 的数据类型中最复杂的,尽管数据类型本身非常简单,但它实现了额外的非强制性的特性:提供了一组允许消费者以阻塞的方式等待生产者向 Stream 中发送的新消息,此外还有一个名为消费者组的概念。
注意:消费者组最早是由 Kafka 消息系统引入的,Redis 用完全不同的术语重新实现了一个相似的概念,但目标是相同的:允许一组客户端相互配合来消费同一个 Stream 的不同部分的消息。
Redis 为每个流条目生成一个唯一的 ID。您可以使用这些 ID 检索它们的关联条目,或者读取和处理流中的所有后续条目。同时,Redis 流还支持多种修剪策略(以防止流无限制地增长)和不止一种消费策略(请参阅 XREAD、XREADGROUP 和 XRANGE 命令)。
Streams 优点
Strean 除了拥有很高的性能和内存利用率外, 它最大的特点就是提供了消息的持久化存储,以及主从复制功能,从而解决了网络断开、Redis 宕机情况下,消息丢失的问题,即便是重启 Redis,存储的内容也会存在。
redis广告位
Streams 流程
Stream 消息队列主要由四部分组成,分别是:消息本身、生产者、消费者和消费组,对于前述三者很好理解,下面将介绍什么是消费组。
一个 Stream 队列可以拥有多个消费组,每个消费组中又包含了多个消费者,组内消费者之间存在竞争关系。当某个消费者消费了一条消息时,同组消费者,都不会再次消费这条消息。被消费的消息 ID 会被放入等待处理的 Pending_ids 中。每消费完一条信息,消费组的游标就会向前移动一位,组内消费者就继续去争抢下个消息。
Redis Stream 消息队列结构程如下图所示:
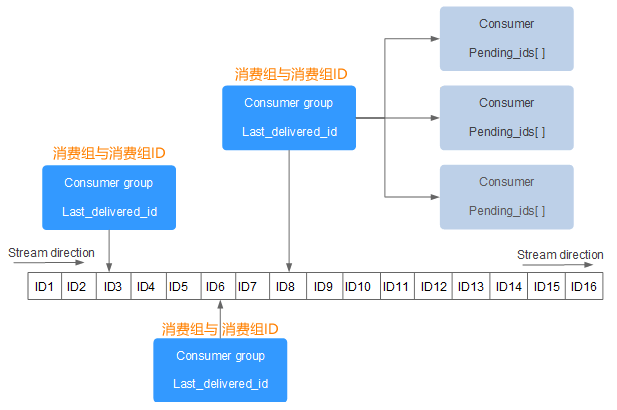
其中:
Stream direction: 表示数据流,它是一个消息链,将所有的消息都串起来,每个消息都有一个唯一标识 ID 和对应的消息内容(Message content)。
Consumer Group: 表示消费组,拥有唯一的组名,使用 XGROUP CREATE 命令创建。一个 Stream 消息链上可以有多个消费组,一个消费组内拥有多个消费者,每一个消费者也有一个唯一的 ID 标识。
last_delivered_id: 表示消费组游标,每个消费组都会有一个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
pending_ids: Redis 官方称为 PEL,表示消费者的状态变量,它记录了当前已经被客户端读取的消息 ID,但是这些消息没有被 ACK(确认字符)。如果客户端没有 ACK,那么这个变量中的消息 ID 会越来越多,一旦被某个消息被 ACK,它就开始减少。
Streams 应用场景
Redis Streams 应用场景如下:
实例
(1)将多个温度数据添加到流中,如下:
127.0.0.1:6379> XADD temperatures:us-ny:10007 * temp_f 87.2 pressure 29.69 humidity 46
"1676439104060-0"
127.0.0.1:6379> XADD temperatures:us-ny:10007 * temp_f 83.1 pressure 29.21 humidity 46.5
"1676439112614-0"
127.0.0.1:6379> XADD temperatures:us-ny:10007 * temp_f 81.9 pressure 28.37 humidity 43.7
"1676439120079-0"
(2)读取 ID 从 1676439112614-0 开始的前两个流条目,如下:
127.0.0.1:6379> XRANGE temperatures:us-ny:10007 1676439112614-0 + COUNT 2
1) 1) "1676439112614-0"
2) 1) "temp_f"
2) "83.1"
3) "pressure"
4) "29.21"
5) "humidity"
6) "46.5"
2) 1) "1676439120079-0"
2) 1) "temp_f"
2) "81.9"
3) "pressure"
4) "28.37"
5) "humidity"
6) "43.7"
(3)从流末尾开始读取最多 100 个新流条目,如果没有写入条目,则最多阻止 300 毫秒。如下:
127.0.0.1:6379> XREAD COUNT 100 BLOCK 300 STREAMS temperatures:us-ny:10007 $
(nil)
Redis Streams 命令
下面列出了 Redis Streams 的基本命令。
XADD命令
将指定的流条目添加到指定键的流中。如果键不存在,键将以流值创建。可以用 NOMKSTREAM 选项禁用流的键的创建。
一个条目是由 “字段-值” 对的列表组成的。“字段-值” 对的存储顺序与用户给出的顺序相同。读取数据流的命令,如 XRANGE 或 XREAD,保证完全按照 XADD 添加的顺序返回字段和值。
注意:XADD 命令是唯一能够向流中添加数据的 Redis 命令,但还有其他命令,如 XDEL 和 XTRIM 能够从流中删除数据。
语法如下:
XADD key [NOMKSTREAM] [<MAXLEN | MINID> [= | ~] threshold
[LIMIT count]] <* | id> field value [field value ...]
其中:
NOMKSTREAM 当添加流时,流不存在,该选项用来禁用流的键的创建
MAXLEN 只要流的长度超过指定的阈值,就驱逐条目,其中阈值是一个正整数。
MINID 驱逐条目ID 低于阈值的条目,其中阈值是一个流条目ID。
[= | ~] 指定裁剪的精度,= 表示精确裁剪,~ 表示近乎精确裁剪
threshold 一个阈值,如果用于 MAXLEN 表示流最大条目数量,如果用于 MINID 表示一个条目ID
<* | id> 用来定义流条目ID,*号表示自动生成条目ID,id表示一个具体的条目ID
field value 用来指定字段和值,它们是成对出现
实例:
# 向流 mystream 中添加一个 id 为 1526919030474-55 的条目
127.0.0.1:6379> XADD mystream 1526919030474-55 message "Hello,"
"1526919030474-55"
# 向流 mystream 中添加一个条目,id 自动生成
127.0.0.1:6379> XADD mystream * message " World!"
"1679028370556-0"
# 如果 mystream2 流不存在,则不会自动帮我们创建该流
127.0.0.1:6379> XADD mystream2 nomkstream 1526919030474-* message "Hello"
(nil)
指定流ID作为参数
流条目 ID 用来标识流中的指定条目。如果指定的 ID 参数是 * 字符(ASCII 字符星号),XADD 命令将为你自动生成一个唯一的 ID。然而,虽然只在非常罕见的情况下有用,但也可以指定一个格式良好的 ID,这样新条目就会以指定的 ID 准确地被添加。ID 是由两个数字构成,中间用 “-” 符号分隔,例如:
1526919030474-55
注意,ID 的两个数字都是 64 位的。当流条目 ID 是自动生成的,第一部分是生成 ID 的 Redis 实例的 Unix 时间,以毫秒计。第二部分只是一个序列号,用于区分在同一毫秒内生成的ID。
你也可以指定一个不完整的流条目 ID,它只由毫秒部分组成(即第一部分),序列部分的值为星号(*)。例如:
127.0.0.1:6379> XADD mystream 1526919030474-* message " World!"
"1526919030474-0"
127.0.0.1:6379> XADD mystream 1526919030474-* message " World!"
"1526919030474-1"
127.0.0.1:6379> XADD mystream 1526919030474-* message " World!"
"1526919030474-2"
上面执行了三条语句,它们的序号部分是递增的,时间部分是固定的 1526919030474。
注意,流条目 ID 被保证总是递增的。如果你比较刚刚插入的条目的 ID,它将大于任何其他过去的 ID,所以条目在流内是完全有序的。为了保证这个属性,如果流中当前的顶级 ID 的时间大于实例当前的本地时间,那么将使用顶级条目的时间来代替,并且 ID 的序列部分将被递增。这种情况可能会发生,例如本地时钟向后跳动,或者在故障切换后,新的主站有一个不同的绝对时间。
当用户向 XADD 指定一个明确的 ID 时,最小的有效 ID 是 0-1,而且用户必须指定一个大于当前流中任何其他 ID 的 ID,否则命令将失败并返回错误。通常情况下,只有当你有另一个系统产生唯一的 ID(例如一个 SQL 表),而你真的希望 Redis 流的 ID 与这个其他系统的 ID 相匹配时,指定明确 ID 才是有用的。
流封顶
XADD 包含了与 XTRIM 命令相同的语义。这允许添加新条目并通过对 XADD 命令的单次调用来检查流的大小,从而有效地用任意阈值(Threshold)限制流。虽然精确裁剪是可能的,而且是默认的,但考虑到流的内部表示,使用几乎精确裁剪(~参数)来添加一个条目并使用 XADD 来裁剪流会更高效。
例如,用以下形式调用 XADD:
# 裁剪前流的长度
127.0.0.1:6379> XLEN mystream
(integer) 5
# 添加一个条目到流,并且保证流的长度为2,将多的条目进行裁剪
# 这里使用的是精确裁剪(=)
127.0.0.1:6379> XADD mystream MAXLEN = 2 * message "val"
"1679287734275-0"
# 裁剪后流的长度
127.0.0.1:6379> XLEN mystream
(integer) 2
将添加一个新的条目,但也将驱逐旧的条目,这样,流将只包含1000个条目,或最多几十个。
注意:
(1)从 Redis 6.2.0 版本开始,增加了 NOMKSTREAM 选项、MINID 修剪策略和 LIMIT 选项
(2)从 Redis 7.0.0 版开始,增加了对 <ms>-* 明确 ID 形式的支持
XREAD命令
该命令用来从一个或多个数据流中读取数据,只返回 ID 大于调用者指定的条目 ID。该命令还有一个 BLOCK 选项,如果条目不可用,则直接阻塞,与 BRPOP 或 BZPOPMIN 和其他命令的方式类似。语法如下:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id
[id ...]
实例:
# 向流写入三个条目
127.0.0.1:6379> XADD mystream 1526919030474-* message "val1"
"1526919030474-0"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val2"
"1526919030474-1"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val3"
"1526919030474-2"
# 从流中获取两个条目,查找 ID 大于 0-0 的条目
127.0.0.1:6379> XREAD COUNT 2 mystream
(error) ERR syntax error
127.0.0.1:6379> XREAD COUNT 2 mystream 0-0
(error) ERR syntax error
127.0.0.1:6379> XREAD COUNT 2 STREAMS mystream 0-0
1) 1) "mystream"
2) 1) 1) "1526919030474-0"
2) 1) "message"
2) "val1"
2) 1) "1526919030474-1"
2) 1) "message"
2) "val2"
# 从流中获取 ID大于 1526919030474-2 的条目,如果没有,则阻塞 5 秒
127.0.0.1:6379> XREAD COUNT 2 BLOCK 5000 STREAMS mystream 1526919030474-2
(nil)
(5.01s)
注意:上面示例中 “0-0” 表示一个 ID 的时间戳部分和序号部分均为 0。
XRANGE命令
用来返回指定条目 ID 范围内的 count 个条目,语法如下:
XRANGE key start end [COUNT count]
实例:
# 向流中添加 5 个条目
127.0.0.1:6379> XADD mystream 1526919030474-* message "val1"
"1526919030474-3"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val2"
"1526919030474-4"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val3"
"1526919030474-5"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val4"
"1526919030474-6"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val5"
"1526919030474-7"
# 返回条目ID在 1526919030474-3 ~ 1526919030474-6 之间的两个条目
127.0.0.1:6379> XRANGE mystream 1526919030474-3 1526919030474-6 COUNT 2
1) 1) "1526919030474-3"
2) 1) "message"
2) "val1"
2) 1) "1526919030474-4"
2) 1) "message"
2) "val2"
XLEN命令
返回流的长度。语法如下:
XLEN key
实例:
# 向流中添加 5 个条目
127.0.0.1:6379> XADD mystream 1526919030474-* message "val1"
"1526919030474-3"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val2"
"1526919030474-4"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val3"
"1526919030474-5"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val4"
"1526919030474-6"
127.0.0.1:6379> XADD mystream 1526919030474-* message "val5"
"1526919030474-7"
# 获取 mystream 流中条目的个数
127.0.0.1:6379> XLEN mystream
(integer) 5
XTRIM命令
如果需要的话,XTRIM 通过驱逐老的条目(ID较低的条目)来修剪流。修剪流可以使用这些策略中的一种来完成:
语法如下:
XTRIM key <MAXLEN | MINID> [= | ~] threshold [LIMIT count]
实例:
(1)把数据流精确地修剪到最近的 10 个条目。
# 查看流大小
127.0.0.1:6379> xlen mystream
(integer) 18
# 修剪流
127.0.0.1:6379> XTRIM mystream MAXLEN 10
(integer) 8
# 查看流大小
127.0.0.1:6379> xlen mystream
(integer) 10
(2)将所有条目 ID 低于 1679031942359-0 的条目驱逐
# 向流中添加条目,注意查看ID
127.0.0.1:6379> XADD mystream * message "hello"
"1679031940170-0"
127.0.0.1:6379> XADD mystream * message "hello"
"1679031941187-0"
127.0.0.1:6379> XADD mystream * message "hello"
"1679031941868-0"
127.0.0.1:6379> XADD mystream * message "hello"
"1679031942359-0"
127.0.0.1:6379> XADD mystream * message "hello"
"1679031942845-0"
# 驱逐条目ID低于 1679031942359-0 的条目
127.0.0.1:6379> XTRIM mystream MINID 1679031942359
(integer) 13
# 查看流大小
127.0.0.1:6379> xlen mystream
(integer) 2
默认情况下,或者当提供可选的 = 参数时,该命令执行精确修剪。根据策略的不同,精确修剪意味着:
近乎精确的修剪
因为精确的修剪可能需要Redis服务器的额外努力,所以可以提供可选的~参数以使其更有效率。例如:
XTRIM mystream MAXLEN ~ 1000
MAXLEN策略和阈值之间的~参数意味着用户要求修剪数据流,使其长度至少达到阈值,但也可能略多。在这种情况下,当可以获得性能时,Redis将提前停止修剪(例如,当数据结构中的整个宏节点不能被移除时)。这使得修剪的效率大大提高,而且这通常是你想要的,尽管在修剪后,流可能有几十个额外的条目超过阈值。
在使用~时,控制命令所做工作量的另一种方法是LIMIT子句。当使用时,它指定了将被驱逐的条目的最大数量。当LIMIT和count没有被指定时,默认值100 * 宏节点中的条目数将被隐含地用作计数。指定数值0作为计数,可以完全禁用限制机制。
注意:从 Redis 版本 6.2.0 开始,增加了MINID微调策略和LIMIT选项。
XDEL
从流中删除指定的条目,并返回已删除的条目数。在流中不存在某些指定ID的情况下,此数字可能小于传递给命令的ID的数量。
Redis流以一种使其内存高效的方式表示:为了索引线性包装数十个流条目的宏节点,使用了基数树。通常情况下,当您从流中删除一个条目时,该条目并没有真正被删除,它只是被标记为已删除。通常情况下,当你从一个流中删除一个条目时,该条目不会被真正驱逐,它只是被标记为删除。
最终,如果一个宏节点中的所有条目都被标记为删除,整个节点就会被销毁,内存就会被回收。这意味着,如果你从一个流中删除了大量的条目,例如,超过50%的条目被附加到流中,每个条目的内存使用量可能会增加,因为所发生的是流将变得支离破碎。然而,流的性能将保持不变。
在未来的Redis版本中,我们可能会在某个宏节点达到一定数量的删除条目时触发节点垃圾回收。目前,就我们对这个数据结构的预期使用而言,增加这样的复杂性并不是一个好主意。
语法如下:
XDEL key id [id ...]
实例:
# 查看流中条目信息
127.0.0.1:6379> xread STREAMS mystream 0-0
1) 1) "mystream"
2) 1) 1) "1679375078038-2"
2) 1) "uuid"
2) "d79024c2-e60d-42c5-9beb-4da6c302d7fc"
2) 1) "1679375078039-0"
2) 1) "uuid"
2) "16c1caf4-6048-4add-8b79-a6ddbc10ec8b"
# 删除ID为 1679375078038-2 的条目
127.0.0.1:6379> xdel mystream 1679375078038-2
(integer) 1
# 验证删除结果
127.0.0.1:6379> xread STREAMS mystream 0-0
1) 1) "mystream"
2) 1) 1) "1679375078039-0"
2) 1) "uuid"
2) "16c1caf4-6048-4add-8b79-a6ddbc10ec8b"
XGROUP CREATE
用来为指定的流创建一个新的使用者组,在流中,每个组都有一个唯一的名字。当一个同名的消费组已经存在时,该命令会返回一个 BUSYGROUP 错误。
语法如下:
XGROUP CREATE key group <id | $> [MKSTREAM]
[ENTRIESREAD entries-read]
注意,该命令的 <id> 参数用于指定该组的消费者组的起始 ID,$ 表示用流中最后一个条目的 ID 当作消费者组的起始 ID,但你也可以用任何有效的 ID 代替它。例如,如果你想让该组的消费者从一开始就获取整个流,那么就用 0 作为消费者组的起始 ID。
XGROUP CREATE mystream mygroup 0
默认情况下,XGROUP CREATE 命令要求目标流存在,如果流不存在则返回错误。如果流不存在,你可以通过使用可选的 MKSTREAM 子命令作为 <id> 后面的最后一个参数,自动创建它,流长度为 0。例如:
# 下面组的消费者组起始ID为流最后一个条目ID
XGROUP CREATE mystream mygroup $ MKSTREAM
要启用消费者组的滞后跟踪,请用一个任意的ID指定可选的 entries_read命名参数。一个任意的ID是指任何不是流的第一个条目、最后一个条目或零("0-0")ID的ID。用它来找出任意ID(不包括它)和流的最后一个条目之间有多少条目。将 entries_read 设为流的 entries_added 减去 entry 的数量。
实例:
# 如果创建消费组的流 key 不存在,报错
127.0.0.1:6379> xgroup create mystream mygroup $
(error) ERR The XGROUP subcommand requires the key to exist. Note that for CREATE you may want to use the MKSTREAM option to create an empty stream automatically.
# 流 key 存在,获取流长度
127.0.0.1:6379> xlen mystream
(integer) 1
127.0.0.1:6379> xgroup create mystream mygroup $
OK
# 向流中添加几个条目,手动设置消费组的起始ID
127.0.0.1:6379> xgroup create mystream mygroup $
OK
127.0.0.1:6379> xadd mystream * message value1
"1679462734998-0"
127.0.0.1:6379> xadd mystream * message value2
"1679462736773-0"
127.0.0.1:6379> xadd mystream * message value3
"1679462738683-0"
127.0.0.1:6379> xgroup create mystream mygroup2 1679462736773-0
OK
# 如果消费组名称已经存在,则报 BUSYGROUP 错误
127.0.0.1:6379> xgroup create mystream mygroup 1679462736773-0
(error) BUSYGROUP Consumer Group name already exists
XGROUP DESTROY
该命令会完全销毁一个消费者组。即使消费组有活跃的消费者和待处理的消息,消费者组也会被销毁,所以要确保只有在真正需要的时候才调用这个命令。用法如下:
XGROUP DESTROY key group
实例:
127.0.0.1:6379> xgroup destroy mystream mygroup2
(integer) 1
XGROUP CREATECONSUMER
该命令用来为指定流中的指定消费组上创建一个消费者。
注意:每当一个操作,比如 XREADGROUP,引用一个不存在的消费者,消费者也会被自动创建。这只在流中有数据时对 XREADGROUP 有效。
语法如下:
XGROUP CREATECONSUMER key group consumer
实例:
# 在 mystream 流的 mygroup 消费组上面创建名为 myconsumer 的消费者
127.0.0.1:6379> xgroup createconsumer mystream mygroup myconsumer
(integer) 1
XGROUP DELCONSUMER
该命令从消费者组中删除了一个消费者。有时删除旧的消费者可能是有用的,因为它们不再被使用了。
然而,消费者的任何未确认消息在它被删除后将变得不可索取。因此,强烈建议在从组中删除消费者之前,对任何待处理的消息进行认领或确认。
注意:该命令返回值为消费者在被删除之前的待处理信息的数量。
语法如下:
XGROUP DELCONSUMER key group consumer
实例:
# 创建一个消费则
127.0.0.1:6379> xgroup createconsumer mystream mygroup myconsumer
(integer) 1
# 删除刚刚创建的消费者,消费者待消费的消息为0
127.0.0.1:6379> xgroup delconsumer mystream mygroup myconsumer
(integer) 0
XREADGROUP
XREADGROUP 命令是 XREAD 命令的一个特殊版本,支持消费者组。
XREADGROUP 命令与普通的 XREAD 的区别在于,该命令支持消费者组。
如果没有消费者组,只使用 XREAD,则所有客户端都将使用流中的所有条目进行服务。与使用 XREADGROUP 的消费者组不同,可以创建客户端组,这些客户端组使用到达给定流的消息的不同部分。例如,如果流获得新条目 A、B 和 C,并且有两个消费者通过消费者组读取数据,那么一个客户端将获得消息 A 和 C,另一个客户端将获得消息B。
在一个消费者组中,一个给定的消费者(也就是说,只是一个从流中消费消息的客户端),必须用一个唯一的消费者名称来识别(消费者名称是一个字符串)。
消费者组的重要保证之一是,一个给定的消费者只能看到传递给它的消息历史,所以一个消息只有一个所有者。然而,有一个特殊的功能叫做消息索取,它允许其他消费者在某些消费者发生不可恢复的故障时索取消息。为了实现这种语义,消费者组需要通过 XACK 命令对消费者成功处理的消息进行明确的确认。这是有必要的,因为流将跟踪每个消费者组,谁在处理什么消息。
下面是如何确认你是否需要使用一个消费者组:
(1)如果你有一个流和多个客户端,并且你希望所有的客户端都能得到所有的消息,则你不需要一个消费者组。
(2)如果你有一个流和多个客户端,并且你想在你的客户端之间对流进行分区或分片,这样每个客户端将得到一个流中到达的消息的子集,此时你需要一个消费者组。
XREAD 和 XREADGROUP 的区别
从语法的角度来看,这些命令几乎是相同的,但是 XREADGROUP 需要一个特殊的、强制性的选项:
GROUP <group-name> <consumer-name>
group-name 是与当前流相关的消费者组的名称。该组是用 XGROUP 命令创建的。consumer-name 是客户端用来在组内识别自己的字符串。消费者第一次被使用时,会在消费者组内自动创建。不同的客户应该选择一个不同的消费者名称。
当你用 XREADGROUP 读取消息时,服务器将记住某条消息已经交付给你了。该消息将被储存在消费者组内所谓的 PEL(Pending Entries List)中,这是一个已交付但尚未被客户端确认的信息 ID 的列表。
客户端必须使用 XACK 确认消息的处理,以便从 PEL 中删除待确认消息。PEL 可以使用 XPENDING 命令进行检查。
NOACK 子命令可以用来避免将消息添加到 PEL 中,在这种情况下,可靠性不是一个重要的需求,偶尔的消息丢失是可以接受的。这相当于在读取信息时就自动确认它了。
使用 XREADGROUP 时,在 STREAMS 选项中指定的 ID 可以是以下两种之一:
(1)特殊的 ID “>”,这意味着消费者只想收到从未传递给其他消费者的消息。它意味着,给我新的消息。
(2)任何其他的ID,即 0 或任何其他有效的 ID 或不完整的 ID(只是毫秒级的时间部分,即有 “-” 符号的左边,没有右边,如:"1679462734998-"),都会向消费者返回 ID 大于所提供的 ID 的待确定消息。因此,基本上如果 ID 不是 “>”,那么该命令将只允许客户端访问其待确认的消息:返回给它但尚未确认的消息。注意,在这种情况下,BLOCK 和 NOACK 都会被忽略。
和 XREAD 一样,XREADGROUP 命令也可以以阻塞的方式使用,在这方面他们之间没有区别。
当信息被传递给消费者时会发生什么?它会做两件事:
(1)如果该消息从未被交付给任何人,也就是说,如果我们谈论的是一个新的消息,那么就会创建一个PEL(待定条目列表)。
(2)如果相反,该消息已经交付给了这个消费者,而且它只是再次重新获取相同的消息,那么最后一次交付的计数器就会被更新到当前时间,而且交付的数量会增加1。你可以使用 XPENDING 命令访问这些消息属性。
语法如下:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds]
[NOACK] STREAMS key [key ...] id [id ...]
实例:
# 从消费者组中消费消息,一次最多消费10个消息,如果没有消息则阻塞 999999999 毫秒
# 流中已经存在消息
127.0.0.1:6379> xreadgroup group mygroup myconsumer count 10 block 999999999 streams mystream >
1) 1) "mystream"
2) 1) 1) "1679550857275-0"
2) 1) "message"
2) "value3"
2) 1) "1679550859430-0"
2) 1) "message"
2) "value4"
# 从消费者组中消费消息,一次最多消费10个消息,如果没有消息则阻塞 999999999 毫秒
# 另一个客户端将消息添加到 mystream 流中
127.0.0.1:6379> xreadgroup group mygroup myconsumer count 10 block 999999999 streams mystream >
1) 1) "mystream"
2) 1) 1) "1679550873312-0"
2) 1) "message"
2) "value5"
(6.46s)
XINFO CONSUMERS
用来查看指定流中指定分组的消费者信息,语法如下:
XINFO CONSUMERS key group
该命令为该组中的每个消费者提供以下信息:
name:消费者的名称
pending:PEL中的条目数,消费者的待定消息,即已经交付但尚未确认的消息
idle:消费者最后一次尝试互动后的毫秒数(例如:XREADGROUP、XCLAIM、XAUTOCLAIM)。
inactive:从消费者最后一次成功的互动以来已经过去的毫秒数(例如: XREADGROUP 实际读取了一些条目到 PEL,XCLAIM/XAUTOCLAIM 实际索取了一些条目)
实例:
# 获取 mystream 流中 mygroup 消费者组中的消费者信息
127.0.0.1:6379> xinfo consumers mystream mygroup
1) 1) "name"
2) "myconsumer"
3) "pending"
4) (integer) 0
5) "idle"
6) (integer) 312485
7) "inactive"
8) (integer) -1
XINFO GROUPS
该命令用来获取指定流下面的消费者组信息,语法如下:
XINFO GROUPS key
该命令默认情况下,只为每个组提供以下信息:
name:消费者组的名称
consumers:该组中消费者的数量
pending:该组的待处理条目列表(PEL)的长度,这是已经交付但尚未确认的消息
last-delivered-id:该组消费者的最后一个条目的ID。
entries-read:最后一个被传递给群组消费者的条目的逻辑 "读取计数器"。
lag:流中仍在等待交付给组的消费者的条目数,如果不能确定这个数字,则为NULL。
实例:
# 获取 mystream 流中的消费者组信息
127.0.0.1:6379> xinfo groups mystream
1) 1) "name"
2) "mygroup"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "1679548746484-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 1
XINFO STREAM
该命令用来获取指定流的信息,语法如下:
XINFO STREAM key [FULL [COUNT count]]
该命令提供的信息细节有:
length:流中的条目数(见XLEN)。
radix-treekeys:底层radix数据结构中键的数量
radix-tree-nodes:底层radix数据结构中的节点数
groups: 为流定义的消费者组的数量
last-generated-id:被添加到流中的最近的条目的ID。
max-deleted-entry-id:从流中删除的最大条目ID。
entries-added:在流的生命周期中加入到流中的所有条目的数量。
first-entry:流中第一个条目的ID和字段值
last-entry:流中最后一个条目的ID和字段值
实例:
# 获取 mystream 流的信息
127.0.0.1:6379> xinfo stream mystream
1) "length"
2) (integer) 2
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1679548915083-0"
9) "max-deleted-entry-id"
10) "0-0"
11) "entries-added"
12) (integer) 2
13) "recorded-first-entry-id"
14) "1679548746484-0"
15) "groups"
16) (integer) 1
17) "first-entry"
18) 1) "1679548746484-0"
2) 1) "message"
2) "value1"
19) "last-entry"
20) 1) "1679548915083-0"
2) 1) "message"
2) "value2"
更多命令请访问 https://redis.io/commands 进行参考。

 川公网安备51010802032098
川公网安备51010802032098