在 AI 大模型(如 ChatGPT、Claude、文心一言等)的交互中,聊天记忆(Chat Memory)指模型对当前对话历史的“感知”和“调用”能力,是实现连续、上下文连贯对话的核心机制。它让模型能够像人类聊天一样,记住之前说过的话,从而理解当前提问的背景、延续话题逻辑,而不是每次对话都像“重新开始”。
大语言模型(LLM)本质上是无状态的,这意味着它们不会保留历史交互信息。例如,调用 kimi 大模型进行简单聊天,分别问“四川大学是 211 吗?”和“是 985 吗?”
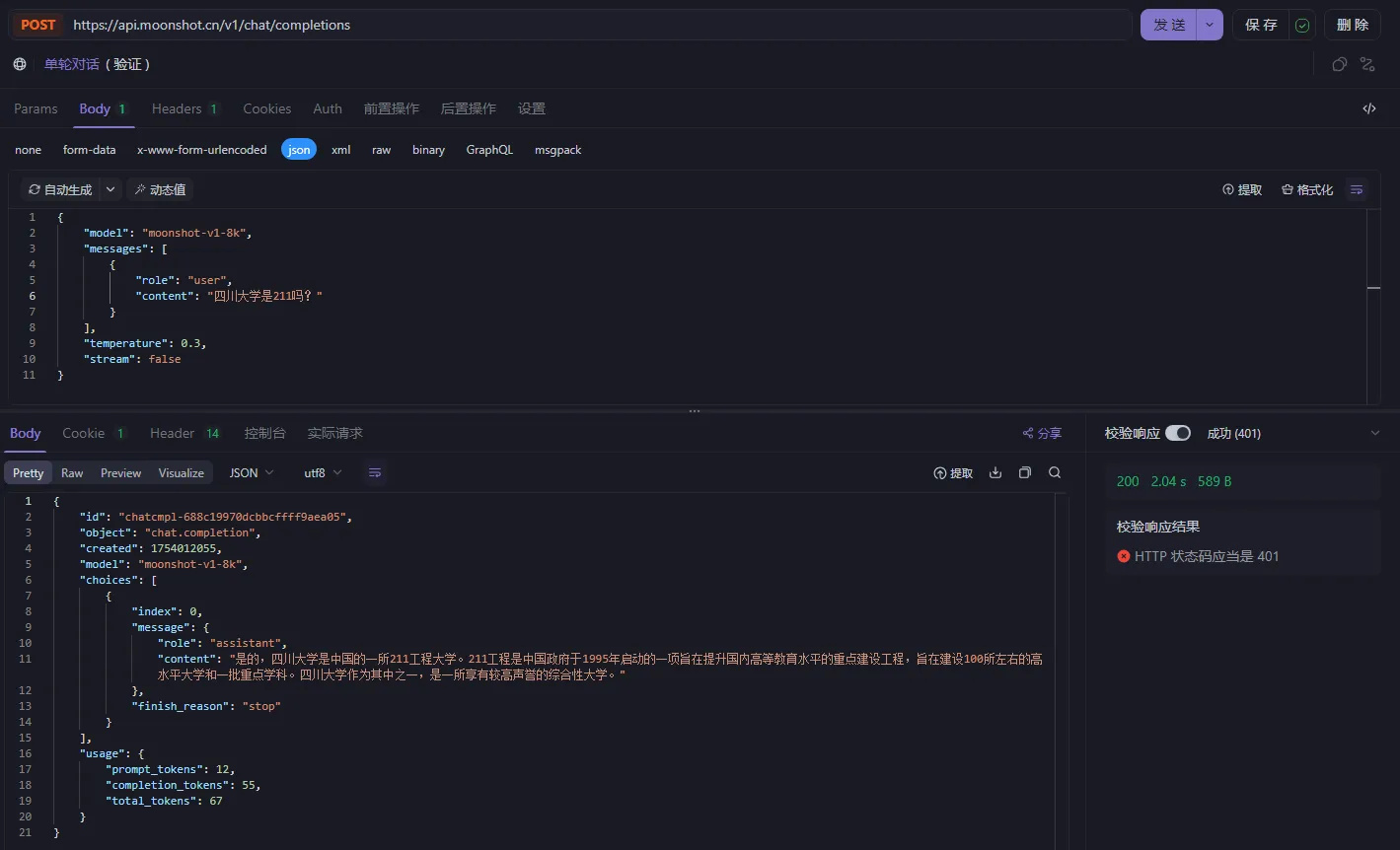
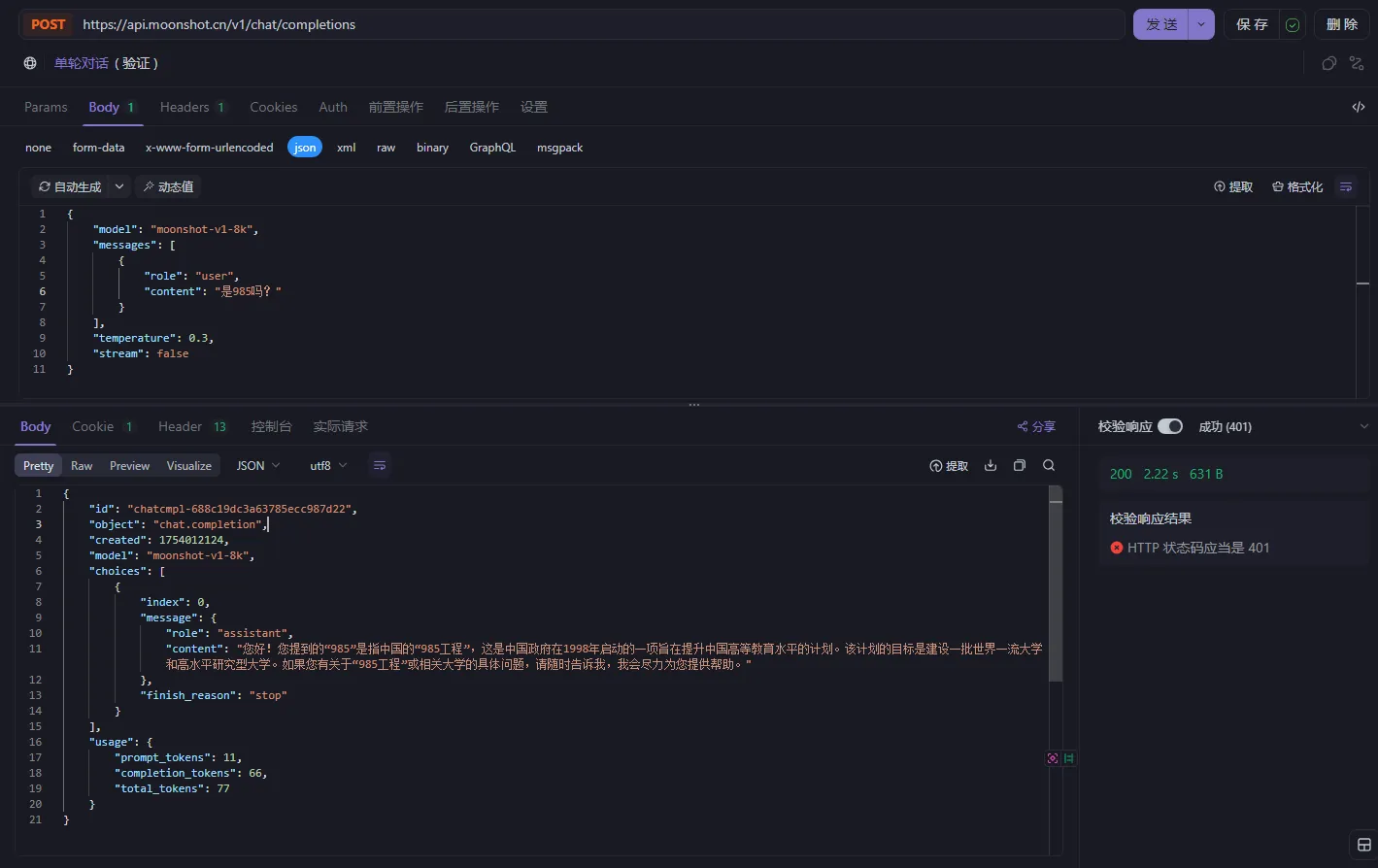
从两次输出可知,第二次请求,kimi 是不知道你问的是“四川大学”是不是 985,这就说明 kimi 是没有记忆功能的。那我们如何让他有记忆呢?可以通过将历史消息放在 messages 数组中,如下:
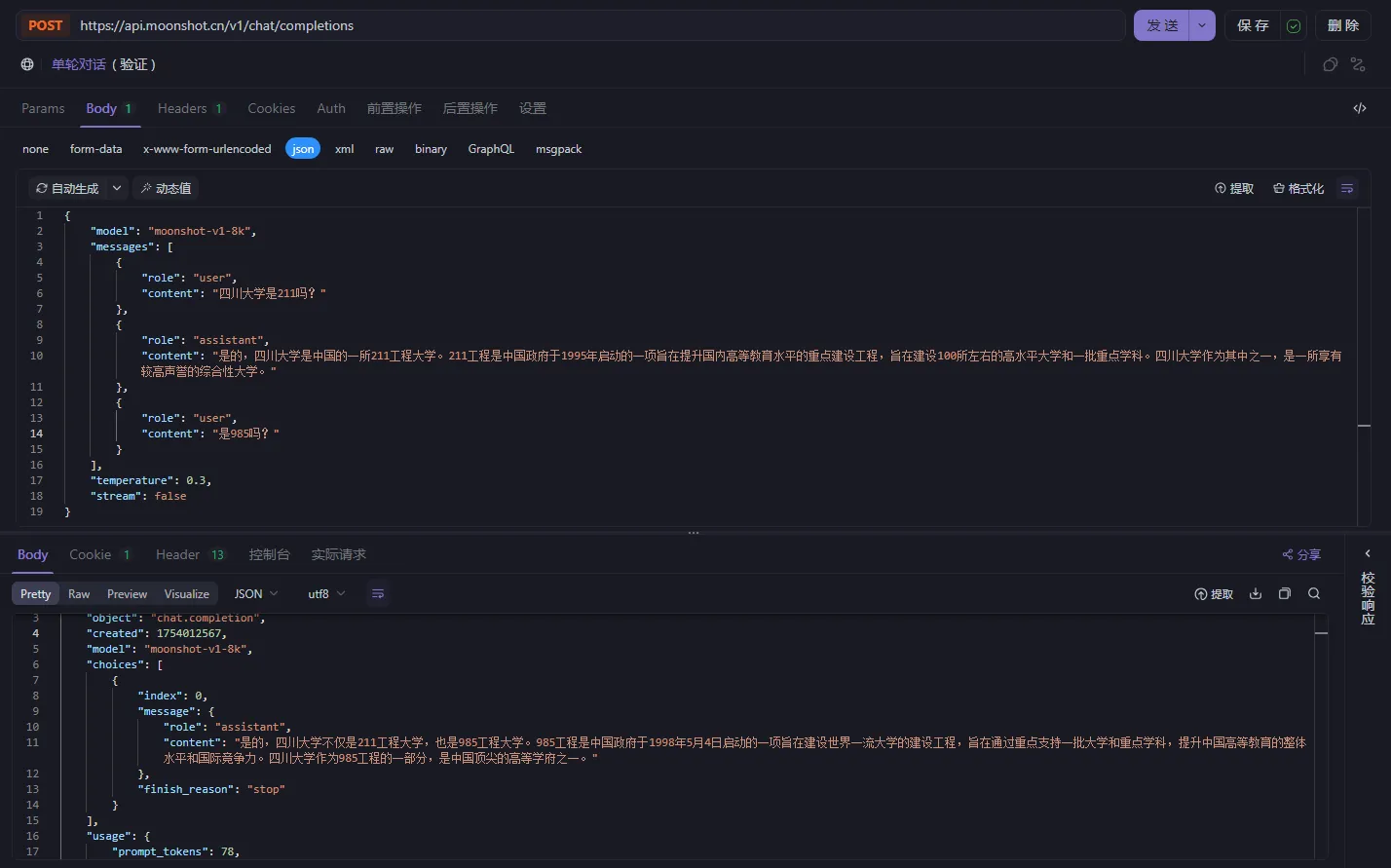
上图可知,kimi 知道你在问“四川大学是 985 吗?”。因此,需要我们自己去保存聊天记录,同时在聊天的时候自己将历史信息带入到对话上下文,实现记忆功能。
值得庆幸的是,Spring AI 已经帮我们提供了聊天记忆功能,支持在 LLM 交互过程中存储和检索上下文数据,不需要自己去实现。
Spring AI 中,ChatMemory 抽象层支持实现多种记忆类型以满足不同场景需求。消息的底层存储由 ChatMemoryRepository 处理,其唯一职责是存储和检索消息。ChatMemory 接口实现类可自主决定消息保留策略 —— 例如保留最近 N 条消息、按时间周期保留或基于 Token 总量限制保留。
聊天记忆 & 聊天历史
简言之,聊天历史是 “原材料”,聊天记忆是 “加工品”:历史提供了全部信息基础,而记忆则是对这些信息的有效利用,决定了互动的连贯性和针对性。
在聊天场景中,“聊天记忆” 和 “聊天历史” 是两个相关但不同的概念,它们在定义、特性、作用等方面存在明显区别。
聊天历史(Chat History)
聊天历史是客观存在的、可追溯的聊天记录集合,指的是用户与对方(包括人与人、人与 AI、人与系统等)在聊天过程中产生的所有文字、语音、图片、文件等内容的原始存档。
拥有如下特点:
客观性:完全忠实于原始对话内容,不经过加工或解读,是对话过程的“原始数据”,如微信聊天记录。
可存储性:通常以文本、数据库条目、日志文件等形式被系统(如社交软件、聊天工具)保存,用户可手动查阅(如翻聊天记录)。
完整性:理论上包含从对话开始到当前的所有内容(除非被删除或清理),按时间顺序排列。
被动性:本身不具备“理解”或“关联”能力,仅作为历史数据存在,需用户主动检索才能发挥作用。
聊天记忆(Chat Memory)
聊天记忆是对聊天历史的主观加工、提取和留存,指的是参与者(人或 AI)对聊天内容的选择性记忆、理解和关联,是对历史信息的“主动处理结果”。
拥有如下特点:
主观性:会根据参与者的注意力、需求或算法逻辑进行筛选,可能忽略无关信息,突出关键内容(如核心需求、约定事项、情感倾向等)。
加工性:不仅包含原始信息,还可能融入理解(如“对方提到下周需要一份报告” 是对 “下周三之前给我那个文件”的加工)、关联(如将本次提到的“产品 A”与上次的“产品 A 反馈”结合)。
动态性:会随新的聊天内容更新(如补充“对方将报告时间延后到周五”),也可能因遗忘或算法调整而变化。
主动性:能直接影响后续互动(如人会根据记忆中的“对方讨厌某话题”避开讨论;AI 会根据记忆的 “用户需求” 提供针对性回复)。
ChatMemory 抽象层专为管理聊天记忆设计,支持存储和检索当前会话相关的上下文消息。但若需完整记录所有历史消息,建议采用其他方案(如基于 Spring Data 实现高效的全量聊天历史存储与检索)。
spring 广告位
快速入门
Spring AI 自动配置了 ChatMemory Bean 供我们直接使用。默认采用内存存储(InMemoryChatMemoryRepository)及 MessageWindowChatMemory 实现管理会话历史。若已配置其他 Repository(如 Cassandra/JDBC/Neo4j),则自动切换至对应实现。
例如,下面使用 MySQL 数据库存储会话历史,详细步骤如下:
(1)添加 Maven 依赖
<!-- 会话记忆 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-chat-memory</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-chat-memory-repository-jdbc</artifactId>
<version>1.0.0</version>
</dependency>
<!-- Spring Data JDBC -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<!-- mysql 驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
(2)创建数据库 chat_db,以及 SPRING_AI_CHAT_MEMORY 数据表,存放聊天历史,如下:
-- chat_db.SPRING_AI_CHAT_MEMORY definition
CREATE TABLE `SPRING_AI_CHAT_MEMORY` (
`conversation_id` varchar(36) NOT NULL,
`content` text NOT NULL,
`type` varchar(10) NOT NULL,
`timestamp` timestamp NOT NULL,
KEY `SPRING_AI_CHAT_MEMORY_timestamp_IDX` (`timestamp`) USING BTREE,
CONSTRAINT `TYPE_CHECK` CHECK ((`type` in (_utf8mb4'USER',_utf8mb4'ASSISTANT',_utf8mb4'SYSTEM',_utf8mb4'TOOL')))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
(3)创建一个 Controller,注入 ChatModel 和 ChatMemory,构造一个简单的 AI 聊天接口 /ai,如下:
package com.hxstrive.springai.springai_openai.chatMemory1.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@RestController
class MyController {
@Autowired
private ChatModel chatModel;
@Autowired
private ChatMemory chatMemory;
// http://localhost:8080/ai?message=
@GetMapping(value = "/ai",produces = "text/html; charset=UTF-8")
public String ai(@RequestParam("message") String message) {
// 手动构造 ChatClient,设置默认的系统提示词,日志输出 Advisor
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("你是AI助手小粒,所有回复均使用中文。")
.defaultAdvisors(
new SimpleLoggerAdvisor() // 输出聊天日志
)
.build();
// 唯一会话ID,同一个会话上下文中保持一致
String sessionId = "USER-250801100723";
// 1. 将用户输入添加到记忆
UserMessage userMessage = new UserMessage(message);
chatMemory.add(sessionId, userMessage);
// 2. 获取记忆中的所有消息(上下文),传递给 AI 模型
ChatClient.CallResponseSpec responseSpec = chatClient.prompt().messages(chatMemory.get(sessionId)).call();
// 3. 将 AI 回复添加到记忆,更新上下文
AssistantMessage assistantMessage = responseSpec.chatResponse().getResult().getOutput();
chatMemory.add(sessionId, assistantMessage);
// 4. 返回 AI 回复内容
return assistantMessage.getText();
}
}
启动应用,浏览器访问 http://localhost:8080/ai?message= 地址,分别提问“四川大学是 211 吗?”和“是 985 吗?”,响应信息如下图:

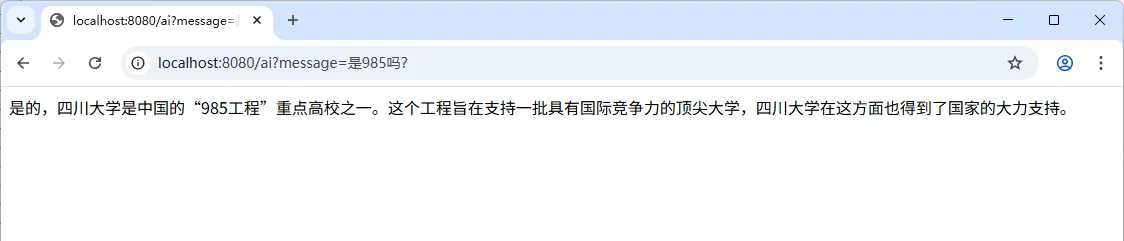
从上图响应可知,存在聊天记忆功能,第二次提问“是 985 吗?”,AI 是知道你是在问“四川大学”。
完成后,查询数据库,插入了四条日志信息,如下图:

为了进一步明确,我们将查看最后一次提问(及“是 985 吗?”)的日志:
2025-08-01T21:30:13.725+08:00 DEBUG 25260 --- [springai_demo1] [nio-8080-exec-9] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[
prompt=Prompt{
messages=[
SystemMessage{textContent='你是AI助手小粒,所有回复均使用中文。', messageType=SYSTEM, metadata={messageType=SYSTEM}},
UserMessage{content='四川大学是211吗?', properties={messageType=USER}, messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[], textContent=是的,四川大学是中国的“211工程”重点支持的高校之一。这个项目旨在提升中国部分重点大学的教育和研究水平。, metadata={messageType=ASSISTANT}],
UserMessage{content='是985吗?', properties={messageType=USER}, messageType=USER}
],
modelOptions=OpenAiChatOptions: {"streamUsage":false,"model":"gpt-3.5-turbo","temperature":0.7}}, context={}]
2025-08-01T21:30:15.990+08:00 DEBUG 25260 --- [springai_demo1] [nio-8080-exec-9] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"finishReason" : "STOP",
"refusal" : "",
"index" : 0,
"annotations" : [ ],
"id" : "chatcmpl-CIhC35prs76VP5EsFHroyb73UkvJ2"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "是的,四川大学是中国的“985工程”重点高校之一。这个工程旨在支持一批具有国际竞争力的顶尖大学,四川大学在这方面也得到了国家的大力支持。"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
},
"metadata" : {
"id" : "chatcmpl-CIhC35prs76VP5EsFHroyb73UkvJ2",
"model" : "gpt-3.5-turbo-0613",
"rateLimit" : {
"requestsLimit" : null,
"requestsRemaining" : null,
"requestsReset" : null,
"tokensLimit" : null,
"tokensRemaining" : null,
"tokensReset" : null
},
"usage" : {
"promptTokens" : 110,
"completionTokens" : 75,
"totalTokens" : 185,
"nativeUsage" : {
"completion_tokens" : 75,
"prompt_tokens" : 110,
"total_tokens" : 185
}
},
"promptMetadata" : [ ],
"empty" : false
},
"results" : [ {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"finishReason" : "STOP",
"refusal" : "",
"index" : 0,
"annotations" : [ ],
"id" : "chatcmpl-CIhC35prs76VP5EsFHroyb73UkvJ2"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "是的,四川大学是中国的“985工程”重点高校之一。这个工程旨在支持一批具有国际竞争力的顶尖大学,四川大学在这方面也得到了国家的大力支持。"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
} ]
}
到这里,我们利用内置的 ChatMemory 实现了简单的聊天记忆功能。接下来的章节将详细介绍 Spring AI 中可用的不同记忆类型与记忆存储 Repository 实现。
spring 广告位
核心接口
ChatMemory 接口
接口是对话记忆管理的核心抽象,定义了管理对话上下文的标准行为,为多轮对话提供了统一的记忆操作规范。它屏蔽了底层存储细节(如内存、Redis、数据库等),让开发者可以灵活替换记忆实现而不影响上层业务逻辑。
ChatMemory 接口位于 org.springframework.ai.chat.memory 包下,主要定义了对对话消息的添加、获取、清理等操作,源码如下:
package org.springframework.ai.chat.memory;
import java.util.List;
import org.springframework.ai.chat.messages.Message;
import org.springframework.util.Assert;
/**
* 聊天记忆接口,用于管理多轮对话中的上下文消息,支持多会话隔离。
* 主要功能包括添加消息、获取消息、清空消息,确保AI模型能基于历史对话生成连贯回复。
*/
public interface ChatMemory {
/**
* 默认会话ID,当未指定会话标识时使用,适用于单会话场景
*/
String DEFAULT_CONVERSATION_ID = "default";
/**
* 会话ID在相关上下文中的属性键名,用于从环境中获取或设置会话标识
*/
String CONVERSATION_ID = "chat_memory_conversation_id";
/**
* 向指定会话的记忆中添加单条消息(默认实现)
* 该方法通过断言确保会话ID和消息的有效性,最终调用批量添加方法
*
* @param conversationId 会话唯一标识,用于区分不同对话上下文
* @param message 要添加的消息对象(可是用户消息、AI回复或系统消息等)
*/
default void add(String conversationId, Message message) {
// 断言会话ID不为空或空白,否则抛出异常
Assert.hasText(conversationId, "conversationId cannot be null or empty");
// 断言消息不为空,否则抛出异常
Assert.notNull(message, "message cannot be null");
// 调用批量添加方法,将单条消息包装为列表
this.add(conversationId, List.of(message));
}
/**
* 向指定会话的记忆中批量添加消息(核心方法,需实现类提供具体逻辑)
* 用于一次性添加多条消息,适用于初始化会话或批量导入历史记录
*
* @param conversationId 会话唯一标识
* @param messages 要添加的消息列表
*/
void add(String conversationId, List<Message> messages);
/**
* 获取指定会话的所有记忆消息(核心方法,需实现类提供具体逻辑)
* 返回的消息列表将作为上下文传递给AI模型,影响回复的连贯性
*
* @param conversationId 会话唯一标识
* @return 按时间顺序排列的消息列表,包含该会话的所有历史消息
*/
List<Message> get(String conversationId);
/**
* 清空指定会话的所有记忆消息(核心方法,需实现类提供具体逻辑)
* 适用于重置对话上下文(如用户切换话题、结束当前会话)
*
* @param conversationId 会话唯一标识
*/
void clear(String conversationId);
}
ChatMemoryRepository 接口
ChatMemoryRepository 接口是对话记忆持久化的核心抽象,主要负责对话记忆(通常包含完整的会话上下文消息)的存储、查询、更新和删除操作,为 ChatMemory 提供底层数据持久化支持。它解决了对话记忆在不同存储介质(如内存、数据库、缓存等)中的统一操作问题,是连接业务逻辑与底层存储的桥梁。
ChatMemoryRepository 通常位于 org.springframework.ai.chat.memory 或相关子包下,其核心方法围绕对话记忆的生命周期管理设计,源码如下:
package org.springframework.ai.chat.memory;
import java.util.List;
import org.springframework.ai.chat.messages.Message;
/**
* 对话记忆仓库接口,负责对话消息的持久化存储与查询,是连接业务逻辑与底层存储的桥梁。
* 提供基于会话ID的消息管理能力,支持多会话的消息持久化、查询和删除操作。
*/
public interface ChatMemoryRepository {
/**
* 查询所有存在的会话ID列表。
* 用于获取系统中已保存的所有对话会话标识,便于管理或展示历史会话列表。
*
* @return 所有会话ID的字符串列表,每个ID对应一个独立的对话上下文
*/
List<String> findConversationIds();
/**
* 根据会话ID查询该会话下的所有消息。
* 是多轮对话中恢复上下文的核心方法,为AI模型提供历史对话依据。
*
* @param conversationId 会话唯一标识,用于定位具体的对话上下文
* @return 该会话下按时间顺序排列的消息列表(包含用户输入、AI回复等)
*/
List<Message> findByConversationId(String conversationId);
/**
* 为指定会话批量保存消息。
* 用于将对话过程中产生的消息持久化存储,支持新增消息或覆盖已有消息。
*
* @param conversationId 会话唯一标识,指定消息所属的对话上下文
* @param messages 要保存的消息列表,通常包含本轮对话的新消息或完整的上下文消息
*/
void saveAll(String conversationId, List<Message> messages);
/**
* 根据会话ID删除该会话下的所有消息。
* 用于清理指定会话的历史记录,适用于会话结束、用户删除记录等场景。
*
* @param conversationId 会话唯一标识,指定要删除的对话上下文
*/
void deleteByConversationId(String conversationId);
}
通过了解上述两个接口的定义,我们完全可以根据自己的需要实现自己的 ChatMemory 和 ChatMemoryRepository 实现。
记忆类型
ChatMemory 抽象层支持实现多种记忆类型以适应不同场景。记忆类型(Memory Type)的选择将显著影响应用性能与行为特征。Spring AI 内置仅提供了 MessageWindowChatMemory,如下图:

MessageWindowChatMemory 类
MessageWindowChatMemory 是 ChatMemory 接口的一种特殊实现,专注于管理对话窗口内的上下文消息,通过限制记忆中保留的消息数量或时间范围,避免上下文过大导致的性能问题或 token 消耗过高(尤其在大模型调用中)。
MessageWindowChatMemory 默认维护 20 条消息,

当消息超限时,自动移除较早的对话消息(注意,始终保留系统消息,仅移除用户消息和 AI 回复的消息)。看上去,类似于“滑动窗口”机制,只保留最近的关键对话内容。
简单用法:
package com.hxstrive.springai.springai_openai.chatMemory2.config;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
/**
* AI配置
* @author Administrator
*/
@Configuration
public class AiConfig {
// 配置使用 JdbcChatMemoryRepository 来存储消息
@Bean
public ChatMemoryRepository chatMemoryRepository(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
return JdbcChatMemoryRepository.builder().jdbcTemplate(jdbcTemplate).build();
}
// 配置 ChatMemory
@Bean
public ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(10).build();
}
}
上述代码中,我们配置消息窗口的最大消息数量为 10,那么这个 10 是如何计算的呢?直接看输出日志就明白了:
2025-08-01T22:15:39.664+08:00 DEBUG 22124 --- [springai_demo1] [nio-8080-exec-7] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{
messages=[
SystemMessage{textContent='你是AI助手小粒,所有回复均使用中文。', messageType=SYSTEM, metadata={messageType=SYSTEM}},
AssistantMessage [messageType=ASSISTANT, toolCalls=[], textContent=“2”也有很多不同的含义,取决于上下文。以下是一些常见的解释:..., metadata={messageType=ASSISTANT}],
UserMessage{content='3是什么?', properties={messageType=USER}, messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[], textContent=“3”也可以有很多不同的意义,下面列出一些常见的解释:..., metadata={messageType=ASSISTANT}],
UserMessage{content='4是什么?', properties={messageType=USER}, messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[], textContent=“4”也有很多不同的含义,下面是一些常见的解释:..., metadata={messageType=ASSISTANT}],
UserMessage{content='5是什么?', properties={messageType=USER}, messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[], textContent=“5”同样有很多不同的含义,下面列出一些常见的解释:..., metadata={messageType=ASSISTANT}],
UserMessage{content='6是什么?', properties={messageType=USER}, messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[], textContent=“6”也有许多不同的含义,下面列举一些常见的解释:..., metadata={messageType=ASSISTANT}],
UserMessage{content='7是什么?', properties={messageType=USER}, messageType=USER}], modelOptions=OpenAiChatOptions: {"streamUsage":false,"model":"gpt-3.5-turbo","temperature":0.7}}, context={}
]
上述日志中,messages 数组的长度为 11 ,说明消息类型 SystemMessage 不在 maxMessages 的限制中。然后,messages 数组最后一条消息为我们当前提问的 UserMessage 消息,也就是说能向 messages 中放入 maxMessages - 1 条历史消息,一次会话算两条哦(UserMessage 和 AssistantMessage 分别进行计算)。
注意:MessageWindowChatMemory 是 Spring AI 自动配置 ChatMemory Bean 时采用的默认消息类型。
记忆存储
Spring AI 通过 ChatMemoryRepository 抽象层实现聊天记忆存储,Spring AI 帮我们实现了多种内置的存储实现,如下图:

上图这些实现类分别基于不同的存储技术,满足了不同应用场景下对话记忆的存储、查询和管理需求 ,以下是对图中这些实现类的简要介绍:
InMemoryChatMemoryRepository
基于 JVM 内存,将对话记忆数据存储在应用程序的内存中。适用于开发测试阶段、单用户的临时对话场景,或者对性能要求极高但不需要持久化存储对话记忆的应用,如一些简单的交互式工具或演示程序。
有如下特点:
轻量级和高性能:由于数据存储在内存中,读写操作无需进行磁盘 I/O 或网络通信,因此具有极高的访问速度,非常适合对性能要求极高的短期对话场景。
简单易用:无需外部的存储服务依赖,实现和配置相对简单,在开发和测试环境中使用方便,可以快速搭建对话系统原型。
数据易失性:数据随着应用程序的停止而丢失,不适合用于需要长期保存对话记忆的场景。
JdbcChatMemoryRepository
基于关系型数据库,通过 JDBC(Java Database Connectivity) 访问数据库,支持常见的关系型数据库,如 MySQL、PostgreSQL 等。
适用于企业级应用中,需要与现有的关系型数据库基础设施集成,并且对数据的事务性、一致性有严格要求的场景。
有如下特点:
CassandraChatMemoryRepository
基于 Apache Cassandra,这是一种开源的分布式 NoSQL 数据库,具有高可扩展性、高可用性和容错性。
适用于需要处理海量对话数据,对系统的扩展性、可用性要求极高,并且写操作频繁的大型分布式应用,如大型社交平台的对话记录存储。
有如下特点:
分布式架构:能够轻松应对高并发和大规模数据存储的需求,通过集群部署可以实现数据的自动分片和复制,确保在部分节点故障时仍能正常提供服务。
灵活的数据模型:采用列式存储结构,允许动态地定义数据模式,对于对话记忆这种数据结构可能会发生变化的场景,具有很好的适应性。
高性能写入:特别适合写入密集型的应用场景,在对话过程中,能够快速地将新的消息保存到记忆中,而不会因为写入操作过多影响系统性能。
Neo4jChatMemoryRepository
基于 Neo4j,这是一个图形数据库,专注于存储和处理关系数据。当需要深入分析对话之间的关系,挖掘对话数据中的关联信息时,如社交网络分析、客服对话质量评估等场景。
有如下特点:
关系建模:能够清晰地表示对话中各个消息之间的关系,以及不同对话之间的关联,例如可以方便地分析用户之间的对话模式、话题演变等。
高效的关系查询:通过图形查询语言(如 Cypher,是图形数据库 Neo4j 专用的查询语言,专为处理和查询数据间的关系而设计),可以快速地进行复杂的关系查询,比如查找某个用户与其他用户之间具有特定主题的对话记录。
数据可视化:Neo4j 提供了强大的数据可视化工具,可以直观地展示对话记忆中的关系结构,有助于进行数据分析和洞察。
对于上述这些 ChatMemoryRepository 实现类,后续将单独进行逐一介绍。
spring 广告位
聊天客户端的 Memory
使用 ChatClient API 时,可通过注入 ChatMemory 实现来维护跨多轮交互的会话上下文。在本文前面的“快速入门”部分我们介绍了 ChatMemory 的基本用法:
// 1. 将用户输入添加到记忆
UserMessage userMessage = new UserMessage(message);
chatMemory.add(sessionId, userMessage);
// 2. 获取记忆中的所有消息(上下文),传递给 AI 模型
ChatClient.CallResponseSpec responseSpec = chatClient.prompt().messages(chatMemory.get(sessionId)).call();
// 3. 将 AI 回复添加到记忆,更新上下文
AssistantMessage assistantMessage = responseSpec.chatResponse().getResult().getOutput();
chatMemory.add(sessionId, assistantMessage);
虽然实现了预期效果,能够提供记忆功能,但使用有点繁琐,需要自己去添加消息到 ChatMemory 中,从 ChatMemory 中获取消息。结合前面学习过的 Advisor(见 Spring AI 核心组件 Advisor),是否可以自动帮我们进行消息记忆呢!答案是肯定的。
Spring AI 提供多种内置 Advisor 实现,用于按需配置 ChatClient 的记忆行为。分别是 MessageChatMemoryAdvisor、PromptChatMemoryAdvisor 和 VectorStoreChatMemoryAdvisor。
注意:当前版本存在限制,执行工具调用时与大型语言模型交互的中间消息不会存入记忆。该问题将在后续版本修复。
MessageChatMemoryAdvisor
MessageChatMemoryAdvisor 通过指定 ChatMemory 实现管理会话记忆。每次交互时从记忆库检索历史消息,并将其作为消息集合注入提示词。
核心源码如下图:
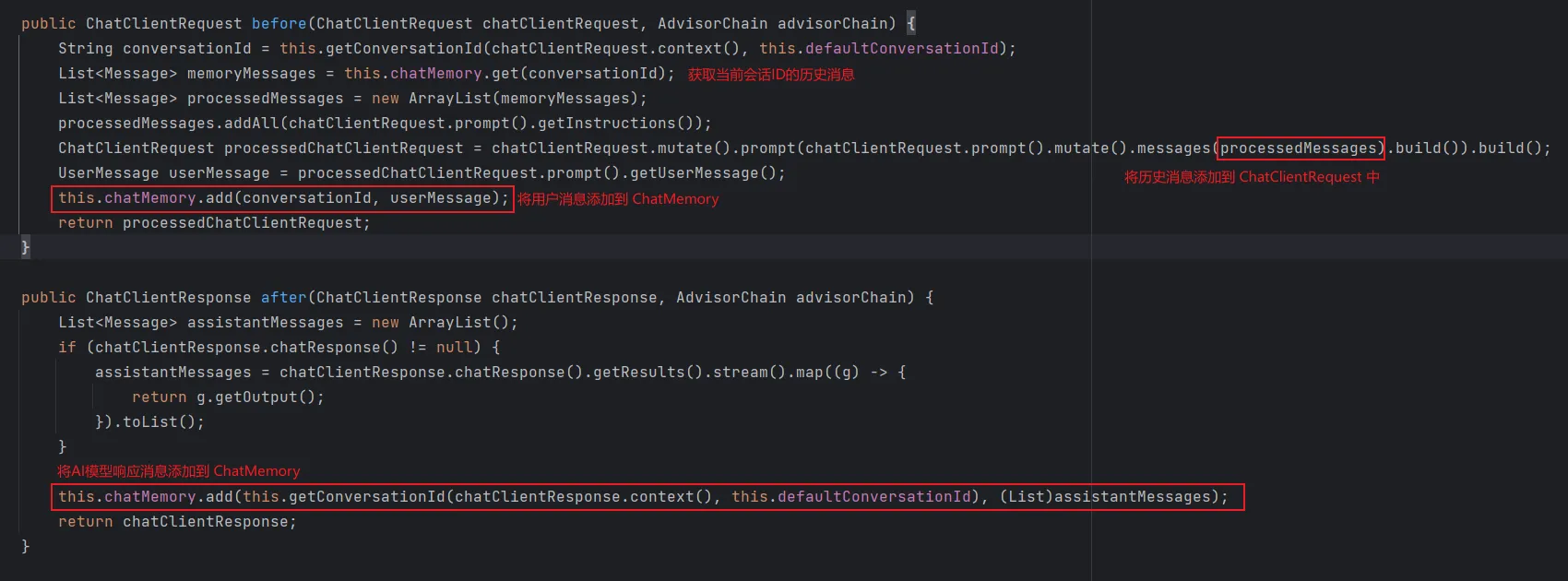
上图中,before() 方法将在调用大模型之前执行,after() 将在调用之后执行,本质就是一个拦截器,在调用前后进行处理。详细内容参考 MessageChatMemoryAdvisor 对话历史管理
PromptChatMemoryAdvisor
PromptChatMemoryAdvisor 基于指定 ChatMemory 实现管理会话记忆。每次交互时从记忆库检索历史对话,并以纯文本形式追加至系统(system)提示词。
PromptChatMemoryAdvisor 采用默认模板(PromptTemplate DEFAULT_SYSTEM_PROMPT_TEMPLATE)将检索到的会话记忆增强至系统消息,可以通过 promptTemplate() 构建方法注入自定义 PromptTemplate 对象可覆盖该行为。如下图:
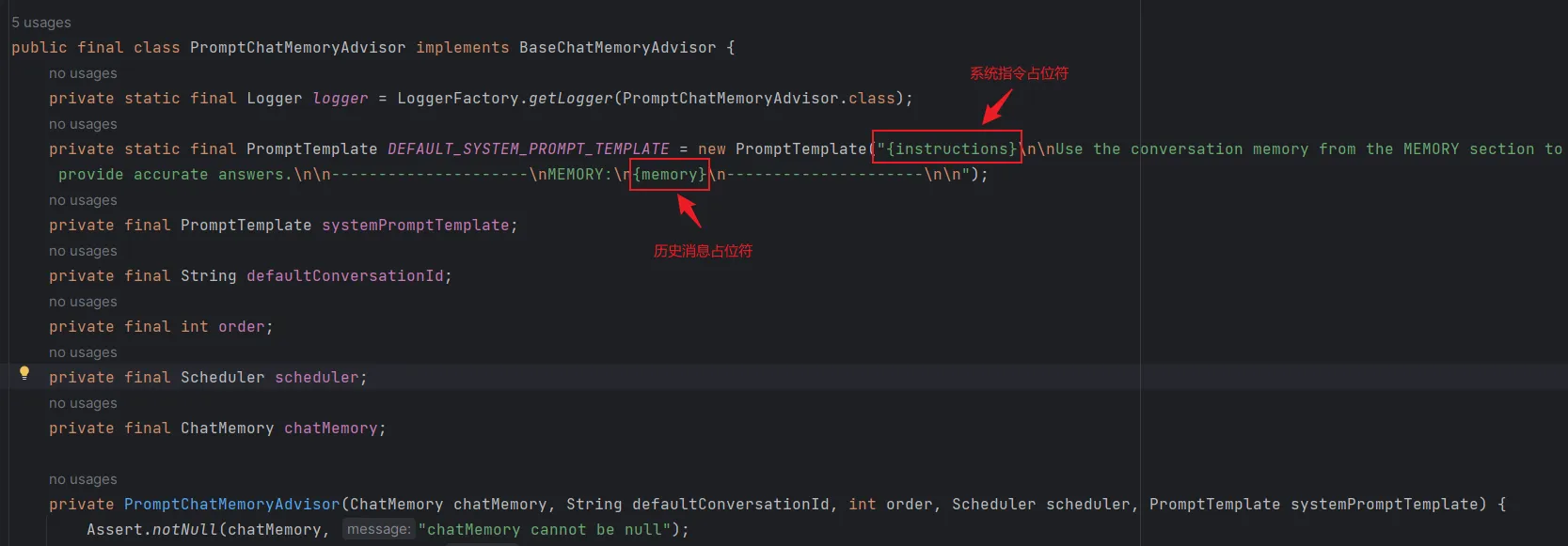
此处提供的 PromptTemplate 用于定制 Advisor 如何将检索到的记忆与系统消息合并。这与在 ChatClient 上配置 TemplateRenderer 通过 templateRenderer() 不同 —— 后者影响 Advisor 运行前初始 user/system 提示内容的渲染。
注意,自定义 PromptTemplate 可采用任何 TemplateRenderer 实现,Spring AI 默认使用基于 StringTemplate 引擎的 StPromptTemplate)。如下图:
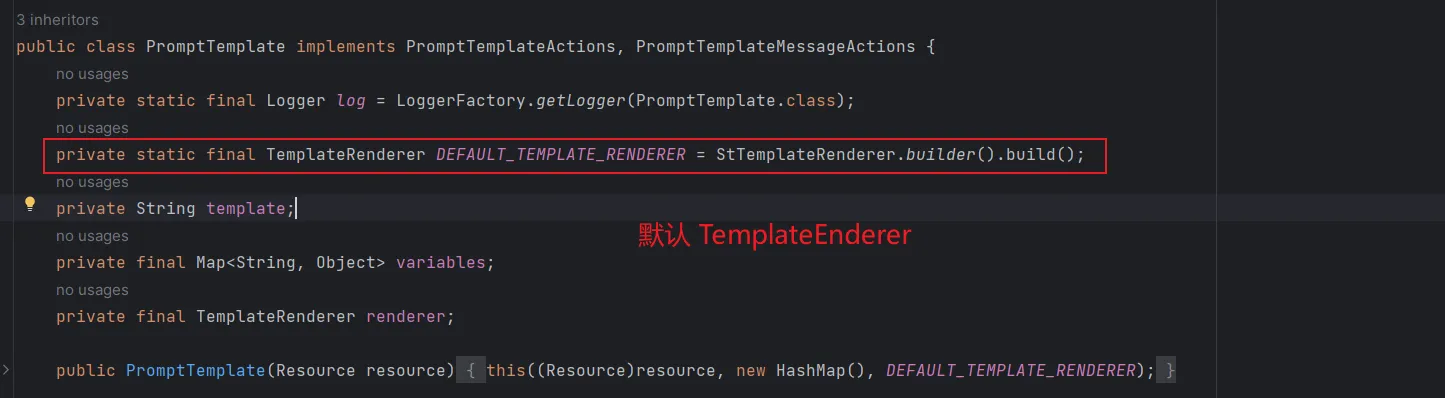
模板必须包含以下两个占位符:
详细内容参考 PromptChatMemoryAdvisor 动态优化提示词
VectorStoreChatMemoryAdvisor
VectorStoreChatMemoryAdvisor 通过指定 VectorStore 实现管理会话记忆。每次交互时从向量存储检索历史对话,并以纯文本形式追加至系统(system)消息。
VectorStoreChatMemoryAdvisor 通过默认模板(DEFAULT_SYSTEM_PROMPT_TEMPLATE)将检索到的会话记忆增强至系统消息。可以通过 promptTemplate() 构建方法注入自定义 PromptTemplate 对象可覆盖该行为。如下图:
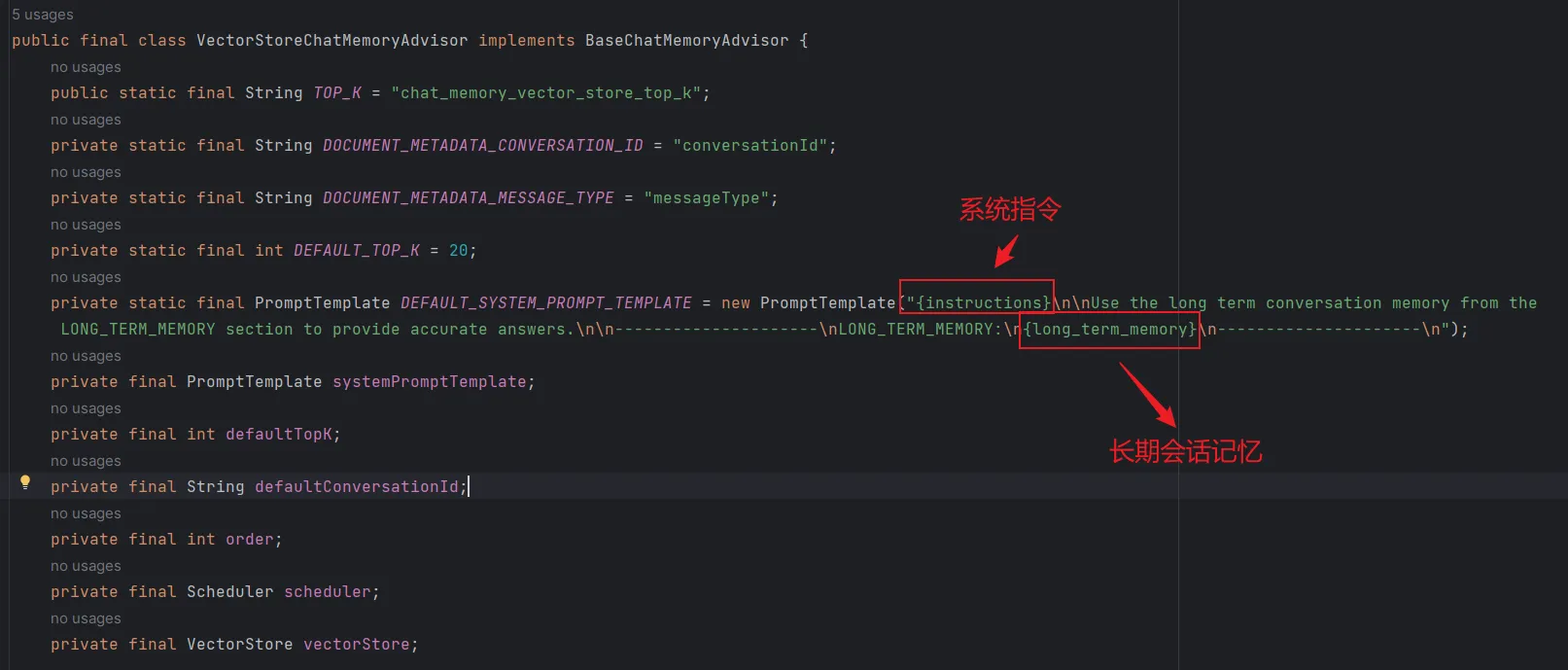
此处提供的P romptTemplate 专门用于配置 Advisor 如何整合检索记忆与系统消息,这与 ChatClient 自身的 TemplateRenderer 配置(通过 templateRenderer())有本质区别 —— 后者控制 Advisor 执行前原始 user/system 提示内容的渲染逻辑。
注意,自定义 PromptTemplate 可采用任意 TemplateRenderer 实现(默认使用基于 StringTemplate 引擎的 StPromptTemplate)。模板必须包含以下两个占位符:
详细内容参考 VectorStoreChatMemoryAdvisor 向量存储聊天历史
简单示例
例如,若需结合 MessageWindowChatMemory 与 MessageChatMemoryAdvisor,可按如下方式配置:
@RestController
class MyController {
@Autowired
private ChatModel chatModel;
/**
* 创建 MessageWindowChatMemory 实例
* 注意:不要在 ai() 方法中创建该实例,否则会导致每次请求 /ai 地址都会创建新的 MessageWindowChatMemory 实例,
* 也导致内部的 MessageWindowChatMemory 中使用的 InMemoryChatMemoryRepository 每次都是新的实例,
* 这样就会导致每次请求时通过会话ID查询信息为 null,因为 InMemoryChatMemoryRepository 通过全局变量
* Map<String, List<Message>> chatMemoryStore = new ConcurrentHashMap();
* 来保存用户会话信息。chatMemoryStore 不是静态的,不同实例拥有不同的 chatMemoryStore 成员
*/
private static final ChatMemory chatMemory = MessageWindowChatMemory.builder().build();
// http://localhost:8080/ai?message=四川大学是211吗?
// http://localhost:8080/ai?message=是985吗?
@GetMapping(value = "/ai",produces = "text/html; charset=UTF-8")
public String ai(@RequestParam("message") String message) {
// 唯一会话ID,同一个会话上下文中保持一致
String sessionId = "USER-250801100723";
// 配置 ChatClient
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("你是AI助手小粒,所有回复均使用中文。")
.defaultAdvisors(
// 自动实现会话记录,记得调用 conversationId(sessionId) 绑定到指定的会话ID
MessageChatMemoryAdvisor.builder(chatMemory).conversationId(sessionId).build(),
new SimpleLoggerAdvisor() // 输出聊天日志
)
.build();
return chatClient.prompt().advisors(advisors -> {
// 设置会话ID
advisors.param(ChatMemory.CONVERSATION_ID, sessionId);
}).user(message).call().content();
}
}
调用 ChatClient 时,MessageChatMemoryAdvisor 将自动管理记忆存储。
注意,如果直接使用 ChatModel 而非 ChatClient,需显式管理记忆存储,例如:
// 创建 memory 实例
ChatMemory chatMemory = MessageWindowChatMemory.builder().build();
String conversationId = "007"; // 会话ID
// 首次交互
// 1.创建用户消息,并将用户消息添加到 ChatMemory
UserMessage userMessage1 = new UserMessage("My name is James Bond");
chatMemory.add(conversationId, userMessage1);
// 2.调用模型,将模型返回内容添加到 ChatMemory
// chatMemory.get(conversationId) 从 ChatMemory 中获取消息列表,受最大消息个数限制
ChatResponse response1 = chatModel.call(new Prompt(chatMemory.get(conversationId)));
chatMemory.add(conversationId, response1.getResult().getOutput());
// 第二次交互
// 3.创建用户消息,继续添加到 ChatMemory 中
UserMessage userMessage2 = new UserMessage("What is my name?");
chatMemory.add(conversationId, userMessage2);
// 4.发起模型调用,将结果添加到 ChatMemory 中
ChatResponse response2 = chatModel.call(new Prompt(chatMemory.get(conversationId)));
chatMemory.add(conversationId, response2.getResult().getOutput());
// 响应会包含 "James Bond"
下面是上述示例执行问完成后的消息列表:
My name is James Bond
首次交互返回消息
What is my name?
第二次交互返回消息
下图展示了在示例交互各阶段传递给大模型的消息列表:
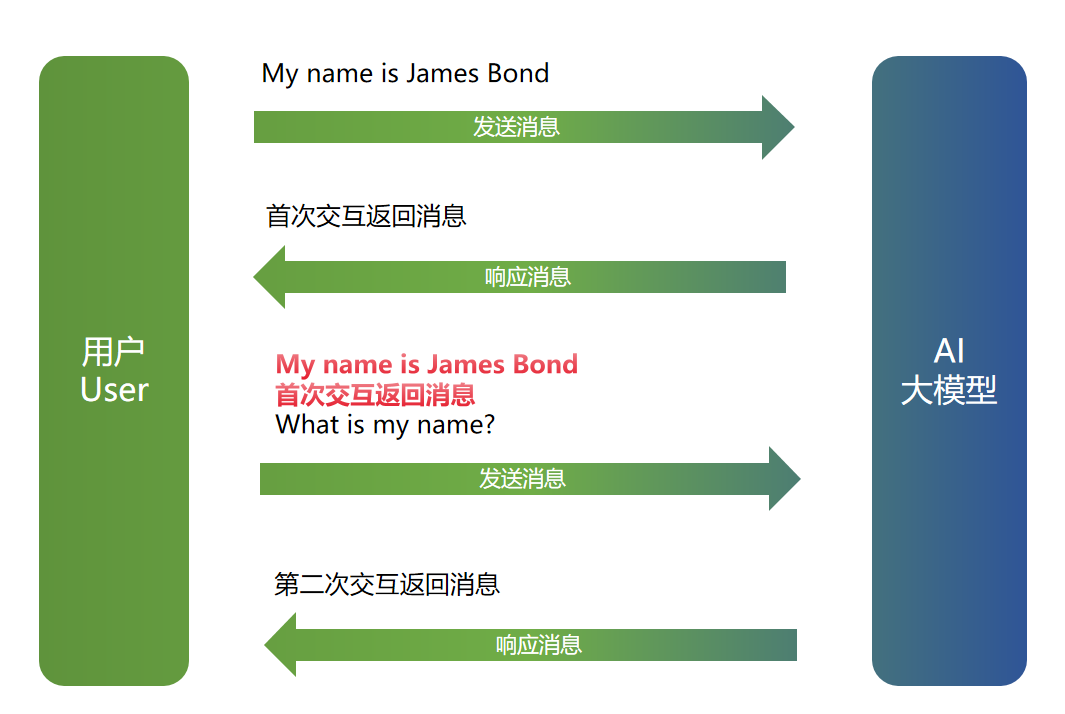
从上图可知,第二轮发送消息时将第一轮的问题和响应一起发送给了AI大模型。

 川公网安备51010802032098
川公网安备51010802032098