在人工智能(AI)领域,多模态(Multimodal) 指的是模型能够处理、理解或生成多种不同类型的信息(即 “模态”),并实现不同模态之间的交互与融合。这些模态通常对应人类感知世界的多种方式,如视觉、听觉、语言等,也包括文本、图像、音频、视频、传感器数据等具体形式。
“模态” 本质上是信息的载体或表现形式。常见的模态包括:
文本(Text):如自然语言句子、段落、文档等;
图像(Image):如照片、图表、截图等视觉信息;
音频(Audio):如语音、音乐、环境声音等;
视频(Video):连续的图像序列 + 音频的组合;
其他:如传感器数据(温度、加速度)、3D 点云、手势动作等。
单模态模型只能处理一种模态(如纯文本模型只能理解文字,纯图像模型只能识别图片),而多模态模型则能同时处理两种或以上模态,甚至在不同模态间进行转换(如“图像转文字”和“文字生成音频”)。
人类通过多模态数据输入并行处理知识。我们的学习方式和体验都是多模态的 —— 不只有视觉、听觉或文本的单一感知。
然而,机器学习往往专注于处理单一模态的专用模型。例如,我们开发音频模型用于文本转语音或语音转文本任务,开发计算机视觉模型用于目标检测和分类等任务。
然而,新一代多模态大语言模型正在兴起。例如 OpenAI 的 GPT-4o、Google 的 Vertex AI Gemini 1.5、Anthropic 的 Claude3,以及开源模型 Llama3.2、LLaVA 和 BakLLaVA,都能接受文本、图像、音频和视频等多种输入,并通过整合这些输入生成文本响应。
多模态大语言模型(LLM)的特性使其能够结合图像、音频或视频等其他模态处理并生成文本。
Spring AI 多模态
多模态性指模型同时理解和处理文本、图像、音频及其他数据格式等多源信息的能力。Spring AI 的 Message API 提供了支持多模态 LLM 所需的所有抽象。类图如下:
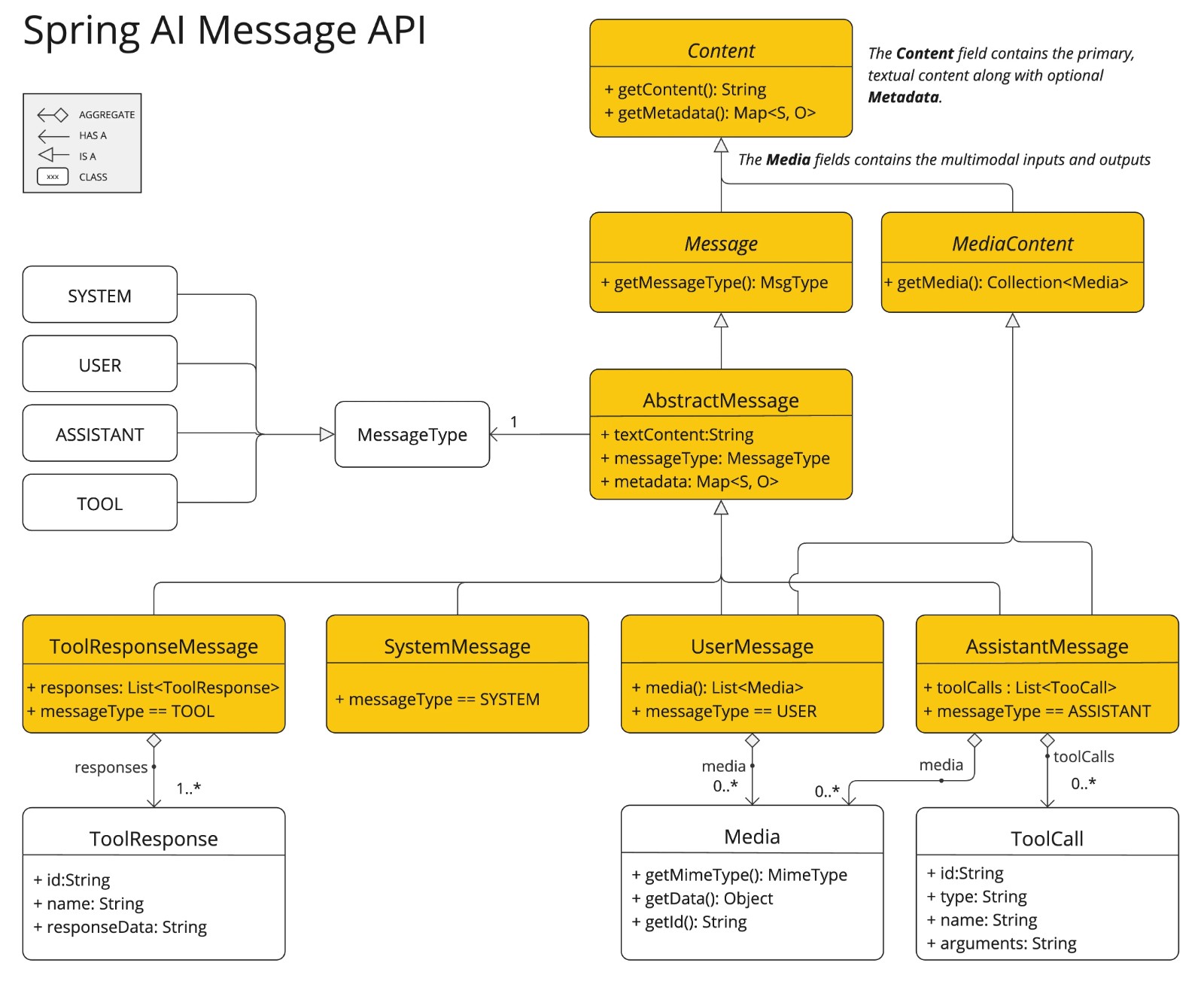
上图,UserMessage 的 content 字段主要用于文本输入,而可选的 media 字段允许添加图像、音频和视频等多模态内容。MimeType 指定模态类型,根据所用 LLM 的不同,Media 数据字段可以是原始媒体内容(作为 Resource 对象)或内容 URI。
🌈注意:目前 media 字段仅适用于用户输入消息(如 UserMessage),对系统消息无意义。包含 LLM 响应的 AssistantMessage 仅提供文本内容。要生成非文本媒体输出,应使用专用的单模态模型。
spring 广告位
简单示例
我们可以将下图(multimodal.test.png)作为输入,要求 LLM 解释它所识别的内容。

配置信息如下:
spring:
application:
name: springai_demo1
# 数据库配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/chat_db
username: root
password: aaaaaa
# AI配置
ai:
# openai相关配置
openai:
# 基础地址
base-url: https://api.xty.app
# AI KEY
api-key: sk-vHTHX8D3wNZBfRya831a6f562**************************
# 聊天模型配置
chat:
options:
model: gpt-3.5-turbo
# 图片模型配置
image:
options:
# 需要高级接口
model: dall-e-3
chat:
memory:
# 会话历史持久化
repository:
jdbc:
# 启动时不自动执行初始化SQL脚本,手动创建数据表
initialize-schema: never
client:
# true 开启,自动注入 ChatClient,false 关闭,需要手动创建 ChatClient
enabled: true
# 日志配置
logging:
charset:
console: UTF-8
level:
root: info
org.springframework.ai: debug
对于大多数多模态 LLM,Spring AI 代码通常如下所示:
package com.hxstrive.springai.springai_openai.multi_modal1.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.content.Media;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.util.MimeTypeUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class MyController {
@Autowired
private ChatModel chatModel;
// http://localhost:8080/ai
@GetMapping(value = "/ai",produces = "text/html; charset=UTF-8")
public String ai() {
// 图片资源
Resource imageResource = new ClassPathResource("/static/image/multimodal.test.png");
UserMessage userMessage = UserMessage.builder()
// 提示语
.text("解释一下你在这张图片中看到了什么?")
// 添加图片资源
.media(new Media(MimeTypeUtils.IMAGE_PNG, imageResource))
.build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
return chatClient.prompt(new Prompt(userMessage)).call().content();
}
}
运行应用,效果如下图:

或使用 Fluent 风格的 ChatClient API 实现,如下:
package com.hxstrive.springai.springai_openai.multi_modal2.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.util.MimeTypeUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class MyController {
@Autowired
private ChatModel chatModel;
// http://localhost:8080/ai
@GetMapping(value = "/ai",produces = "text/html; charset=UTF-8")
public String ai() {
// 图片资源
Resource imageResource = new ClassPathResource("/static/image/multimodal.test.png");
return ChatClient.create(chatModel).prompt()
.advisors(new SimpleLoggerAdvisor())
.user(u -> u.text("解释一下你在这张图片中看到了什么?")
.media(MimeTypeUtils.IMAGE_PNG, imageResource))
.call()
.content();
}
}
运行应用,输出如下图:

查看一下后端输出日志,了解请求和响应格式,如下:
2025-07-31T20:29:23.900+08:00 DEBUG 23044 --- [springai_demo1] [nio-8080-exec-2] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{messages=[UserMessage{content='解释一下你在这张图片中看到了什么?', properties={messageType=USER}, messageType=USER}], modelOptions=OpenAiChatOptions: {"streamUsage":false,"model":"gpt-3.5-turbo","temperature":0.7}}, context={}]
2025-07-31T20:30:32.150+08:00 DEBUG 23044 --- [springai_demo1] [nio-8080-exec-2] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"finishReason" : "STOP",
"refusal" : "",
"index" : 0,
"annotations" : [ ],
"id" : "chatcmpl-k77GzVbVcCEt1rHC4bP1nsvWXWFDI"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "在这张图片中,我看到一个金属水果篮,篮子里有一些香蕉和红色的苹果。香蕉的皮上有一些小斑点,看起来成熟且略有些老化,而苹果则比较圆润且色泽鲜亮。背景色较为简单,给人一种温馨、宁静的感觉。"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
},
"metadata" : {
"id" : "chatcmpl-k77GzVbVcCEt1rHC4bP1nsvWXWFDI",
"model" : "gpt-3.5-turbo-0613",
"rateLimit" : {
"requestsLimit" : null,
"requestsRemaining" : null,
"requestsReset" : null,
"tokensLimit" : null,
"tokensRemaining" : null,
"tokensReset" : null
},
"usage" : {
"promptTokens" : 449,
"completionTokens" : 123,
"totalTokens" : 572,
"nativeUsage" : {
"completion_tokens" : 123,
"prompt_tokens" : 449,
"total_tokens" : 572
}
},
"promptMetadata" : [ ],
"empty" : false
},
"results" : [ {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"finishReason" : "STOP",
"refusal" : "",
"index" : 0,
"annotations" : [ ],
"id" : "chatcmpl-k77GzVbVcCEt1rHC4bP1nsvWXWFDI"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "在这张图片中,我看到一个金属水果篮,篮子里有一些香蕉和红色的苹果。香蕉的皮上有一些小斑点,看起来成熟且略有些老化,而苹果则比较圆润且色泽鲜亮。背景色较为简单,给人一种温馨、宁静的感觉。"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
} ]
}
目前,Spring AI 为以下聊天模型提供多模态支持:

 川公网安备51010802032098
川公网安备51010802032098