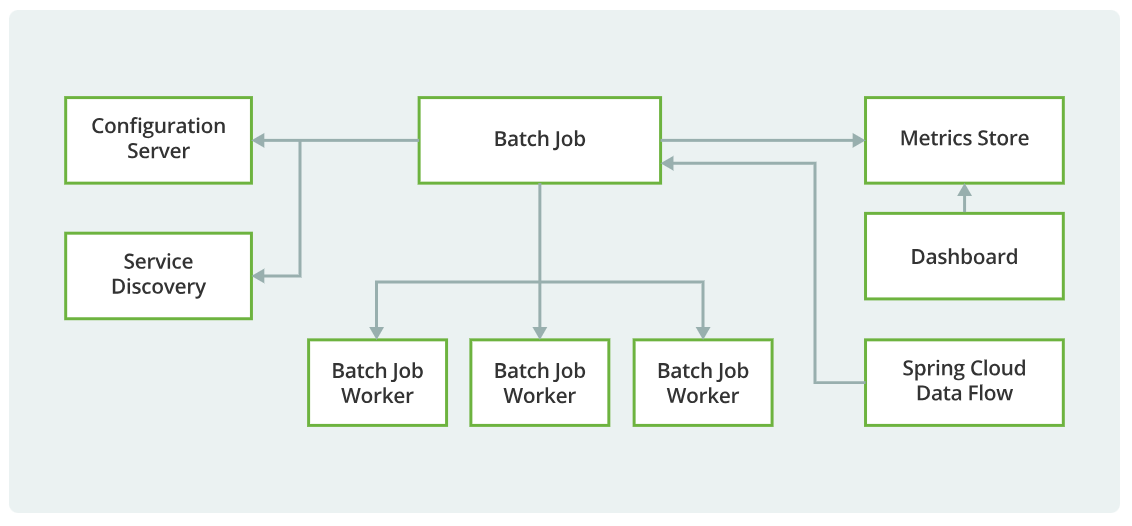
需要注意的是,根据经验法则,批处理流程采用的提交和锁定策略取决于所执行的处理类型,并且在线锁定策略也应遵循相同的原则。因此,在设计整体架构时,批处理架构不能仅仅是事后的想法。
锁定策略可以是仅使用普通的数据库锁,也可以是在架构中额外实施一个自定义的锁定服务。该锁定服务将跟踪数据库锁定情况(例如,通过将必要信息存储在一个专用的数据库表中),并对请求数据库操作的应用程序授予或拒绝权限。此架构还可以实施重试逻辑,以避免在出现锁定情况时中止批处理作业。
批处理窗口中的常规处理
对于在单独的批处理窗口中运行的简单批处理流程,如果正在更新的数据不需要供在线用户或其他批处理流程使用,那么并发就不是问题,并且可以在批处理运行结束时进行一次提交。
在大多数情况下,采用更稳健的方法更为合适。要记住,随着时间的推移,批处理系统在复杂性和处理的数据量方面都有增长的趋势。如果没有制定锁定策略,且系统仍然依赖单个提交点,那么修改批处理程序可能会很棘手。因此,即使是最简单的批处理系统,也要考虑为重启恢复选项设置提交逻辑的必要性,以及本节后面所述的更复杂情况相关的信息。
并发批处理或联机处理
处理的数据可被联机用户同时更新的批处理应用程序,不应锁定联机用户可能需要的任何数据(无论是数据库中的还是文件中的)超过几秒。此外,每完成几笔事务后,就应将更新提交到数据库。这样可将其他进程无法使用的数据部分以及数据不可用的时间降至最低。
另一种将物理锁定降至最低的方法是,采用乐观锁定模式或悲观锁定模式来实现逻辑行级锁定。
乐观锁
乐观锁假设数据记录被竞争的可能性较低(即被两个线程或用户同时使用)。它通常意味着在批处理和联机处理同时使用的每个数据库表中插入一个时间戳列。当应用程序获取一行进行处理时,它也会获取时间戳。然后,当应用程序尝试更新已处理的行时,更新会在 WHERE 子句中使用原始时间戳。如果时间戳匹配,则更新数据和时间戳。如果时间戳不匹配,则表明在获取和尝试更新之间,另一个应用程序已更新了同一行。因此,无法执行更新。
悲观锁
悲观锁是一种假设很有可能发生数据记录被竞争的锁定策略(即很有可能一份数据被多个人使用),因此在检索数据时需要获取物理锁或逻辑锁。
一种悲观逻辑锁是在数据库表中使用一个专门的锁列。当应用程序检索某行数据进行更新时,它会在锁列中设置一个标志。有了这个标志,其他试图检索同一行数据的应用程序在逻辑上就会失败。当设置标志的应用程序更新该行数据时,它也会清除该标志,以便其他应用程序可以检索该行数据。
请注意,在初始获取数据和设置标志之间,也必须维护数据的完整性(也就是说,两者必须是原子操作,不要出现:数据获取成功,设置锁状态失败,或者被其他程序抢先设置),例如通过使用数据库锁(如 SELECT FOR UPDATE)。
还要注意,这种方法与物理锁有相同的缺点,只是构建一个超时机制相对更容易管理一些,如果用户在记录被锁定期间去吃午饭,超时机制可以释放锁(还考虑另一个问题,超时时间设置多久?设置过长,也就意味着数据长时间被锁定;设置过段,批处理还没有处理完,锁定标记就被清理了)。
这些模式不一定适合批量处理,但它们可用于并发批量处理和联机处理(例如在数据库不支持行级锁定的情况下)。一般来说,乐观锁更适合联机应用程序,而悲观锁更适合批量应用程序。注意,只要使用了逻辑锁,所有访问受逻辑锁保护的数据实体的应用程序都必须使用相同的方案。
请注意,这两种解决方案都仅涉及锁定单个记录。通常,我们可能需要锁定逻辑相关的一组记录。对于物理锁,为了避免潜在的死锁,你必须非常谨慎地管理这些锁。对于逻辑锁,通常最好构建一个逻辑锁管理器,它了解你想要保护的逻辑记录组,并能确保锁的一致性且不会导致死锁。这个逻辑锁管理器通常使用自己的表来进行锁管理、争用报告、超时机制以及处理其他相关问题。
spring 广告位
并行处理(Parallel Processing)
并行处理允许多个批处理运行或作业并行运行,以尽量减少批处理的总耗时。只要这些作业不共享相同的文件、数据库表或索引空间,这就不成问题。如果它们共享,那么这项服务应使用分区数据来实现。
另一种选择是构建一个架构模块,通过使用控制表来维护相互依赖关系。控制表应对每个共享资源都包含一行,记录该资源是否正被某个应用程序使用。并行作业中的批处理架构或应用程序随后将从该表中检索信息,以确定它是否能够访问所需的资源。如果数据访问不成问题,可通过使用额外线程来并行处理,从而实现并行处理。
在大型机环境中,传统上会使用并行作业类,以确保所有进程都有足够的CPU时间。无论如何,解决方案必须足够强大,以确保为所有正在运行的进程分配时间片。并行处理中的其他关键问题包括负载均衡以及文件、数据库缓冲池等通用系统资源的可用性。还要注意,控制表本身很容易成为关键资源。
分区(Partitioning)
使用分区功能可让大型批处理应用程序的多个版本同时运行。这样做的目的是减少处理长时间批处理作业所需的耗时。能够成功分区的流程,是那些其输入文件可拆分和/或主数据库表可分区的流程,以便应用程序针对不同数据集运行。
此外,已分区的进程必须设计为仅处理其分配的数据集。分区架构必须与数据库设计和数据库分区策略紧密相关。请注意,数据库分区并不一定意味着对数据库进行物理分区,尽管在大多数情况下建议这样做。下图说明了分区方法:
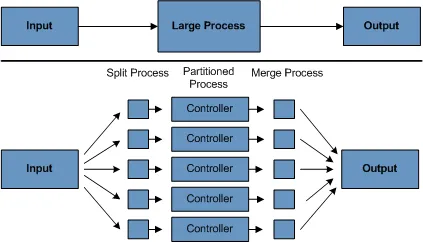
架构应具备足够的灵活性,以允许对分区数量进行动态配置。应同时考虑自动配置和用户控制的配置。自动配置可基于诸如输入文件大小和输入记录数量等参数。
分区方法
选择分区方法必须根据具体情况来进行。以下列表描述了一些可能的分区方法:
1. 记录集固定均匀拆分
这涉及将输入记录集拆分为偶数个部分(例如 10 个,每个部分恰好占整个记录集的十分之一)。然后,批处理/提取应用程序的一个实例会处理每个部分。
为了使用这种方法,需要进行预处理来拆分记录集。这种拆分的结果将是一个下限和上限位置编号,可作为批处理/提取应用程序的输入,以便将其处理限制在其对应的部分。
预处理可能会带来很大的开销,因为它必须计算并确定记录集每个部分的边界。
2. 按关键列拆分
这涉及到按关键列(如位置代码)拆分输入记录集,并将每个键的数据分配给一个批处理实例。为实现这一点,列值可以通过以下两种方式:
在选项 1 下,添加新值意味着手动重新配置批处理 / 提取操作,以确保新值被添加到特定实例中。
在选项 2 下,这确保了所有值都能通过批处理作业的一个实例进行处理。然而,一个实例处理的值数量取决于列值的分布情况(0000-0999 范围内可能有大量位置,而 1000-1999 范围内可能较少)。在此选项下,设计数据范围时应考虑分区。
在这两种选项下,都无法实现记录到批处理实例的最优均匀分布。所使用的批处理实例数量也无法动态配置。
3. 按视图拆分
这种方法基本上是按关键列进行拆分,但在数据库层面进行。它涉及将记录集拆分为视图。批处理应用程序的每个实例在处理过程中都会使用这些视图。拆分是通过对数据进行分组来完成的。
使用此选项时,必须将批处理应用程序的每个实例配置为访问特定视图(而非主表)。此外,随着新数据值的添加,这组新数据必须包含在一个视图中。由于实例数量的变化会导致视图的变化,因此不存在动态配置功能。
4. 添加处理指示符
这涉及在输入表中添加一个新列,该列用作指示符。作为预处理步骤,所有指示符都标记为未处理。在批处理应用程序的记录获取阶段,仅在记录标记为未处理的条件下读取记录,并且一旦读取(加锁),就将其标记为正在处理。当记录完成时,指示符更新为已完成或错误。批处理应用程序的许多实例可以在不做更改的情况下启动,因为新增列确保记录仅被处理一次。
通过此选项,表上的输入 / 输出会动态增加。对于更新型批处理应用程序,这种影响会减小,因为无论如何都必须进行写入操作。
5. 将表提取到平面文件
这涉及将表提取到一个文件中。然后该文件可被分割成多个片段,并用作批处理实例的输入。
通过此选项,将表提取到文件并进行分割所带来的额外开销,可能会抵消多分区的效果。可以通过更改文件分割脚本实现动态配置。
6. 使用哈希列
此方案涉及在用于检索驱动记录的数据库表中添加一个哈希列(键 / 索引)。该哈希列有一个指示器,用于确定批处理应用程序的哪个实例处理这一特定行。例如,如果要启动三个批处理实例,那么指示器 “A” 标记的行将由实例 1 处理,指示器 “B” 标记的行将由实例 2 处理,指示器 “C” 标记的行将由实例 3 处理。
检索记录的过程将有一个额外的 WHERE 子句,用于选择由特定指示器标记的所有行。在此表中插入数据将涉及添加标记字段,该字段将默认为其中一个实例(如 “A”)。
可以使用一个简单的批处理应用程序来更新指示器,例如在不同实例之间重新分配负载。当添加了足够多的新行时,可以运行此批处理(除批处理窗口外的任何时间),将新行重新分配到其他实例。
批处理应用程序的其他实例只需按照前面段落所述运行批处理应用程序,重新分配指示器,以适应新数量的实例。
数据库与应用程序设计原则
一种支持多分区应用程序的架构,这些应用程序使用关键列方法(可以根据业务选择合适的列,如:id、时间戳等)针对分区数据库表运行,该架构应包含一个中央分区存储库,用于存储分区参数。这提供了灵活性并确保了可维护性。该存储库通常由单个表组成,称为分区表。
存储在分区表中的信息是静态的,一般应由数据库管理员(DBA)维护。该表应为多分区应用程序的每个分区包含一行信息。该表应具有以下列:程序 ID 代码、分区号(分区的逻辑 ID)、此分区的数据库关键列低值以及此分区的数据库关键列高值(如使用 id 列来进行分区,一个分区可以表示为 1000 <= id < 5000,分区处理 id 位于 1000~5000 之间的数据)。
在程序启动时,程序 id 和分区号应从架构(具体来说,从控制处理任务)传递给应用程序。如果使用关键列方法,这些变量将用于读取分区表,以确定应用程序要处理的数据范围。此外,在整个处理过程中必须使用分区号来:
spring 广告位
减少死锁
当应用程序并行运行或进行分区时,可能会出现数据库资源争用和死锁情况。数据库设计团队在数据库设计过程中尽可能消除潜在的争用情况至关重要。
此外,开发人员必须确保在设计数据库索引表时考虑到死锁预防和性能。
死锁或热点问题经常出现在管理或架构表中,如日志表、控制表和锁表。这些情况的影响也应予以考虑。进行真实的压力测试对于识别架构中可能存在的瓶颈至关重要。
为了尽量减少冲突对数据的影响,架构应提供诸如在连接数据库或遇到死锁时的等待和重试间隔等服务。这意味着要有一种内置机制来响应特定的数据库返回代码,不是立即发出错误,而是等待一段预定的时间后重试数据库操作。
参数传递与验证
分区架构对应用程序开发人员而言应相对透明。该架构应执行与以分区模式运行应用程序相关的所有任务,包括:
在应用程序启动前检索分区参数。
在应用程序启动前验证分区参数。
在启动时将参数传递给应用程序。
验证应包括检查以确保:
应用程序有足够的分区来涵盖整个数据范围。
分区之间没有间隙。
如果数据库是分区的,可能需要进行一些额外的验证,以确保单个分区不会跨越数据库分区。
此外,该架构应考虑分区的整合。关键问题包括:
是否必须在进入下一个作业步骤之前完成所有分区?
如果其中一个分区中止会发生什么?

 川公网安备51010802032098
川公网安备51010802032098