前面章节介绍了 Spring Batch 的架构,下面将快速介绍的核心概念。理解这些概念是有效使用 Spring Batch 的关键。
先来看一张图:
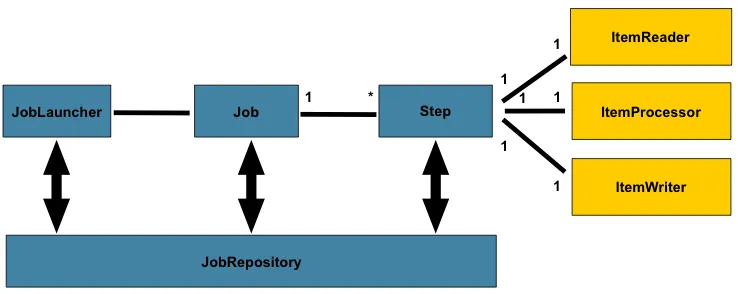
上图中,创建了一个 Job,该 Job 有一至多个 Step(步骤),每个 Step 正好有一个 ItemReader(读取数据),一个 ItemProcessor(处理数据),和一个 ItemWriter(写出数据)。Job 通过 JobLauncher 进行启动,Job 的元数据使用 JobRepository 进行持久化,即保存到数据库。
Job(作业)
作业(Job)可以理解为一个完整的批处理任务,是 Spring Batch 的顶层抽象。一个作业由一个或多个步骤(Step)按顺序或条件组合而成。
与其他 Spring 项目一样,一个 Job 与 XML 配置文件或基于Java 的配置连接在一起。这种配置可以被称为 “Job 配置”。然而,Job 只是整个层次结构的顶端,如下图所示:
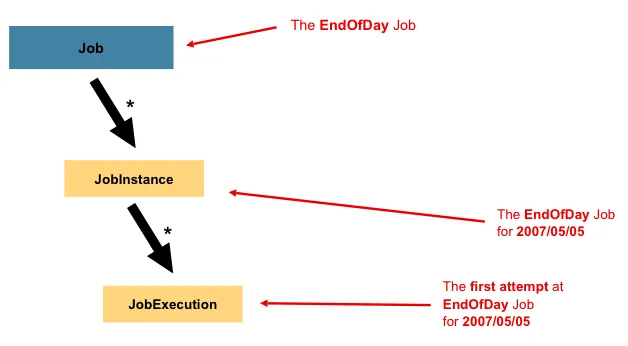
上图表示,一个名为“EndOfDay”的 Job,该 Job 存在一个时间为 2007/5/5 的实例 JobInstance,该 JobInstance 尝试首次执行 JobExecution。
在 Spring Batch 中,Job 只是一个 Step 实例的容器(一个 Job 包含多个 Step)。它将逻辑上属于一个流程的多个 step 结合在一起,并允许配置所有 step 的全局属性,如重新启动的能力。Job 的配置包含:
Job 的名称。
Step 实例的定义和排序。
Job 是否可以重新启动。
Job的特性:
通过 JobBuilderFactory 创建,支持唯一命名(如 importUserJob)。
可配置 JobParameters(作业参数),用于标识作业实例(如日期、文件路径)。
支持作业实例(JobInstance) 和 作业执行(JobExecution) 的概念:
JobInstance(Job 实例)
JobInstance 指的是一个逻辑 Job 运行概念,Job 和 JobInstance 的关系和 Java 类与对象的关系类似。考虑一个应该在一天结束时运行一次的批处理 Job,如上图中名为“EndOfDay”的 Job。有了一个名为“EndOfDay”的 Job,但该 Job 的每次单独运行都必须被单独跟踪。如下图:
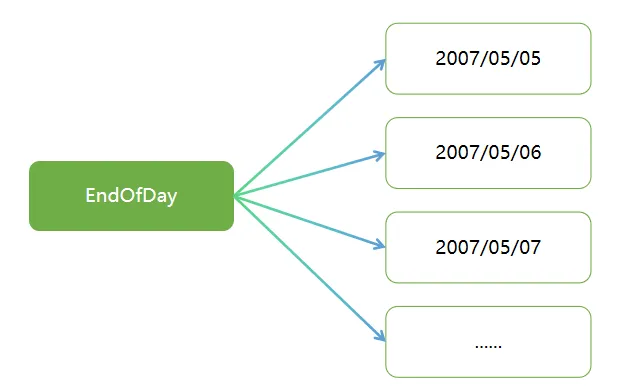
上图展示了名为“EndOfDay”的 Job 在2007年5月5日、6日、7日等多天的每日运行情况,需要对其进行分别跟踪。每日“EndOfDay”Job 的运行构成一个逻辑上的 JobInstance。例如,5 月 5 日的运行、5 月6 日的运行等均属于独立的 JobInstance。若 5 月 5 日的运行首次失败后于次日重新运行,其仍属于 5 月 5 日的 JobInstance(通常该运行处理的是对应日期的数据,即 5 月 5 日的运行处理 5 月 5 日的数据)。由此可见,每个 JobInstance 可包含多次执行,且在指定时间点仅能运行一个 JobInstance(由特定 Job 及 JobParameters 标识)。
JobInstance 的定义与待加载数据无直接关联,数据加载方式完全由 ItemReader 的实现逻辑决定。以 “EndOfDay”Job 为例,数据中可能存在一列用于标识数据所属的生效日期(effective date)或调度日期(schedule date)。因此,5 月 5 日的作业运行仅加载 5 日数据,5 月 6 日的运行则仅处理 6 日数据 —— 这类数据加载逻辑本质上属于业务决策范畴,故由 ItemReader 负责实现。
spring 广告位
JobParameters(Job 参数)
在探讨 JobInstance 及其与 Job 的差异后,自然会引出一个问题:如何区分不同的 JobInstance? 答案在于JobParameters—— 该对象存储着批处理 Job 所需的参数集合,既可用作实例识别的唯一标识,也能在运行时作为参考数据,具体逻辑如下图示:
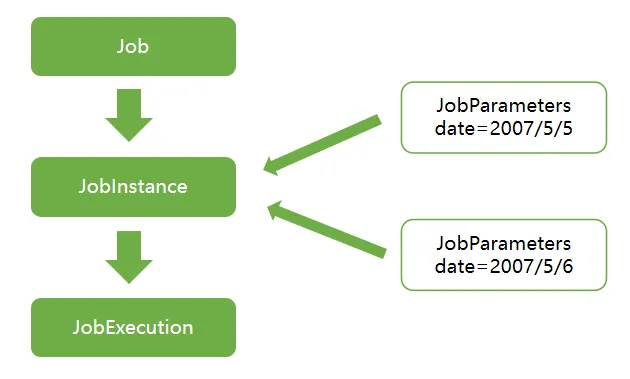
在前述示例中,存在两个实例(5 月 5 日与 5 月 6 日),本质上属于同一个 Job 的不同运行形态,其差异源于两个不同的 JobParameter 对象 —— 分别以 2007-05-05 和 2007-05-06 作为启动参数。
由此可明确:JobInstance = Job + 指定的JobParameters
这一机制赋予开发者灵活的控制权 —— 通过定义传入的参数组合,即可精准界定 JobInstance 的作用范围与识别逻辑。
注意:并非所有 Job 参数都需用于标识 JobInstance:
JobExecution(Job 执行)
JobExecution 是指运行单个 Job 的单次尝试这一技术概念。一次执行可能以失败或成功告终,但只有当执行成功完成时,对应的 JobInstance 才被视为完整。以上述“EndOfDay”Job 为例:假设 2007 年 5 月 5 日的 JobInstance 首次运行失败,若以相同的标识参数(2007-05-05)再次运行,将创建新的 JobExecution,但 JobInstance 仍保持唯一。
Job定义了作业本身及其执行逻辑,而JobInstance是纯粹的组织性对象,其核心作用是对作业执行进行分组,主要用于实现正确的重启语义。至于JobExecution,则是记录运行时实际操作的主要存储机制,其中包含诸多需控制和持久化的属性,具体如下表所示:
属性 | 说明 |
Status | 一个指示执行状态的 BatchStatus 对象。在运行时,它是 BatchStatus#STARTED。如果它失败了,它是 BatchStatus#FAILED。如果它成功完成,它是 BatchStatus#COMPLETED。 |
startTime | 一个 java.time.LocalDateTime,代表执行开始时的当前系统时间。如果 job 还没有开始,这个字段是空的。 |
endTime | 一个 java.time.LocalDateTime,代表执行结束时的当前系统时间,不管它是否成功。如果 job 还没有完成,该字段为空。 |
exitStatus | ExitStatus,表示运行的结果。它是最重要的,因为它包含一个返回给调用者的退出代码(exit code)。如果 job 还没有完成,该字段为空。 |
createTime | 一个 java.time.LocalDateTime,代表 JobExecution 第一次被持久化时的当前系统时间。job 可能还没有开始(因此没有开始时间),但它总是有一个 createTime,这是框架管理 job 级 ExecutionContexts 所需要的。 |
lastUpdated | 一个 java.time.LocalDateTime,代表 JobExecution 最后被持久化的时间。如果 job 还没有开始,这个字段是空的。 |
executionContext | 包含任何需要在 execution 之间持续存在的用户数据的 "属性包"。 |
failureExceptions | 在 Job 执行过程中遇到的异常情况的列表。如果在 Job 失败过程中遇到一个以上的异常,这些就很有用。 |
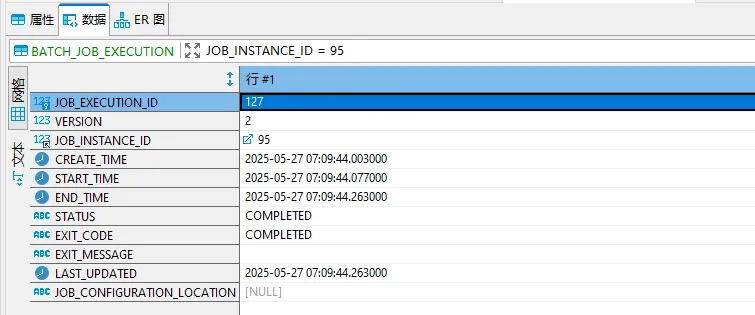
上述属性都非常重要,这些属性的值均将保存到数据库中。如下图:


Step(步骤)
Step(步骤)是作业的最小执行单元,包含完整的“读-处理-写”流程。
Step 作为领域对象,封装了批处理 Job 中独立且连续的执行阶段。每个 Job 均由一个或多个 Step 构成,而每个 Step 包含定义与控制实际批处理过程的全部必要信息。这一描述之所以具有抽象性,是因为具体 Step 的内容完全由 Job 开发者自主定义 —— 其复杂程度可随需求灵活调整:
与 Job 类似,每个 Step 对应唯一的 StepExecution,并与特定的 JobExecution 关联,具体逻辑如下图示:
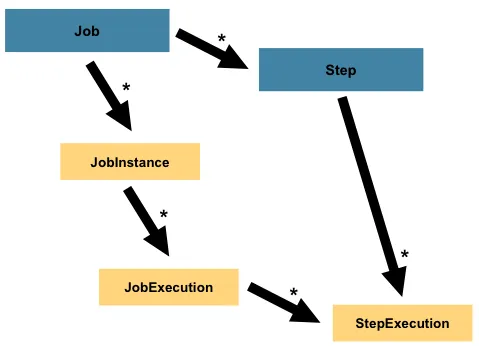
通常一个 Step 由三部分组成:
ItemReader:数据读取器
ItemProcessor:数据处理器(可选)
ItemWriter:数据写入器
Step 的特性:
通过 StepBuilderFactory 创建,支持唯一命名(如 step1)
支持分块处理(Chunk):每次读取 commit-interval 条记录,处理后批量写入
支持事务管理:每个 Chunk(分块)作为一个事务单元
什么是 Chunk?
简单说就是将数据分块读取、处理和写出。在 Spring Batch 中,Chunk 是实现批处理的核心模式,它将大量数据按固定大小分块处理,确保高效且可靠的数据处理。
Chunk 是一种 “读 - 处理 - 写” 循环模式,每次处理固定数量(commit-interval)的记录,作为一个事务单元。
核心流程如下:
读取 N 条记录 → 处理 N 条记录 → 写入 N 条记录 → 提交事务
StepExecution(步骤执行)
StepExecution 表示执行单个 Step 的单次尝试。与 JobExecution 类似,每次运行 Step 时都会创建新的 StepExecution。需注意:若某个 Step 因前置 Step 失败而未执行,则不会为其生成持久化的执行记录 —— 仅当 Step 实际启动时,才会创建 StepExecution。
Step 的执行状态由 StepExecution 类实例承载,每个实例包含以下关键信息:
StepExecution 的核心属性如下表所示:
属性 | 定义 |
Status | 一个指示执行状态的 BatchStatus 对象。在运行时,状态为 BatchStatus.STARTED。如果失败,状态为 BatchStatus.FAILED。如果它成功完成,状态是 BatchStatus.COMPLETED。 |
startTime | 一个 java.time.LocalDateTime,代表执行开始时的当前系统时间。如果该 step 尚未开始,该字段为空。 |
endTime | 一个 java.time.LocalDateTime,代表执行结束时的当前系统时间,无论是否成功。如果该 step 还没有退出,该字段为空。 |
exitStatus | ExitStatus 表示执行的结果。它是最重要的,因为它包含一个返回给调用者的退出代码(exit code)。更多细节见第5章。如果 job 还没有退出,这个字段是空的。 |
executionContext | 包含任何需要在 execution 之间持续存在的用户数据的 "属性包"。 |
readCount | 已经成功读取的 item 数量。 |
writeCount | 已成功写入的 item 数量。 |
commitCount | 本次 execution 中已提交的事务数量。 |
rollbackCount | 由该 Step 控制的业务事务被回滚的次数。 |
readSkipCount | read 失败的次数,导致跳过 item。 |
processSkipCount | process 失败的次数,导致跳过 item。 |
filterCount | 被 ItemProcessor "过滤" 过的项目的数量。 |
writeSkipCount | write 失败的次数,导致跳过 item。 |
spring 广告位
ExecutionContext(执行上下文)
ExecutionContext 本质上是一个键值对集合,由框架负责持久化管理,为开发者提供了可基于 StepExecution 或 JobExecution 作用域存储持久化状态的空间(熟悉 Quartz 的开发者可将其类比为 JobDataMap)。其核心应用场景是支持作业重启 —— 以平面文件输入为例:
在逐行处理数据时,框架会在提交点定期持久化 ExecutionContext。这使得 ItemReader 能存储当前状态(如已读取的行数),即便遭遇运行时致命错误或停电等突发情况,只需将关键状态存入上下文,框架即可在重启后基于该状态继续处理。具体逻辑如下例所示:
// LINES_READ_COUNT 表示读取行
// reader.getPosition() 当前的行位置
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
上述示例,将当前读取行数存入 ExecutionContext,框架自动处理后续持久化与重启逻辑。
JobRepository(作业仓库)
JobRepository 负责持久化(保存)批处理作业的元数据到数据库,确保作业状态可追溯、可恢复。为 JobLauncher、Job 和 Step 的实现提供增删改查(CRUD)操作。其中持久化的数据包括:
JobRepository 执行的具体逻辑如下:
JobRepository 的存储介质:
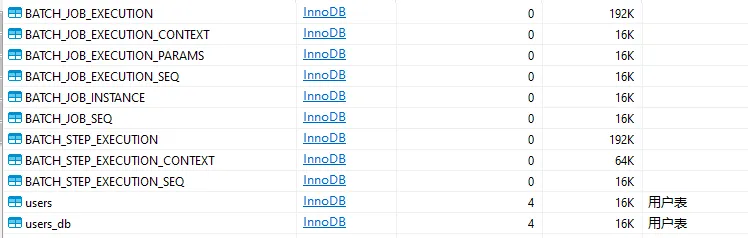
JobRepository 的作用:
故障恢复:重启作业时可从上次失败的位置继续执行。
作业监控:通过查询作业仓库获取历史执行记录。
幂等性保证:相同参数的作业实例不会重复启动。
注意:在 Java 配置场景中,通过 @EnableBatchProcessing 注解启用批处理时,框架会自动将 JobRepository 作为配置组件注入,无需手动创建。
JobLauncher(作业启动器)
JobLauncher 是一个简洁的接口,用于通过一组指定的 JobParameters 启动 Job,JobLauncher 定义如下:
public interface JobLauncher {
/**
* 为指定的 Job 和 JobParameters 启动一个作业执行实例。
* 若成功创建了 JobExecution,无论执行结果是否成功,本方法均会返回该实例。
* 若存在已暂停的历史 JobExecution,则返回该实例而非创建新实例。
* 仅当作业启动失败时抛出异常。若作业在处理过程中遇到错误,将返回 JobExecution 实例,需检查其状态获取详情。
*
* @param job 待执行的作业
* @param jobParameters 传递给此次作业执行的参数
* @return 同步执行时返回 JobExecution。若实现为异步模式,返回状态可能未知。
*
* @throws JobExecutionAlreadyRunningException 若由参数标识的 JobInstance 已有正在运行的执行实例
* @throws IllegalArgumentException 若 job 或 jobInstanceProperties 参数为 null
* @throws JobRestartException 若作业曾被执行且当前条件不允许重启
* @throws JobInstanceAlreadyCompleteException 若作业曾使用相同参数成功执行完毕
* @throws JobParametersInvalidException 若参数对该作业无效
*/
public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
简单示例:通过 JobLauncher 启动 Job 的典型用法,如下:
@RestController
@SpringBootApplication
@EnableBatchProcessing // 开启批处理
public class SpringBatchDemoApplication {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job jobLauncherDemoJob;
public static void main(String[] args) {
SpringApplication.run(SpringBatchDemoApplication.class, args);
}
@GetMapping("/runJob")
public void runJob(@RequestParam String message) throws Exception {
// 传递参数到任务
JobParameters jobParameters = new JobParametersBuilder()
.addString("message", message).toJobParameters();
// 执行任务
jobLauncher.run(jobLauncherDemoJob, jobParameters);
}
}
ItemReader(读取器)
ItemReader 是一个抽象概念,用于表示对 Step 输入数据的检索操作,以逐条(item-by-item)方式处理数据。当 ItemReader 无更多数据可提供时,会返回 null 作为结束标识。
Spring Batch 支持多种数据源:
关系型数据库(JDBC、JPA)
文件(CSV、XML、JSON)
消息队列(RabbitMQ、Kafka)
自定义数据源(如 REST API)
实现方式:
ItemProcessor(处理器,可选)
ItemProcessor 是一种抽象概念,用于表示数据项的业务处理逻辑。当 ItemReader 读取数据项、ItemWriter 写入数据项时,ItemProcessor 提供了数据转换或业务处理的接入点。若处理过程中判定数据项无效,可返回 null,表示该数据项不应被写出。
ItemProcessor 的特性:
示例场景:
数据格式转换(如字符串转日期)
数据校验(如过滤无效记录)
业务逻辑计算(如金额汇总)
ItemWriter(写入器)
ItemWriter 是一种抽象概念,用于表示 Step 的输出操作,以批量(batch)形式处理数据项。通常情况下,ItemWriter 不关心后续输入,仅处理当前调用中传入的数据项。
Spring Batch 的 ItemWriter 支持多种目标:
关系型数据库(JDBC、JPA)
文件(CSV、XML、JSON)
消息队列
REST API
ItemWriter 的特性:
spring 广告位
分块处理(Chunk Oriented Processing)
分块处理是 Spring Batch 核心特性之一,特别适合处理大量数据的场景。这种模式结合了事务管理和批处理的优势,既能高效处理数据,又能保证数据的完整性。
分块处理的核心思想:读 - 处理 - 写循环
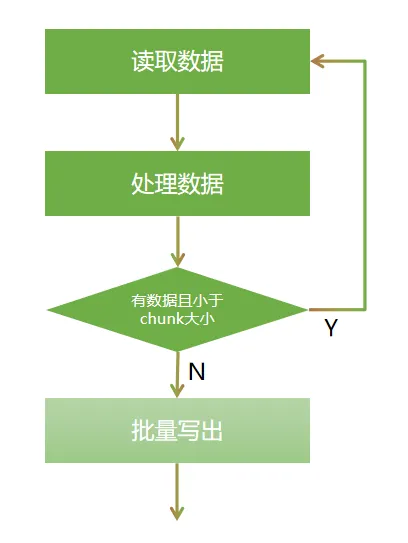
每次从数据源读取一条记录,处理后暂存,直到达到指定的块大小(chunk size),然后将整个块的数据一次性写入目标位置。
并且以块为单位提交事务,若处理过程中发生异常,仅当前块的数据会回滚,已处理的块不受影响。
Chunk 模式:
分块处理优势:
内存效率高:无需一次性加载所有数据。
事务安全:确保数据一致性。
故障恢复:可从失败的 Chunk 重新开始。
重试机制(RetryPolicy)
重试机制(RetryPolicy)用于处理临时性异常(如网络波动、数据库连接超时等),提高批处理作业的稳定性和成功率。通过合理配置重试策略,可以避免因偶发异常导致整个作业失败,而是自动重试直到成功或达到最大重试次数。
重试的常见实现:
跳过机制(SkipPolicy)
跳过机制允许在处理过程中遇到异常时跳过错误记录,继续处理后续数据,而不是让整个作业失败。这对于处理大量数据时的偶发错误特别有用,例如数据格式错误、无效记录等。
注意事项:
监听器(Listener)
监听器可以用来监听作业 / 步骤 / Chunk 的生命周期事件,实现自定义逻辑(如日志记录、统计)。
监听器类型:
监听器实现方式:
Spring Batch 的领域模型
作业实例(JobInstance)
由 JobName + JobParameters 唯一标识,代表一个逻辑上的批处理任务。例如:每月 1 日执行的 “工资计算” 作业是一个 JobInstance。
作业执行(JobExecution)
代表 JobInstance 的一次实际执行,记录执行状态(如 STARTED、FAILED)、开始 / 结束时间等。同一 JobInstance 可有多条 JobExecution 记录(如失败重试)。
步骤执行(StepExecution)
每个 Step 对应一个或多个 StepExecution,记录步骤的执行状态和进度。包含处理的记录数、跳过的记录数等统计信息。
注意: Spring Batch 的核心概念围绕 作业编排、数据处理、状态管理 和 执行控制 展开。通过合理使用这些概念,开发者可以构建出高效、可靠、可扩展的企业级批处理系统。关键是理解各组件间的协作关系,如 Job 与 Step 的组合、Reader/Processor/Writer 的数据流、JobRepository 的状态管理等。结合 Spring Boot 的自动化配置,Spring Batch 能显著提升批处理开发的效率和质量。

 川公网安备51010802032098
川公网安备51010802032098