前面介绍了从数据库和XML文件读取数据,下面将介绍如何使用 FlatFileItemReader 从普通文件中读取数据,如 CSV、固定格式文本这类文件。
FlatFileItemReader 是 Spring Batch4 中用于从平面文件(如 CSV、TXT、TSV 等)读取数据的核心组件。它逐行解析文件,并将记录映射为 Java 对象,适用于处理结构化文本数据。通过组合 LineTokenizer 和 FieldSetMapper 实现灵活的数据映射。结合容错机制和重启支持,可高效稳定地处理各类文本数据源。
FlatFileItemReader 特点
支持多种文件格式:它既可以处理分隔符分隔的文件(例如 CSV 文件),也能够处理固定长度格式的文件。
可配置的行映射:借助 LineMapper 接口,你能够把文件中的每一行数据映射成 Java 对象。
跳过错误记录:可以设置 setLinesToSkip(int) 来跳过文件开头的标题行,还能通过 setSkippedLinesCallback() 对跳过的行进行处理。
支持重启功能:该类实现了 ItemStream 接口,能够记录读取位置,从而支持作业的重启。
可自定义错误处理:可以通过 setStrict(boolean) 来控制在文件不存在或不可读时是否抛出异常。
其他核心组件
LineMapper 接口
该接口负责把读取到的文本行转换为批处理作业能够进一步处理的领域对象。LineMapper<T> 接口仅仅声明了一个方法:
public interface LineMapper<T> {
T mapLine(String line, int lineNumber) throws Exception;
}
参数说明:
LineTokenizer 接口
该接口用于将一行文本拆分成多个字段,常见的实现有 DelimitedLineTokenizer 和 FixedLengthTokenizer。接口定义如下:
public interface LineTokenizer {
FieldSet tokenize(@Nullable String line);
}
参数说明:
返回值:
FieldSetMapper 接口
该接口负责将拆分后的字段映射到 Java 对象的属性上。接口定义如下:
public interface FieldSetMapper<T> {
T mapFieldSet(FieldSet fieldSet) throws BindException;
}
参数:
返回值:
异常:
Resource 接口
该接口是访问底层资源(如文件、类路径资源、URL 资源等)的抽象层。它提供了统一的方式来读取和操作各种类型的资源,而无需关心资源的具体来源。一般使用 FileSystemResource 或者 ClassPathResource 来指定文件位置。
Resource 核心方法如下:
exists() 判断资源是否存在
isReadable() 判断资源是否可读
getInputStream() 获取资源的输入流
getURL() 返回资源的 URL 引用
getFile() 返回资源的 File 对象(若适用)
contentLength() 返回资源的内容长度(字节数)
lastModified() 返回资源的最后修改时间戳
getDescription() 返回资源的描述信息(用于日志和错误信息)
FlatFileItemReader 常用方法
setResource(Resource resource) 设置输入文件资源
setLineMapper(LineMapper<T> lineMapper) 设置行映射器,用于将行数据转换为 Java 对象
setLinesToSkip(int linesToSkip) 设置需要跳过的行数,通常用于跳过标题行
setSkippedLinesCallback(LineCallbackHandler skippedLinesCallback) 设置跳过行的回调处理器
setEncoding(String encoding) 设置文件编码,默认是 "UTF-8"
setStrict(boolean strict) 设置严格模式,若为 true,文件不存在时会抛出异常
setRecordSeparatorPolicy(RecordSeparatorPolicy recordSeparatorPolicy) 设置记录分隔策略,用于处理跨行记录
spring 广告位
简单示例
下面是一个读取 CSV 文件的示例:
准备工作
创建一个名为 users.csv 的文件,放在 resouces目录下,内容为:
"id","username","password"
1,张三,"13BC03AC29FAC7B29736EC3BE5C2F55A"
2,李四,"5E5994FBCFA922D804DF45295AE98604"
3,王五,"6C14DA109E294D1E8155BE8AA4B1CE8E"
4,赵六,"03774AD7979A5909E78F9C9DB3A2F0B2"
创建实体
创建名为 User 的实体类,代码如下:
package com.hxstrive.spring_batch.flatFileReaderDemo.dto;
import lombok.Data;
import lombok.ToString;
/**
* 用户DTO
* @author hxstrive.com
*/
@Data
@ToString
public class User {
private int id;
private String username;
private String password;
}
创建 BatchConfig 配置
创建 BatchConfig 配置类,如下:
package com.hxstrive.spring_batch.flatFileReaderDemo.config;
import com.hxstrive.spring_batch.flatFileReaderDemo.dto.User;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.support.MySqlPagingQueryProvider;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.validation.BindException;
import javax.sql.DataSource;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Spring Batch 配置类
* @author hxstrive.com
*/
@Configuration
public class BatchConfig {
// 用于创建和配置 Job 对象的工厂类
@Autowired
private JobBuilderFactory jobBuilderFactory;
// 用于创建和配置 Step 对象的工厂类
@Autowired
private StepBuilderFactory stepBuilderFactory;
// 创建Job对象
@Bean
public Job flatFileItemReaderDemoJob() {
return jobBuilderFactory.get("flatFileItemReaderDemoJob" + System.currentTimeMillis())
.start(flatFileItemReaderDemoStep())
.build();
}
// 创建Step对象
@Bean
public Step flatFileItemReaderDemoStep() {
return stepBuilderFactory.get("flatFileItemReaderDemoStep")
.<User, User>chunk(2)
.reader(flatFileItemReader())
.writer(new ItemWriter<User>() {
@Override
public void write(List<? extends User> list) throws Exception {
System.out.println(Arrays.toString(list.toArray()));
}
})
.build();
}
// 创建ItemReader对象,使用 FlatFileItemReader 实现从普通文件读取数据
@Bean
@StepScope //将 Bean 的生命周期与 Step 执行上下文 绑定
public FlatFileItemReader<? extends User> flatFileItemReader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("users.csv"));
reader.setLinesToSkip(1); // 跳过文件第一行,因为第一行是字段名
// 解析数据
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames("id", "username", "password");
// 把解析出的数据映射到 User 对象中
DefaultLineMapper<User> lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(new FieldSetMapper<User>(){
@Override
public User mapFieldSet(FieldSet fieldSet) throws BindException {
User user = new User();
user.setId(fieldSet.readInt("id"));
user.setUsername(fieldSet.readString("username"));
user.setPassword(fieldSet.readString("password"));
return user;
}
});
lineMapper.afterPropertiesSet();
reader.setLineMapper(lineMapper);
return reader;
}
}
上述代码,通过 FlatFileItemReader 从 users.cvs 文件读取数据。
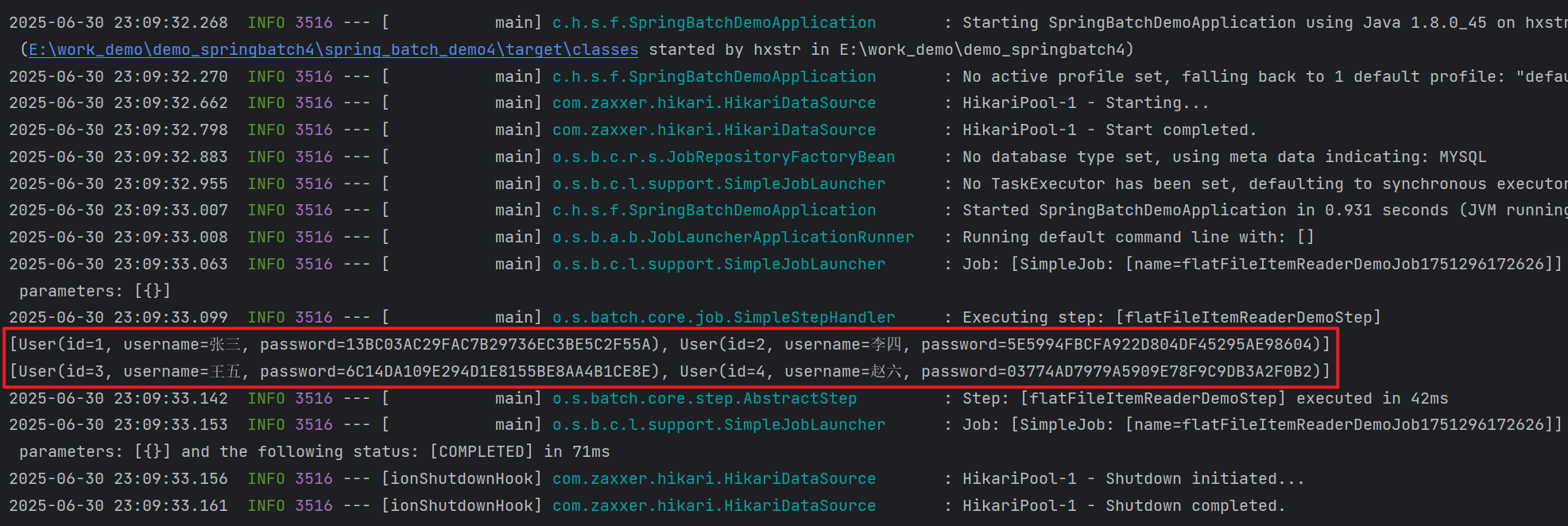
运行&验证
运行示例,观察输出日志,如下图:

 川公网安备51010802032098
川公网安备51010802032098