FlatFileItemWriter 是 Spring Batch 中用于将数据写入平面文件(如 CSV、TXT 等文本文件)的核心组件,实现了 ItemWriter 接口,专门处理批量数据到文本文件的输出操作。
在使用该类前,我们先简单看看它的源代码:
package org.springframework.batch.item.file;
import java.util.List;
import org.springframework.batch.item.file.transform.LineAggregator;
import org.springframework.batch.item.support.AbstractFileItemWriter;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import org.springframework.util.ClassUtils;
/**
* 平面文件项写入器,用于将数据项写入平面文件(如文本文件)
* 继承自AbstractFileItemWriter,泛型T表示要写入的数据的类型
*/
public class FlatFileItemWriter<T> extends AbstractFileItemWriter<T> {
/**
* 行聚合器,用于将数据项T转换为字符串行
* 负责将单个数据项转换为文件中对应的一行内容
*/
protected LineAggregator<T> lineAggregator;
/**
* 构造方法,初始化执行上下文名称
* 设置执行上下文名称为当前类的短名称(不包含包名)
*/
public FlatFileItemWriter() {
this.setExecutionContextName(ClassUtils.getShortName(FlatFileItemWriter.class));
}
/**
* 断言必要的属性(lineAggregator)已被设置
*
* 实现 InitializingBean 接口的方法,在 Bean 属性设置完成后调用
*
* @see org.springframework.beans.factory.InitializingBean#afterPropertiesSet()
*/
@Override
public void afterPropertiesSet() throws Exception {
// 确保lineAggregator 不为 null,否则抛出异常
Assert.notNull(lineAggregator, "A LineAggregator must be provided.");
// 如果是追加模式,则不应在文件存在时删除它
if (append) {
shouldDeleteIfExists = false;
}
}
/**
* LineAggregator 的公共设置方法
* 用于注入行聚合器,它将被用来将数据项转换为输出行
*
* @param lineAggregator 要设置的LineAggregator
*/
public void setLineAggregator(LineAggregator<T> lineAggregator) {
this.lineAggregator = lineAggregator;
}
/**
* 执行实际的写入操作,将数据项列表转换为字符串
* 重写父类方法,将多个数据项转换为对应的字符串行
*
* @param items 要写入的项列表
* @return 转换后的字符串,包含所有项对应的行,每行用行分隔符分隔
*/
@Override
public String doWrite(List<? extends T> items) {
// 用于构建所有行的字符串构建器
StringBuilder lines = new StringBuilder();
// 遍历所有数据项
for (T item : items) {
// 使用行聚合器将项转换为字符串,并添加行分隔符
lines.append(this.lineAggregator.aggregate(item)).append(this.lineSeparator);
}
// 返回构建好的字符串
return lines.toString();
}
}
spring 广告位
简单示例
该示例将从 csv 文件读取数据,然后利用 FlatFileItemWriter 将数据写入到磁盘的 txt 文件。
准备数据
在项目的 resources 目录下面创建名为 users.csv 的文件,内容如下:
"id","username","password"
1,张三,"13BC03AC29FAC7B29736EC3BE5C2F55A"
2,李四,"5E5994FBCFA922D804DF45295AE98604"
3,王五,"6C14DA109E294D1E8155BE8AA4B1CE8E"
4,赵六,"03774AD7979A5909E78F9C9DB3A2F0B2"
创建实体
创建一个简单的 POJO 用于映射 csv 读取的数据,如下:
package com.hxstrive.spring_batch.flatFileItemWriterDemo.dto;
import lombok.Data;
import lombok.ToString;
/**
* 用户DTO
* @author hxstrive.com
*/
@Data
@ToString
public class User {
private int id;
private String username;
private String password;
}
创建配置类
使用 @Configuration 注解创建配置类,配置 Spring Batch 的 Job、Step、ItemReader 和 ItemWriter,代码如下:
package com.hxstrive.spring_batch.flatFileItemWriterDemo.config;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.hxstrive.spring_batch.flatFileItemWriterDemo.dto.User;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.batch.item.file.transform.LineAggregator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.FileSystemResource;
import org.springframework.validation.BindException;
import javax.sql.DataSource;
/**
* Spring Batch 配置类
* @author hxstrive.com
*/
@Configuration
public class BatchConfig {
// 用于创建和配置 Job 对象的工厂类
@Autowired
private JobBuilderFactory jobBuilderFactory;
// 用于创建和配置 Step 对象的工厂类
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private DataSource dataSource;
// 创建Job对象
@Bean
public Job flatFileItemWriterDemoJob() {
return jobBuilderFactory.get("flatFileItemWriterDemoJob-" + System.currentTimeMillis())
.start(flatFileItemWriterDemoStep())
.build();
}
// 创建Step对象
@Bean
public Step flatFileItemWriterDemoStep() {
return stepBuilderFactory.get("flatFileItemWriterDemoStep")
.<User, User>chunk(2)
.reader(flatFileItemReader())
.writer(flatFileItemWriter())
.build();
}
// 创建ItemReader对象,从 users.csv 文件读取数据
@Bean
@StepScope //将 Bean 的生命周期与 Step 执行上下文 绑定
public FlatFileItemReader<? extends User> flatFileItemReader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("users.csv"));
reader.setLinesToSkip(1); // 跳过文件第一行,因为第一行是字段名
// 解析数据
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames("id", "username", "password");
// 把解析出的数据映射到 User 对象中
DefaultLineMapper<User> lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(new FieldSetMapper<User>(){
@Override
public User mapFieldSet(FieldSet fieldSet) throws BindException {
User user = new User();
user.setId(fieldSet.readInt("id"));
user.setUsername(fieldSet.readString("username"));
user.setPassword(fieldSet.readString("password"));
System.out.println("reading user: " + user);
return user;
}
});
lineMapper.afterPropertiesSet();
reader.setLineMapper(lineMapper);
return reader;
}
// 创建ItemWriter对象,将读取的数据写入到 F:\customer.txt 文件
@Bean
public ItemWriter<? super User> flatFileItemWriter() {
System.out.println("flatFileItemWriter()");
FlatFileItemWriter<User> writer = new FlatFileItemWriter<>();
String path = "F:\\customer.txt";
writer.setResource(new FileSystemResource(path));
//把User对象转换成字符串输出到文件
writer.setLineAggregator(new LineAggregator<User>() {
ObjectMapper mapper = new ObjectMapper();
@Override
public String aggregate(User item) {
String str = null;
try {
str = mapper.writeValueAsString(item);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
return str;
}
});
return writer;
}
}
上述代码,重点关注 flatFileItemWriter() 方法,它使用 FlatFileItemWriter 将 User 类型的数据写入到文本文件中,具体如下:
1、创建 FlatFileItemWriter 实例
FlatFileItemWriter<User> writer = new FlatFileItemWriter<>();
创建了一个专门处理 User 类型的平面文件写入器。
2、设置输出文件路径
String path = "F:\\customer.txt";
writer.setResource(new FileSystemResource(path));
指定输出文件为本地文件系统中的 F:\\customer.txt,所有数据将写入该文件。
3、配置行聚合器(核心逻辑)
writer.setLineAggregator(new LineAggregator<User>() {
ObjectMapper mapper = new ObjectMapper(); // Jackson库的JSON处理对象
@Override
public String aggregate(User item) {
String str = null;
try {
// 将User对象序列化为JSON字符串
str = mapper.writeValueAsString(item);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
return str; // 返回JSON字符串作为文件中的一行
}
});
上述代码,自定义了 LineAggregator 接口的实现,用于将 User 对象转换为字符串。这里使用 Jackson 库的 ObjectMapper 将 User 对象序列化为 JSON 格式字符串,每个 User 对象会被转换为一行 JSON 文本写入文件。
创建启动类
这里没有什么新东西,仅仅在 Spring Boot 启动类上多添加 @EnableBatchProcessing 注解,开启批处理功能。代码如下:
package com.hxstrive.spring_batch.flatFileItemWriterDemo;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@EnableBatchProcessing // 开启批处理
public class SpringBatchDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBatchDemoApplication.class, args);
}
}
运行程序,输出日志如下图:
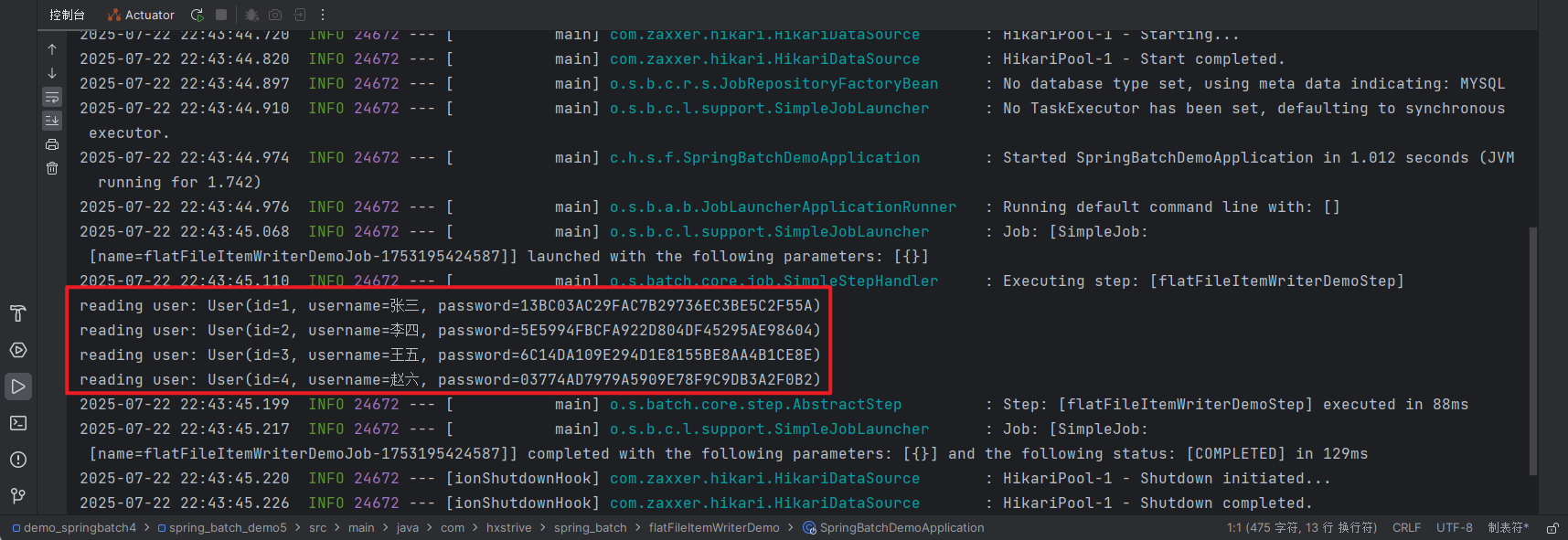
成功从 csv 文件读取到数据。
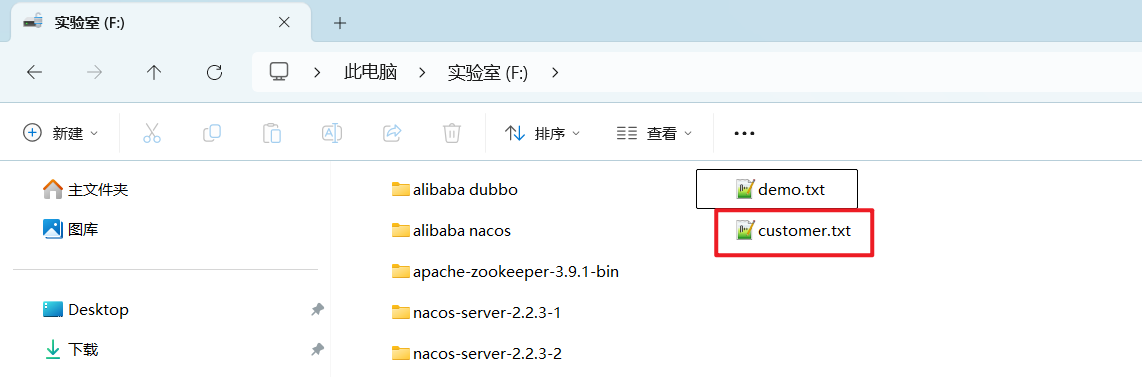
继续查看 F:/ 盘,是否多了 customer.txt 文件,如下图:
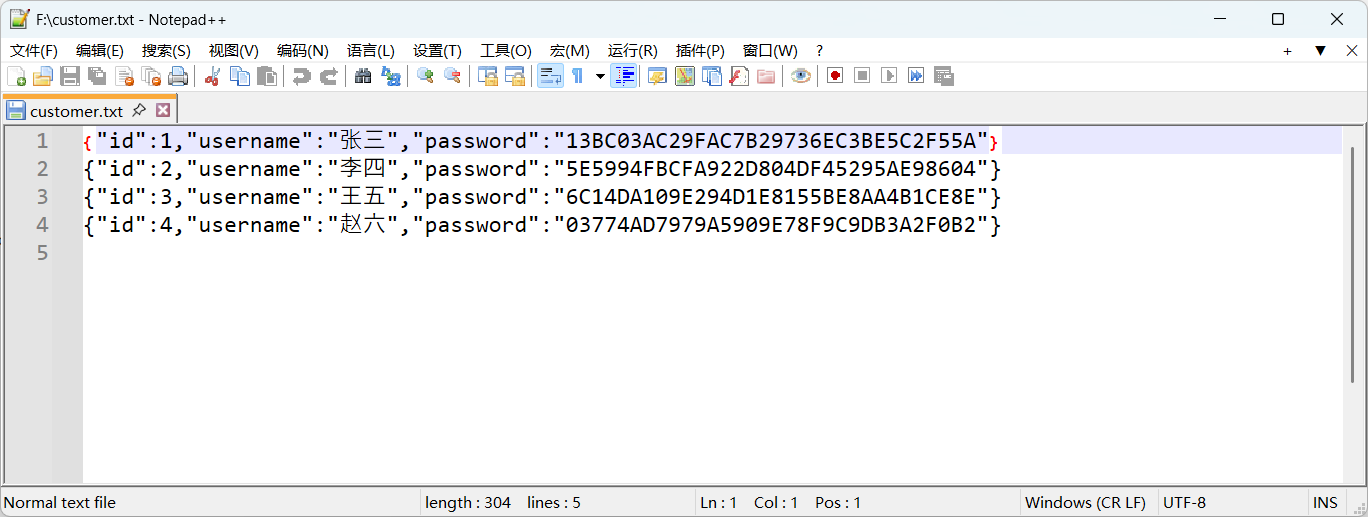
打开 customer.txt 文件,查看内容,如下图:
更多关于 FlatFileItemWriter 的用法,请参考官方文档。

 川公网安备51010802032098
川公网安备51010802032098