前面 Spring Batch4 搭建项目 章节,我们使用 H2 内存数据库来保存 Spring Batch 运行时的 Job 和 Step 等信息。但是,在实际开发中 H2 保存的数据存在下面缺点:
(1)数据持久性与可靠性不足:H2 默认以内存模式运行,应用重启后所有作业元数据(如作业状态、步骤进度、重试记录)会丢失,导致批处理任务无法恢复或追踪历史状态。如果启用 H2 的持久化(写入磁盘),需额外配置数据库文件路径,且数据一致性和事务可靠性仍弱于专业数据库(如 MySQL / PostgreSQL)。
(2)性能瓶颈与大数据量限制:H2 作为嵌入式数据库,缺乏分布式架构支持,当批处理数据量庞大(如百万级记录)或作业复杂度高时,易出现查询性能下降、锁竞争等问题。而且 H2 的索引机制和 SQL 优化能力较弱,复杂的作业元数据查询(如按状态统计作业、追踪失败步骤)可能导致响应缓慢。
(3)生产环境运维能力缺失:H2 不支持主流数据库的监控工具(如 Prometheus、Grafana)、备份恢复机制(如热备、增量备份),难以满足生产环境的运维需求。Spring Batch 的分布式作业(如多节点并行处理)需要数据库支持锁机制和分布式事务,H2 在高并发场景下易出现数据不一致或作业冲突。
(4)功能特性与兼容性局限:H2 不支持分区表、存储过程、复杂函数等功能,无法满足批处理中可能需要的自定义数据处理逻辑。与 ETL 工具、数据可视化平台的集成支持较差,若批处理系统需与其他组件联动,H2 可能成为集成瓶颈。
(5)稳定性风险:H2 的不同版本可能存在元数据模式变更,导致 Spring Batch 作业升级时出现兼容性错误(如 DDL 语句不兼容)。在网络波动、磁盘空间不足等异常情况下,H2 的容错能力较弱,可能导致作业中断且难以恢复。
基于上述原因,我们不得不放弃 H2 数据库,采用更专业的数据库来存放 Spring Batch 的作业数据(但是,如果仅仅是为了一些简单示例,使用 H2 也未尝不可)。
本章下面将介绍如何实现 Spring Batch + MySQL,详细步骤如下:
添加 Maven 依赖
由于要使用 MySQL,因此我们需要引入 MySQL 的 JDBC 驱动,以及 Spring 相关依赖,如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
编辑 application.properties 配置
由于要使用 MySQL 存放 Spring Batch 业务数据,因此需要配置数据源,如下:
spring.application.name=spring_batch_demo
# 数据源配置
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/spring_batch4?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
spring.datasource.username=root
spring.datasource.password=aaaaaa
#spring.batch.jdbc.schema=classpath:org/springframework/batch/core/schema-@@platform@@.sql
spring.batch.jdbc.platform=mysql
spring.batch.jdbc.initialize-schema=always
上述配置说明:
spring.batch.jdbc.schema 指定 Spring Batch 元数据表格的 SQL 脚本路径。注意,@@platform@@ 是一个占位符,会依据 spring.batch.jdbc.platform 的值动态替换,这样就能适配不同的数据库类型。示例:当 platform=mysql 时,实际使用的脚本是 schema-mysql.sql。
spring.batch.jdbc.platform 明确数据库类型,此值会替换 schema 路径中的 @@platform@@ 占位符。常见取值:mysql、oracle、postgres、hsqldb 等。保证 SQL 脚本里的语法和特定数据库相契合,比如 MySQL 使用 AUTO_INCREMENT,而 PostgreSQL 使用 SERIAL。
spring.batch.jdbc.initialize-schema 控制是否自动初始化 Batch 元数据表格。可选值如下:
always:不管数据库状态如何,每次应用启动时都会执行初始化脚本。
embedded:只有在使用嵌入式数据库(像 H2、HSQLDB)时才会初始化。
never:不会自动初始化表格,需要手动执行 SQL 脚本。
注意,下图是 Spring Batch 元数据表格的 SQL 脚本路径:
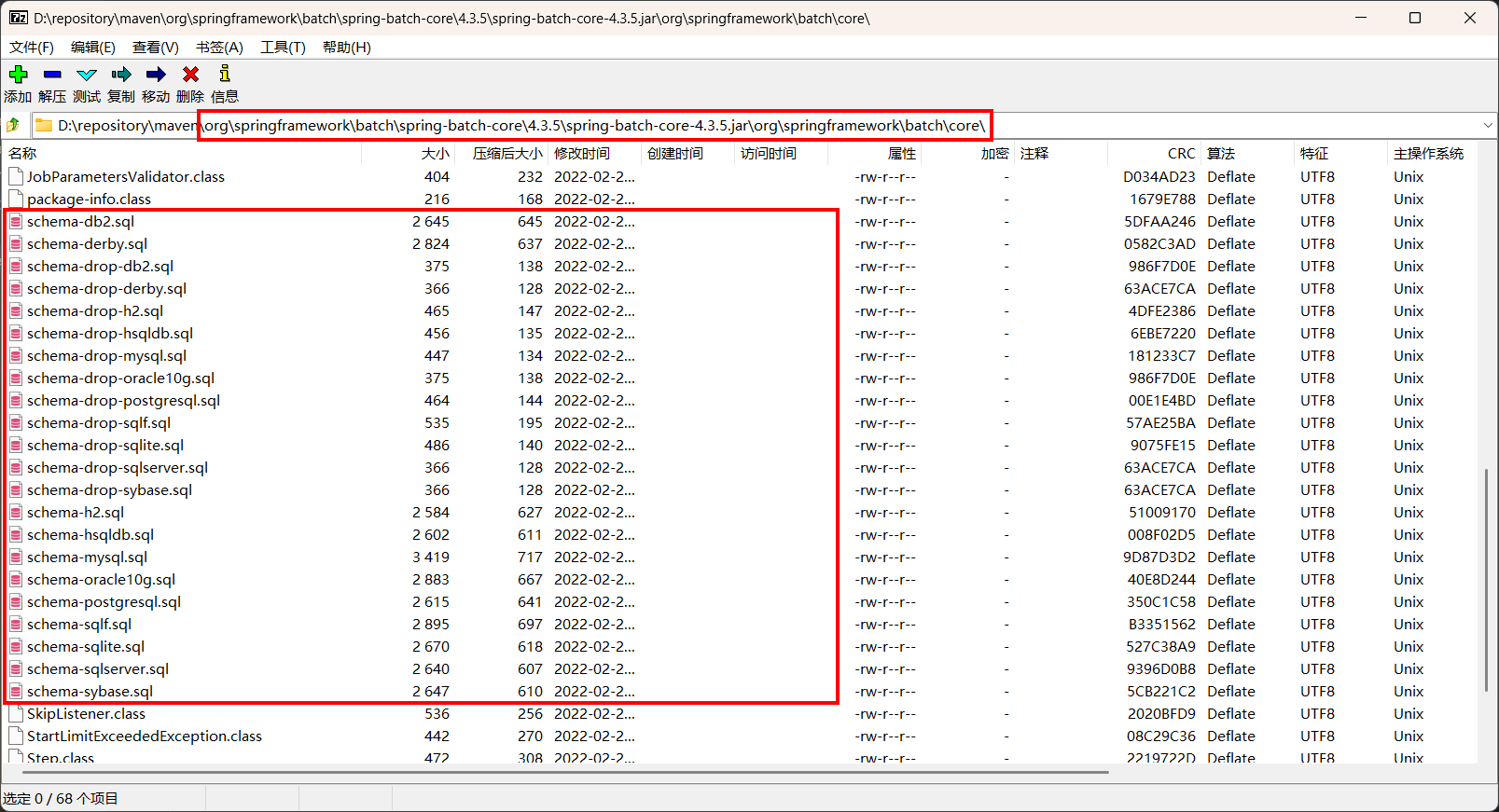
spring 广告位
添加 BatchConfig 配置
创建一个新到 BatchConfig 配置类,该类和 Spring Batch4 搭建项目 中的 BatchConfig 类一致,如下:
package com.hxstrive.spring_batch.config;
import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Spring Batch 配置类
* @author hxstrive.com
*/
@Configuration
public class BatchConfig {
// 用于创建和配置 Job 对象的工厂类
@Autowired
private JobBuilderFactory jobBuilderFactory;
// 用于创建和配置 Step 对象的工厂类
@Autowired
private StepBuilderFactory stepBuilderFactory;
// 创建一个名为 helloJob 的任务
@Bean
public Job helloJob() {
return jobBuilderFactory.get("helloJob")
// 配置任务要执行的步骤
.start(helloStep())
.build();
}
// 创建一个名为 helloStep 的步骤
@Bean
public Step helloStep() {
return stepBuilderFactory.get("helloStep").tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
System.out.println("hello world");
return RepeatStatus.FINISHED; // 返回 FINISHED 表明任务执行结束
}
}).build();
}
}
创建启动类
和 Spring Batch4 搭建项目 章节的启动类一样,仅仅在普通 Spring Boot 启动类上添加了 @EnableBatchProcessing 注解,如下:
package com.hxstrive.spring_batch;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 使用 mysql 数据库来保存批处理状态信息
* @author hxstrive.com
*/
@SpringBootApplication
@EnableBatchProcessing // 开启批处理
public class SpringBatchDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBatchDemoApplication.class, args);
}
}
创建数据库
在正式启动项目时,需要先创建 spring_batch4 数据库,如下图:
运行&验证
运行项目,仔细观察输出日志:
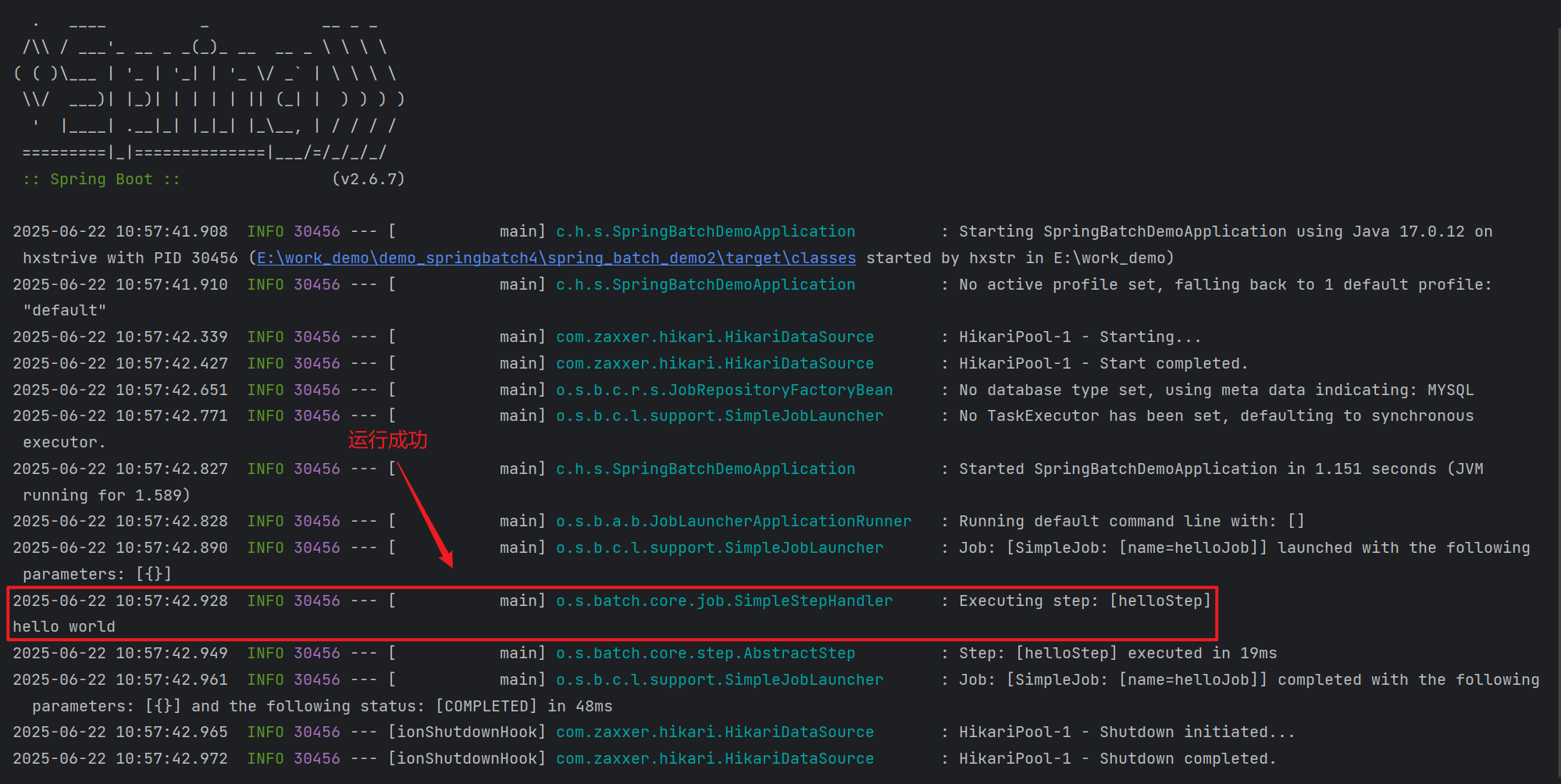
通过上述输出信息,名为“helloJob”的任务执行成功了。
观察数据
既然执行 Job 任务成功了,我们可以连接到数据库中查看 Spring Batch 到底给我们创建了那些数据库表?
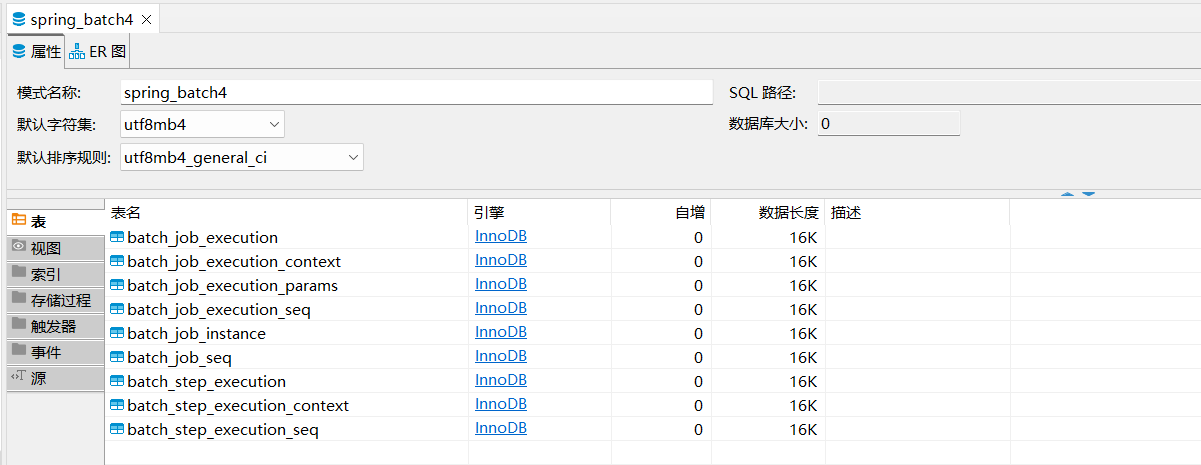
下面将对上述表格进行简单介绍:
作业实例(Job Instance)
作业执行(Job Execution)
batch_job_execution 记录作业每次运行的状态和元数据,一个 JOB_INSTANCE 可对应多次执行(如失败重试)。
batch_job_execution_params 存储作业执行时的参数(如日期范围、文件路径)。
batch_job_execution_context 存储作业执行时的上下文信息(如计数器、临时结果),支持跨步骤共享数据。
batch_job_execution_seq 为 batch_job_execution 的主键生成器提供支持。
步骤执行(Step Execution)
batch_step_execution 记录作业中每个步骤的执行状态,一个 JOB_EXECUTION 包含多个步骤。
batch_step_execution_context 存储步骤执行时的上下文信息(如当前处理的记录 ID、分页偏移量)。
batch_step_execution_seq 为 batch_step_execution 的主键生成器提供支持。
spring 广告位
数据表字段说明
batch_job_instance 表
job_instance_id 作业实例的唯一标识,自增 id。spring batch 通过序列表(如batch_job_seq)生成该值。关联其他表(如 batch_job_execution),确保作业实例的唯一性。
version 乐观锁版本号,用于并发控制。每次更新记录时自动递增。防止多线程同时修改同一作业实例导致的数据不一致。
job_name 作业的逻辑名称(如dailyreportjob),对应代码中的job bean 名称。区分不同类型的作业(如数据导入、报表生成)。
job_key 作业参数的 md5 哈希值,用于标识同一作业的不同参数实例。确保相同参数的作业不会重复创建实例(通过唯一索引job_inst_un约束)。
batch_job_seq 表
batch_job_execution 表
job_execution_id 作业执行的唯一标识符,通过序列表(如 batch_job_execution_seq)生成。关联其他表(如 batch_step_execution),标识一次具体的作业运行。
version 乐观锁版本号,用于并发控制。每次更新记录时自动递增。防止多线程同时修改同一执行实例导致的数据不一致。
job_instance_id 关联的作业实例 id,表示该执行属于哪个逻辑作业。通过外键关系建立作业实例与执行之间的父子关系。
create_time 作业执行记录创建时间(通常为作业启动前)。记录作业执行的创建时间戳,用于排序和审计。
start_time 作业实际开始执行的时间。计算作业执行耗时(end_time-start_time)。
end_time 作业完成(成功/失败)的时间。计算作业执行耗时,判断作业是否已结束。
status 作业执行状态,实时监控作业状态,支持断点恢复。常见值:
starting:正在启动
started:已启动
completed:成功完成
failed:失败
stopping:正在停止
stopped:已停止
exit_code 作业退出码,通常为completed、failed或自定义错误码。程序判断作业执行结果,支持条件跳转(如失败后重试)。
exit_message 作业退出详细信息(如异常堆栈、错误原因)。排查作业失败原因,记录关键执行信息。
last_updated 记录最后更新时间,用于跟踪作业执行进度。监控长时间运行的作业是否处于活跃状态。
job_configuration_location 作业配置文件的位置(如xml配置路径或类名)。记录作业定义来源,支持动态加载配置。
batch_job_execution_context 表
job_execution_id 关联的作业执行 id,确保每个作业执行仅有一个上下文记录,唯一标识作业执行的上下文。
short_context 序列化的上下文数据,通常为轻量级键值对(如计数器、标志位),快速存储和读取常用上下文信息。
serialized_context 完整的上下文数据,用于存储复杂对象(如集合、自定义 java 对象),存储需要长期保留的详细上下文信息。
batch_job_execution_params 表
job_execution_id 业执行 id,标识参数属于哪次作业运行,建立参数与作业执行之间的关联。
type_cd 参数的数据类型,指示参数值存储在哪个字段中。固定取值:
string 字符串
date 日期
long 整形
double 浮点型
key_name 参数名称(如inputfilepath、processdate),唯一标识参数的键。
string_val e_cd为string时,存储参数的字符串值。
date_val 当type_cd为date时,存储参数的日期时间值。
long_val 当type_cd为long时,存储参数的长整数值。
double_val 当type_cd为double时,存储参数的双精度浮点数值。
identifying 标识参数是否影响作业实例的唯一性,控制参数是否作为作业实例的区分依据。取值:
batch_job_execution_seq 表
batch_step_execution 表
step_execution_id 步骤执行的唯一标识符,通过序列表生成。
version 乐观锁版本号,确保并发环境下数据一致性。
step_name 称(如readdatastep、processdatastep)。
job_execution_id 关联的作业执行 id,建立步骤与作业的父子关系。
start_time / end_time 步骤开始 / 结束时间,用于计算执行耗时。
exit_code / exit_message 步骤退出码和详细信息(如异常堆栈)。
last_updated 记录最后更新时间,用于监控长时间运行的步骤。
batch_step_execution_context 表
step_execution_id id 确保每个步骤执行仅有一个上下文记录。唯一标识步骤执行的上下文。
short_context 序列化的轻量级上下文数据,通常为基本类型键值对(如计数器、标志位)。快速存储常用上下文信息,避免大字段 io 开销。存储格式:json 或 xml 字符串(取决于序列化器配置)。
serialized_context 完整的上下文数据,用于存储复杂对象(如集合、自定义 java 对象)。存储需要长期保留的详细上下文信息。存储格式:java 序列化字节流或 json/xml(取决于配置)。
batch_step_execution_seq 表
上面介绍了 Spring Batch 如何使用 MySQL 存储数据,以及 Spring Batch 创建的数据表各个字段的含义,后续将介绍更多关于 Spring Batch 知识……

 川公网安备51010802032098
川公网安备51010802032098