前面学完 XML 你应该有感觉了 —— XML 本身很自由,标签想叫什么叫什么,想怎么嵌套怎么嵌套。但自由过头了也麻烦:你写一套标签,我写一套标签,两边数据一对,发现根本对不上。这时候就需要有人站出来定个规矩,告诉大家 "这个 XML 文件到底长什么样、能写哪些标签、什么顺序、哪些必填哪些可选"。
这个 "立规矩" 的工具就是 DTD。
一个容易搞混的概念
学 DTD 之前,先理清两个词的区别,不然后面很容易绕进去:
打个比方:格式良好相当于你写了篇文章没有错别字,有效相当于这篇文章还严格符合出版社的排版规范。DTD 干的就是这个 "规范校验" 的活。
DTD 是什么
DTD 全称叫文档类型定义(Document Type Definition),说白了就是一份 XML 的格式说明书。你把 XML 当成自由书写的文本,那 DTD 就是那本格式规范手册,专门规定:
允许出现哪些标签
标签之间怎么嵌套、什么顺序
每个标签里面能放什么内容(子标签还是纯文本)
标签可以带哪些属性、属性值什么类型、是不是必填
下面来一个示例,直观了解 DTD 怎么编写,以及如何验证 XML。
简单示例
编写一个简单的 DTD
一个名为 student.dtd 的 DTD 文件。
<!ELEMENT student (name, age, major, email)>
<!ATTLIST student id ID #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT major (#PCDATA)>
<!ELEMENT email (#PCDATA)>
详细介绍:
第 1 行:<!ELEMENT student (name, age, major, email)> 这行声明了根标签 student ,括号里的内容规定了它的子标签必须严格按照 name → age → major → email 这个顺序出现,一个不能多,一个不能少。顺序乱了或者缺了哪个,校验直接不通过。
第 2 行:<!ATTLIST student id ID #REQUIRED> 这行给 student 标签配了一个属性 id。ID 表示这个属性的值在整个 XML 里必须唯一,不能跟其他标签的 ID 重复。#REQUIRE 表示这个属性是必填的,不写就报错。
这里可以展开说一下属性类型的常见取值:
第 3 行:<!ELEMENT name (#PCDATA)>声明 name标签的内容是普通文本(#PCDATA),里面不能再嵌套子标签。也就是说 <name>张三 </name>这样写是对的,如果写成 <name><first>张</first><last>三</last></name>就不行,因为 DTD 规定了它只能装文本。
第 4 行:<!ELEMENT age (#PCDATA)>和第 3 行同理,age 标签里只能放文本。DTD 本身没法约束 "这个文本必须是数字",它只关心内容类型是 #PCDATA 还是子标签。要做数据类型校验得用 XML Schema。
第 5 行:<!ELEMENT major (#PCDATA)> 同上,major 标签只允许文本内容。
第 6 行:<!ELEMENT email (#PCDATA)> 同上,email 标签也只能放文本。
使用 DTD 规范 XML
接下来,根据上面提供的 DTD 编写符合其规范的 XML 文档,推荐使用 VS CODE 进行编写,默认 VS CODE 可以实时验证 XML 是否符合 DTD 规范,不符合会给出红色的波浪线下划线。
在开始编写之前,检查 VS CODE 是否安装了如下插件:
如果没有安装,快去安装吧。
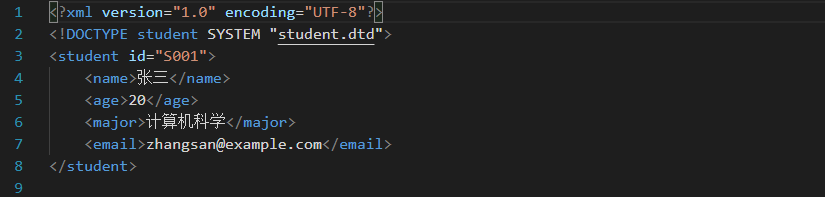
创建 student.xml 文件,保持和 student.dtd 在同一个目录,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE student SYSTEM "student.dtd">
<student id="S001">
<name>张三</name>
<age>20</age>
<major>计算机科学</major>
<email>zhangsan@example.com</email>
</student>
此时,VS CODE 没有报错,说明格式是有效的:
如果将根标签改为 student1,立即会出现错误,如下图:
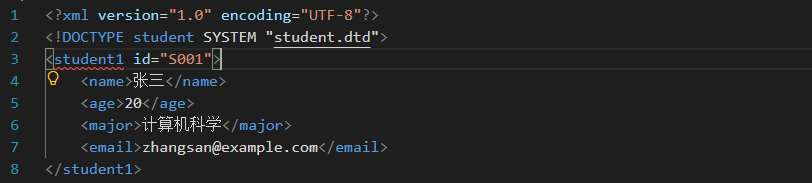
将鼠标移动到红色波浪线,会展示详细错误信息,如下图:

Python广告
<!DOCTYPE> 标签
如果仔细观察上面的 student.xml 文档,存在一行为 <!DOCTYPE student SYSTEM "student.dtd"> 的语句,这是 DTD 验证的关键 —— 它告诉解析器:这份 XML 的约束规则在外部文件 student.dtd 里,而且根标签是 student。解析器拿到 XML 之后会去读这份 DTD,然后按里面的规则逐项校验。
<!DOCTYPE> 必须写在 XML 声明之后、根标签之前,格式固定:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 根标签名 SYSTEM "DTD文件路径">
<根标签名>
...
</根标签名>
SYSTEM 是关键字,表示 DTD 文件在本地或通过 URL 路径指定。整行声明的意思就是:"这份 XML 的根标签是某某,校验规则去某某文件里找。"
引用外部 DTD 文件
把规则单独存成一个 .dtd 文件,XML 通过 DOCTYPE 声明引用它。这样多个 XML 文件可以共用同一份 DTD 规范,改规则也只需要改一处。团队协作或者项目规范化管理的时候,这种方式明显更合适。
DTD 可以是本地文件,也可以是互联网上。
引用本地文件,如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE student SYSTEM "student.dtd">
<student id="S001">
<name>张三</name>
</student>
SYSTEM "student.dtd" 表示 DTD 文件叫 student.dtd,和 XML 放在同一个目录下。如果 DTD 在别的路径,直接写相对路径或绝对路径就行,比如 SYSTEM "../dtd/student.dtd"。
也可以引用网络上公开的 DTD:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
这种写法里 PUBLIC 替代了 SYSTEM,多了一个公共标识符(那个长字符串),后面跟的才是 DTD 的实际地址。一般只有引用行业标准 DTD 时才会用 PUBLIC,日常自己写 DTD 用 SYSTEM 就够了。
内部 DTD,直接写在 XML 里
直接把规则写在 XML 文档的 DOCTYPE 声明里,适合那种独立的、不需要共享的小型 XML 文件。好处是简单,一个文件搞定所有,不用额外维护。缺点是每个 XML 都得抄一份规则,多个文件之间没法共用。
如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE student [
<!ELEMENT student (name, age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ATTLIST student id ID #REQUIRED>
]>
<student id="S001">
<name>张三</name>
<age>20</age>
</student>
使用方括号 [] 把 DTD 规则直接包在 <!DOCTYPE> 声明里面。解析器不再去找外部文件,直接在 XML 内部就能读到约束规则。这样做的好处是简单自包含,一个文件搞定;缺点是没法给别的 XML 复用,稍微大点的项目不推荐这么写。
DTD 到底有什么用
统一数据标准
多人协作或者系统之间传 XML 数据的时候,最怕的就是各写各的。你管用户叫 <user> ,他管用户叫 <account>,标签一多根本对不上号。有了 DTD,所有人按同一份规则写,标签名、嵌套结构都是约定好的,谁也别乱来。
自动校验数据合法性
程序可以拿着 DTD 当尺子,收到的 XML 往上一量,不合规的直接拦下来。比如少了一个必填标签、多了不该出现的节点、属性值类型写错了,校验器会自动报错,不用人工一个个检查。
减少重复编写
DTD 里可以定义 "实体",相当于自定义常量。比如某个固定文案或者特殊字符要在 XML 里反复出现,定义一个实体,后面用 &实体名; 直接引用就行,不用每次手敲。
核心语法
DTD 的语法其实就三大块,弄懂这三个基本就懂了。
ELEMENT:声明标签
ELEMENT用来告诉 DTD "这个 XML 里允许有哪些标签",以及每个标签里面能装什么。
例如:
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT major (#PCDATA)>
<!ELEMENT email (#PCDATA)>
ATTLIST:声明属性
ATTLIST用来限定某个标签能带哪些属性。你可以规定属性的值是什么类型(文本、枚举、ID 等),这个属性是必须写还是可选的,如果不写默认值是什么。
比如给 <student>标签配一个 id属性,规定它是必填的,而且值必须是唯一的,那每个学生的 ID 就不能重复也不能省略。
<!ATTLIST student id ID #REQUIRED>
ENTITY:声明实体
ENTITY 就是自定义常量。把一段经常重复出现的文本或特殊符号定义成一个实体名,XML 里面用 &实体名; 就能直接引用。
比较经典的用法是定义特殊字符的实体,避免和 XML 的语法符号冲突。也常用来管理固定的版权声明、公司名称这类反复出现的文本。
例如,student.dtd 内容如下:
<!ENTITY school_name "XX大学">
<!ENTITY version "v3.2.1">
<!ENTITY copyright "版权所有 © 2024 XX大学 保留所有权利">
<!ELEMENT student (name, age, major, footer)>
<!ATTLIST student id ID #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT major (#PCDATA)>
<!ELEMENT footer (#PCDATA)>
student.xml 内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE student SYSTEM "student.dtd">
<student id="S001">
<name>张三</name>
<age>20</age>
<major>计算机科学 &school_name; &version;</major>
<footer>©right;</footer>
</student>
上面 XML 中,析后 &school_name; 变成“ XX大学”,&version; 变成 “v3.2.1”,©right; 变成 “版权所有 © 2024 XX大学 保留所有权利”。改一处 DTD,所有引用的地方自动生效。
适用场景和局限
DTD 是 XML 生态里最早的那套约束标准,优点是语法简洁、上手快,写几个声明就能用。对于简单配置文件、小规模数据交互来说完全够用。
但它也有明显的短板:
所以在企业级的复杂规范场景中,现在更多用 XML Schema 来代替 DTD。XML Schema 支持丰富的数据类型、命名空间、更精细的结构约束,能力上确实比 DTD 强一大截。
不过话说回来,DTD 依然值得学。一来很多老项目的配置文件、传统系统里的 XML 还在用 DTD;二来它的概念是 XML Schema 的基础,把 DTD 搞懂了再学 Schema 会轻松很多。
一句话:XML 教你写数据,DTD 教你写对数据。

 川公网安备51010802032098
川公网安备51010802032098