在 SQL 数据分析中,分组查询(GROUP BY) 是核心技能之一。它能将数据按照指定字段归类,结合聚合函数(COUNT、SUM、AVG 等)实现 “按类别统计”,比如统计各部门人数、各商品销售额、不同性别用户数等。本文将从基础到进阶,全面讲解分组数据的使用方法、常见坑点和最佳实践。
什么是数据分组
数据分组的本质是 “分类汇总”:将数据表中具有相同特征的行归为一组,然后对每组数据执行聚合计算。
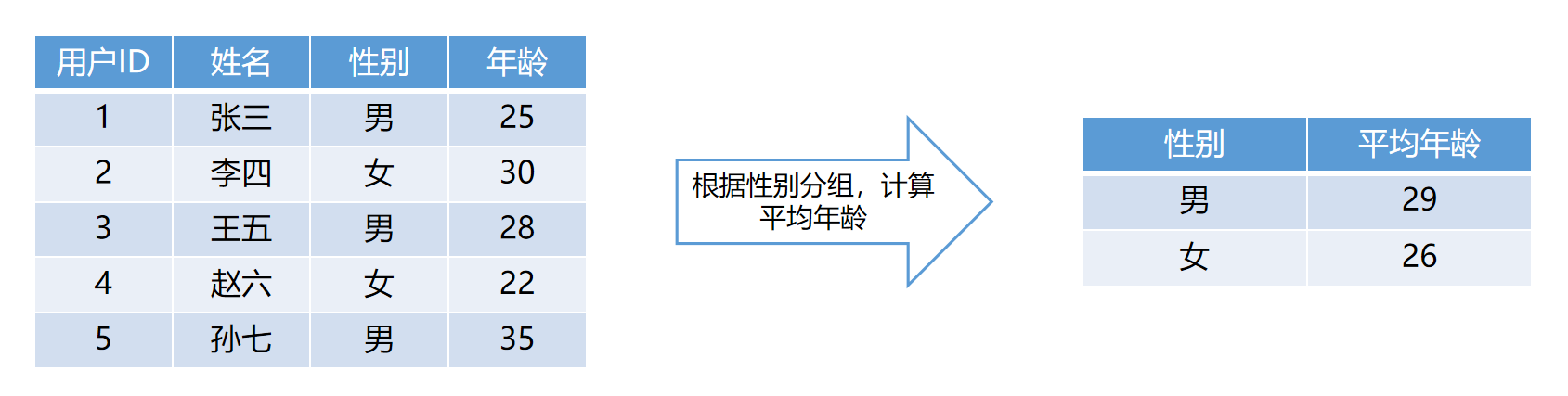
如下图:根据用户性别进行分组,然后计算每个分组的平均值,计算用户的平均年龄。
适用场景:统计各维度的汇总数据(如按地区统计订单数、按月份统计销售额等)
数据分组的核心关键字:GROUP BY(创建分组)、HAVING(过滤分组)
注意:分组需要配合聚合函数(COUNT、SUM、AVG、MAX、MIN),用于计算每组的统计值,不然分组意义不大。例如:
> select gender FROM `user` group by gender
gender|
------+
|
男 |
女 |
3 row(s) fetched.
实际上,我们可能需要计算平均年龄,如下:
> select gender, avg(age) as avg_gender FROM `user` group by gender
gender|avg_gender|
------+----------+
| 32.0000|
男 | 28.0000|
女 | 27.8000|
3 row(s) fetched.
创建分组
在 SQL 语言中,创建分组使用 group by 关键字,基本语法如下:
SELECT 分组字段, 聚合函数(字段)
FROM 表名
[WHERE 行过滤条件]
GROUP BY 分组字段;
注意:
(1)GROUP BY 后接1 个或多个分组字段,字段需与 SELECT 中 “非聚合字段” 一一对应,例如:
select gender,age from user group by gender,age;
如果 SELECT 中 “非聚合字段” 和分组字段不匹配,会抛出错误:
> select gender,name from user group by gender,age
SQL Error [1055] [42000]: Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'sql_demo.user.name'
which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
但是,允许分组字段不出现在 SELECT 中 “非聚合字段” ,例如:
> select gender from user group by gender,age
gender|
------+
|
男 |
男 |
男 |
男 |
女 |
女 |
女 |
女 |
女 |
10 row(s) fetched.
(2)聚合函数仅作用于分组后的 “每组内部” 的数据。例如:
> select gender, sum(age) as sum_age from user group by gender
gender|sum_age|
------+-------+
| 32|
男 | 112|
女 | 139|
3 row(s) fetched.
上面 SQL 语句中,sum() 函数仅仅作用域对应的分组,共三个分组,分别是性别为 ”男“、”女“ 和 NULL。
公共广告位-数据库
单字段分组
单字段分组顾名思义就是使用一个字段进行分组,例如统计不同性别的用户数量:
> SELECT
gender, -- 分组字段
COUNT(*) AS user_count -- 聚合函数:统计每组行数
FROM user
GROUP BY gender -- 基于 gender 进行分组
gender|user_count|
------+----------+
| 1|
男 | 4|
女 | 5|
3 row(s) fetched.
多字段分组
多字段分组即根据多个字段进行分组,如根据用户性别和年龄分组,如下:
> SELECT
gender, -- 第一个分组字段
age, -- 第二个分组字段
COUNT(*) AS user_count
FROM user
GROUP BY gender, age
gender|age|user_count|
------+---+----------+
| 32| 1|
男 | 24| 1|
男 | 25| 1|
男 | 28| 1|
男 | 35| 1|
女 | 22| 1|
女 | 27| 1|
女 | 29| 1|
女 | 30| 1|
女 | 31| 1|
10 row(s) fetched.
分组的常见问题
问题 1:字段歧义(Column 'xxx' in group statement is ambiguous)
多表关联时,若分组字段在多个表中重名,必须指定表名 / 别名,例如:关联 user 表和 order 表,统计用户的订单数量,此时 user_id 字段在 user 表和 order 表均存在
-- 错误示例:user_id 来源不明确
> select user_id, count(*) order_count from user u
join `order` o on o.user_id=u.user_id
group by user_id
SQL Error [1052] [23000]: Column 'user_id' in field list is ambiguous
-- 正确示例:指定表别名,u.user_id 指定采用 user 表中的 user_id 字段进行分组
> select u.user_id, count(*) order_count from user u
join `order` o on o.user_id=u.user_id
group by u.user_id
user_id|order_count|
-------+-----------+
1| 3|
2| 3|
3| 4|
4| 3|
5| 4|
6| 3|
6 row(s) fetched.
注意,后续章节将介绍多表关联。
问题 2:SELECT 字段与 GROUP BY 不匹配
非聚合字段必须出现在GROUP BY中,否则会报错。例如:
-- 错误示例:SELECT中的age未在GROUP BY中,且非聚合字段
> SELECT gender, age, COUNT(*) FROM user GROUP BY gender
SQL Error [1055] [42000]: Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'sql_demo.user.age'
which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
-- 正确示例:要么将age加入GROUP BY,要么对age使用聚合函数
> SELECT gender, AVG(age) AS avg_age, COUNT(*) FROM user GROUP BY gender
gender|avg_age|COUNT(*)|
------+-------+--------+
|32.0000| 1|
男 |28.0000| 4|
女 |27.8000| 5|
3 row(s) fetched.
过滤分组(HAVING 关键字)
WHERE 用于过滤行,HAVING 用于过滤分组,注意:只有满足 HAVING 条件的分组才会被保留。
WHERE & HAVING
下面是 WHERE 和 HAVING 关键字的区别:
关键字 | 作用对象 | 执行时机 | 能否使用聚合函数 |
WHERE | 行 | 分组前过滤 | 不能 |
HAVING | 分组 | 分组后过滤 | 能 |
基础用法
根据性别 ”gender“ 进行分组,过滤掉分组中用户数小于 2 的分组。如下:
-- 未过滤的分组数据
> select gender, count(*) as count_user from user
group by gender
gender|count_user|
------+----------+
| 1|
男 | 4|
女 | 5|
3 row(s) fetched.
-- 过滤分组用户数小于2的分组
> select gender, count(*) as count_user from user
group by gender having count_user>=2
gender|count_user|
------+----------+
男 | 4|
女 | 5|
2 row(s) fetched.
组合使用 WHERE + HAVING
需求:统计 “年龄≥28 岁” 的用户中,用户数≥2 的部门
> select gender, count(*) as count_user from user
where gender is not null -- 先过滤:仅保留性别不为NULL的用户
group by gender having count_user>=2 -- 再过滤:仅保留用户数≥的用户
gender|count_user|
------+----------+
男 | 4|
女 | 5|
2 row(s) fetched.
分组和排序(GROUP BY + ORDER BY)
GROUP BY 仅负责分组,不保证分组结果的顺序。如果需对分组结果排序,必须使用 ORDER BY 子句。
基础用法
按 “用户数降序” 统计用户的数量,如下:
> select gender, count(*) as count_user from user
where gender is not null -- 先过滤:仅保留性别不为NULL的用户
group by gender having count_user>=2 -- 再过滤:仅保留用户数≥的用户
order by count_user desc -- 根据用户数降序排序
gender|count_user|
------+----------+
女 | 5|
男 | 4|
2 row(s) fetched.
多字段排序
先按性别升序,再按用户数降序统计用户,例如:
> select gender, count(*) as count_user from user
where gender is not null -- 先过滤:仅保留性别不为NULL的用户
group by gender having count_user>=2 -- 再过滤:仅保留用户数≥的用户
order by gender asc, count_user desc
gender|count_user|
------+----------+
男 | 4|
女 | 5|
2 row(s) fetched.
注意:GROUP BY 与 ORDER BY 的坑
(1)不要依赖 GROUP BY 的默认排序:不同数据库(MySQL、PostgreSQL、Oracle)的分组默认顺序可能不同;
(2)排序字段可使用别名:ORDER BY user_count 等价于 ORDER BY COUNT(*),推荐用别名提升可读性。
SELECT 子句的执行顺序
写 SQL 时我们习惯按 SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY 书写,但数据库的执行顺序完全不同,这是理解分组查询的关键。官方执行顺序
(1)FROM:确定查询的基础表;
(2)WHERE:过滤表中的行;
(3)GROUP BY:对过滤后的行分组;
(4)HAVING:过滤分组后的结果;
(5)SELECT:筛选最终要返回的字段(包括聚合计算);
(6)ORDER BY:对最终结果排序;
(7)LIMIT:限制返回的行数(可选);
示例验证:
> SELECT gender AS dept, -- 步骤5:别名生效
COUNT(*) AS user_count
FROM user -- 步骤1
WHERE age > 20 -- 步骤2
GROUP BY gender -- 步骤3
HAVING user_count >= 2 -- 步骤4:注意!这里不能用别名(部分数据库支持,但不推荐)
ORDER BY user_count DESC
dept|user_count|
----+----------+
女 | 5|
男 | 4|
2 row(s) fetched.
注意,HAVING 执行在 SELECT 之前,因此HAVING 中不能直接使用 SELECT 的字段别名(MySQL 例外,但不推荐),应使用原始聚合函数:
-- 正确写法
HAVING COUNT(*) ≥ 2;
-- 错误写法(部分数据库报错)
HAVING user_count ≥ 2;
完整 SQL 语句如下:
> SELECT gender AS dept, -- 步骤5:别名生效
COUNT(*) AS user_count
FROM user -- 步骤1
WHERE age > 20 -- 步骤2
GROUP BY gender -- 步骤3
HAVING COUNT(*) >= 2 -- 步骤4:注意!这里不能用别名(部分数据库支持,但不推荐)
ORDER BY user_count DESC
dept|user_count|
----+----------+
女 | 5|
男 | 4|
2 row(s) fetched.

 川公网安备51010802032098
川公网安备51010802032098